 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable retinal image synthesis using conditional StyleGAN and latent space manipulation for improved diagnosis and grading of diabetic retinopathy
Sep 11, 2024



Diabetic retinopathy (DR) is a consequence of diabetes mellitus characterized by vascular damage within the retinal tissue. Timely detection is paramount to mitigate the risk of vision loss. However, training robust grading models is hindered by a shortage of annotated data, particularly for severe cases. This paper proposes a framework for controllably generating high-fidelity and diverse DR fundus images, thereby improving classifier performance in DR grading and detection. We achieve comprehensive control over DR severity and visual features (optic disc, vessel structure, lesion areas) within generated images solely through a conditional StyleGAN, eliminating the need for feature masks or auxiliary networks. Specifically, leveraging the SeFa algorithm to identify meaningful semantics within the latent space, we manipulate the DR images generated conditionally on grades, further enhancing the dataset diversity. Additionally, we propose a novel, effective SeFa-based data augmentation strategy, helping the classifier focus on discriminative regions while ignoring redundant features. Using this approach, a ResNet50 model trained for DR detection achieves 98.09% accuracy, 99.44% specificity, 99.45% precision, and an F1-score of 98.09%. Moreover, incorporating synthetic images generated by conditional StyleGAN into ResNet50 training for DR grading yields 83.33% accuracy, a quadratic kappa score of 87.64%, 95.67% specificity, and 72.24% precision. Extensive experiments conducted on the APTOS 2019 dataset demonstrate the exceptional realism of the generated images and the superior performance of our classifier compared to recent studies.
Time-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Sep 06, 2021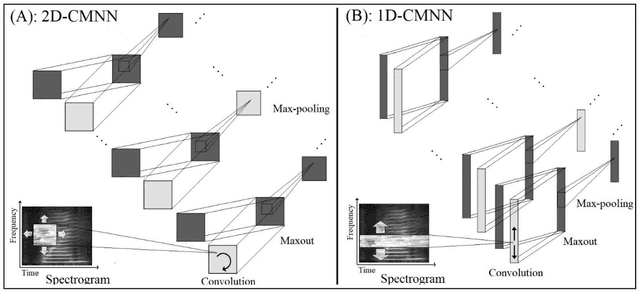
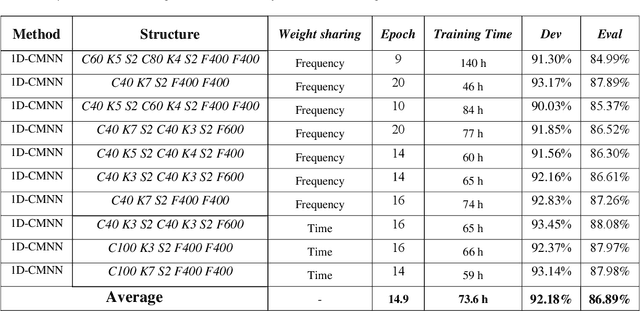
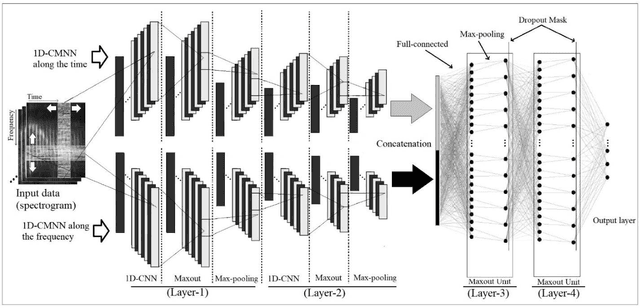
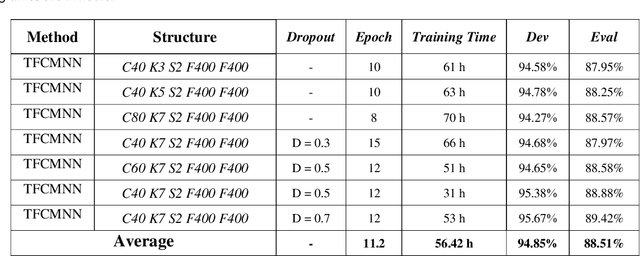
In this paper, a CNN-based structure for time-frequency localization of information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' spectrotemporal plasticity of some neurons in mammals' primary auditory cortex and midbrain makes localization facilities that improve recognition performance. As biosystems have inspired many man-maid systems because of their high efficiency and performance, in the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial or temporal immutability properties of methods such as TDNN, CNN, and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. We have presented a structure called Time-Frequency Convolutional Maxout Neural Network (TFCMNN) in which two parallel time-domain and frequency-domain 1D-CMNN are used. These two blocks are applied simultaneously but independently to the spectrogram, and then their output is concatenated and applied jointly to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as Dropout, maxout, and weight normalization. Two sets of experiments were designed and implemented on the Persian FARSDAT speech dataset to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. Therefore, as proven in other sources, we can say that time-frequency localization in ASR systems increases system accuracy and speeds up the training process.
Performance Evaluation of Deep Convolutional Maxout Neural Network in Speech Recognition
May 04, 2021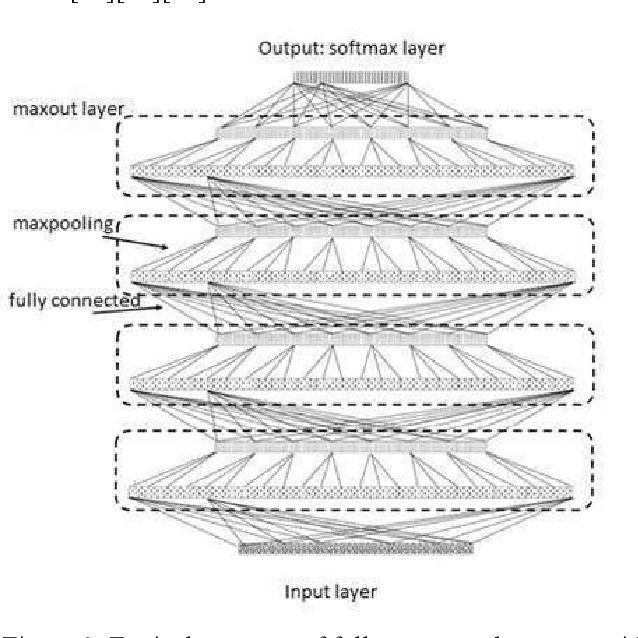
In this paper, various structures and methods of Deep Artificial Neural Networks (DNN) will be evaluated and compared for the purpose of continuous Persian speech recognition. One of the first models of neural networks used in speech recognition applications were fully connected Neural Networks (FCNNs) and, consequently, Deep Neural Networks (DNNs). Although these models have better performance compared to GMM / HMM models, they do not have the proper structure to model local speech information. Convolutional Neural Network (CNN) is a good option for modeling the local structure of biological signals, including speech signals. Another issue that Deep Artificial Neural Networks face, is the convergence of networks on training data. The main inhibitor of convergence is the presence of local minima in the process of training. Deep Neural Network Pre-training methods, despite a large amount of computing, are powerful tools for crossing the local minima. But the use of appropriate neuronal models in the network structure seems to be a better solution to this problem. The Rectified Linear Unit neuronal model and the Maxout model are the most suitable neuronal models presented to this date. Several experiments were carried out to evaluate the performance of the methods and structures mentioned. After verifying the proper functioning of these methods, a combination of all models was implemented on FARSDAT speech database for continuous speech recognition. The results obtained from the experiments show that the combined model (CMDNN) improves the performance of ANNs in speech recognition versus the pre-trained fully connected NNs with sigmoid neurons by about 3%.
* 6 pages, 2 figures, conference paper submitted to 2018 25th National and 3rd International Iranian Conference on Biomedical Engineering (ICBME)