 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTime-Frequency Localization Using Deep Convolutional Maxout Neural Network in Persian Speech Recognition
Paper and Code
Sep 06, 2021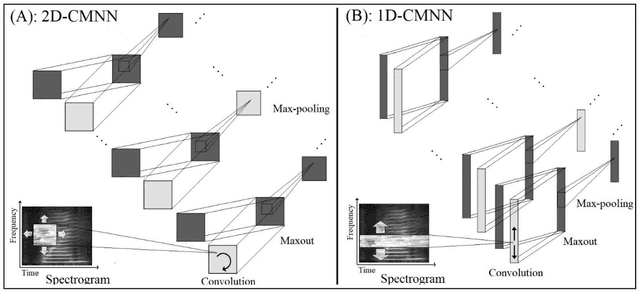
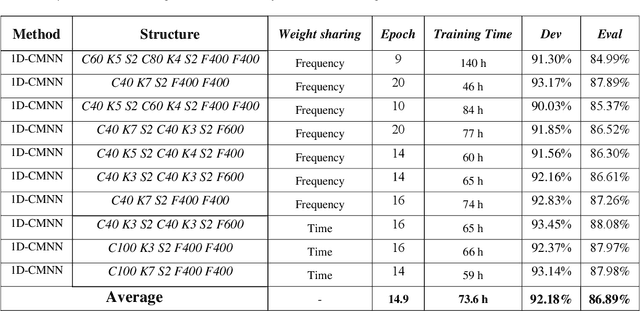
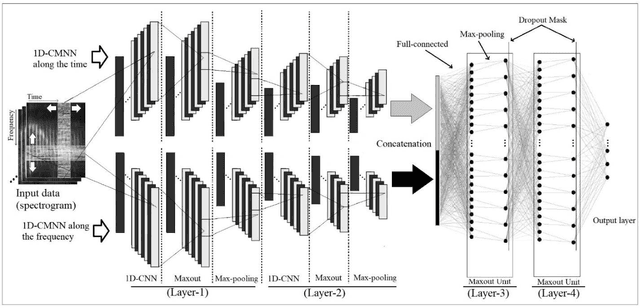
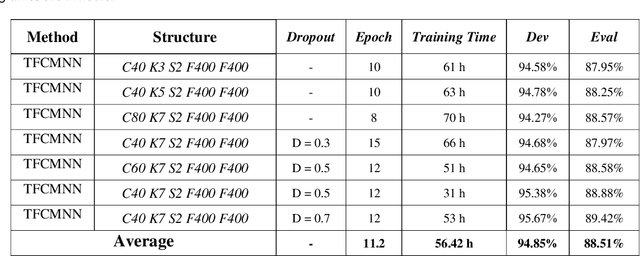
In this paper, a CNN-based structure for time-frequency localization of information in the ASR acoustic model is proposed for Persian speech recognition. Research has shown that the receptive fields' spectrotemporal plasticity of some neurons in mammals' primary auditory cortex and midbrain makes localization facilities that improve recognition performance. As biosystems have inspired many man-maid systems because of their high efficiency and performance, in the last few years, much work has been done to localize time-frequency information in ASR systems, which has used the spatial or temporal immutability properties of methods such as TDNN, CNN, and LSTM-RNN. However, most of these models have large parameter volumes and are challenging to train. We have presented a structure called Time-Frequency Convolutional Maxout Neural Network (TFCMNN) in which two parallel time-domain and frequency-domain 1D-CMNN are used. These two blocks are applied simultaneously but independently to the spectrogram, and then their output is concatenated and applied jointly to a fully connected Maxout network for classification. To improve the performance of this structure, we have used newly developed methods and models such as Dropout, maxout, and weight normalization. Two sets of experiments were designed and implemented on the Persian FARSDAT speech dataset to evaluate the performance of this model compared to conventional 1D-CMNN models. According to the experimental results, the average recognition score of TFCMNN models is about 1.6% higher than the average of conventional models. In addition, the average training time of the TFCMNN models is about 17 hours lower than the average training time of traditional models. Therefore, as proven in other sources, we can say that time-frequency localization in ASR systems increases system accuracy and speeds up the training process.