 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation of Deep Convolutional Maxout Neural Network in Speech Recognition
Paper and Code
May 04, 2021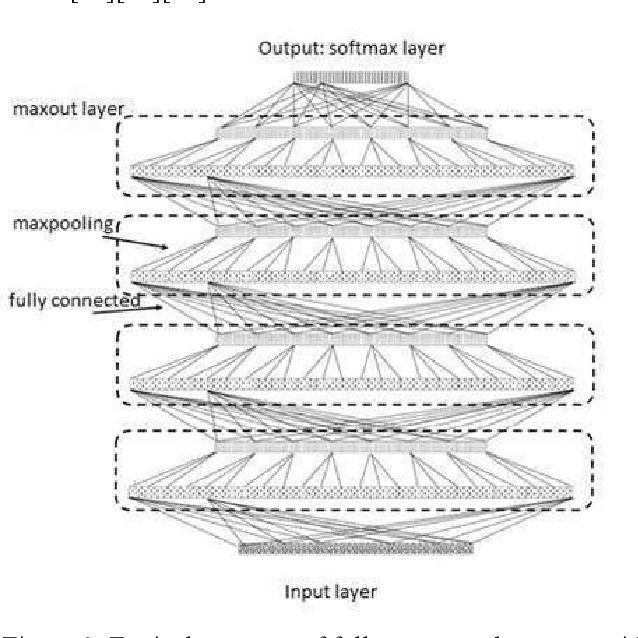
In this paper, various structures and methods of Deep Artificial Neural Networks (DNN) will be evaluated and compared for the purpose of continuous Persian speech recognition. One of the first models of neural networks used in speech recognition applications were fully connected Neural Networks (FCNNs) and, consequently, Deep Neural Networks (DNNs). Although these models have better performance compared to GMM / HMM models, they do not have the proper structure to model local speech information. Convolutional Neural Network (CNN) is a good option for modeling the local structure of biological signals, including speech signals. Another issue that Deep Artificial Neural Networks face, is the convergence of networks on training data. The main inhibitor of convergence is the presence of local minima in the process of training. Deep Neural Network Pre-training methods, despite a large amount of computing, are powerful tools for crossing the local minima. But the use of appropriate neuronal models in the network structure seems to be a better solution to this problem. The Rectified Linear Unit neuronal model and the Maxout model are the most suitable neuronal models presented to this date. Several experiments were carried out to evaluate the performance of the methods and structures mentioned. After verifying the proper functioning of these methods, a combination of all models was implemented on FARSDAT speech database for continuous speech recognition. The results obtained from the experiments show that the combined model (CMDNN) improves the performance of ANNs in speech recognition versus the pre-trained fully connected NNs with sigmoid neurons by about 3%.