 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomap: Towards Ergonomic Automated Parallelism for ML Models
Dec 06, 2021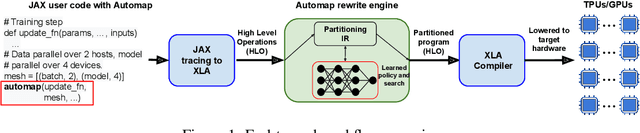
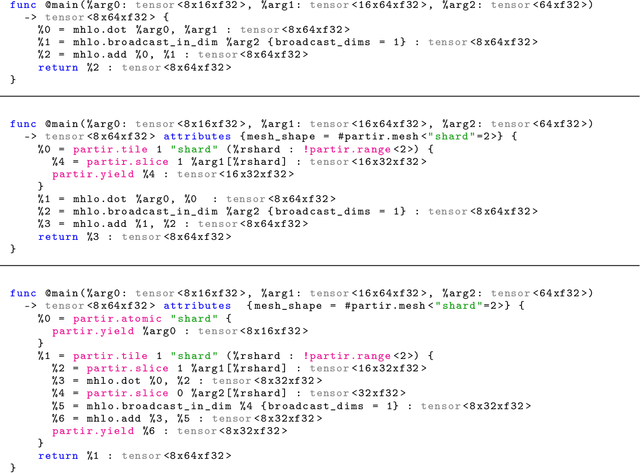


The rapid rise in demand for training large neural network architectures has brought into focus the need for partitioning strategies, for example by using data, model, or pipeline parallelism. Implementing these methods is increasingly supported through program primitives, but identifying efficient partitioning strategies requires expensive experimentation and expertise. We present the prototype of an automated partitioner that seamlessly integrates into existing compilers and existing user workflows. Our partitioner enables SPMD-style parallelism that encompasses data parallelism and parameter/activation sharding. Through a combination of inductive tactics and search in a platform-independent partitioning IR, automap can recover expert partitioning strategies such as Megatron sharding for transformer layers.
Local Search for Policy Iteration in Continuous Control
Oct 12, 2020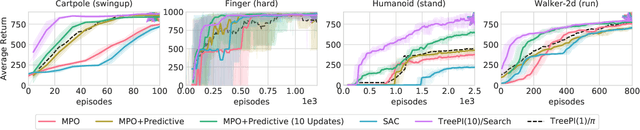
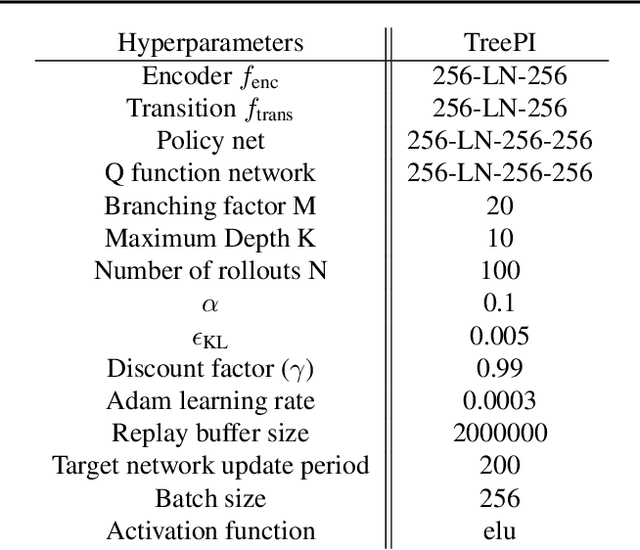
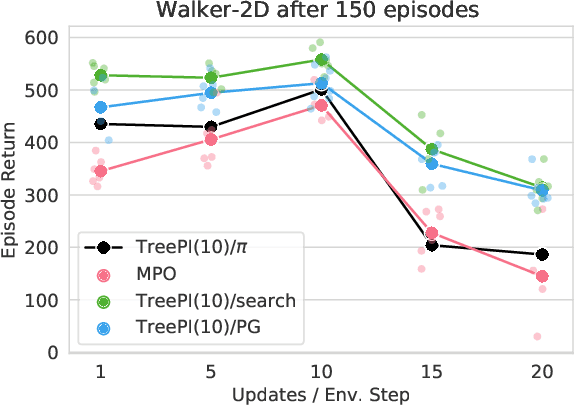

We present an algorithm for local, regularized, policy improvement in reinforcement learning (RL) that allows us to formulate model-based and model-free variants in a single framework. Our algorithm can be interpreted as a natural extension of work on KL-regularized RL and introduces a form of tree search for continuous action spaces. We demonstrate that additional computation spent on model-based policy improvement during learning can improve data efficiency, and confirm that model-based policy improvement during action selection can also be beneficial. Quantitatively, our algorithm improves data efficiency on several continuous control benchmarks (when a model is learned in parallel), and it provides significant improvements in wall-clock time in high-dimensional domains (when a ground truth model is available). The unified framework also helps us to better understand the space of model-based and model-free algorithms. In particular, we demonstrate that some benefits attributed to model-based RL can be obtained without a model, simply by utilizing more computation.
V-MPO: On-Policy Maximum a Posteriori Policy Optimization for Discrete and Continuous Control
Sep 26, 2019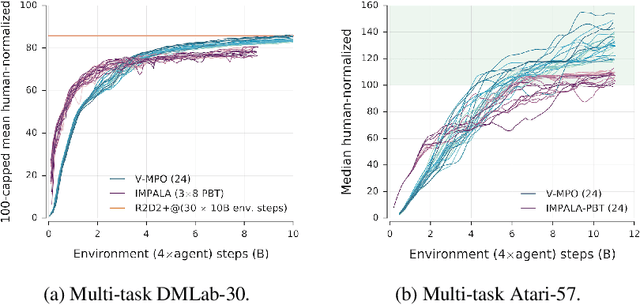
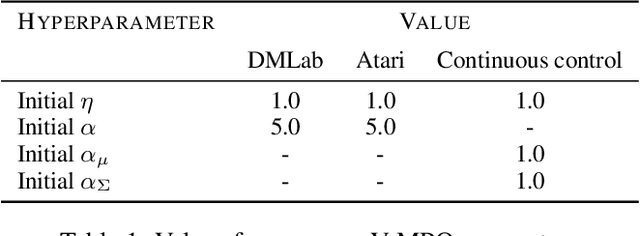
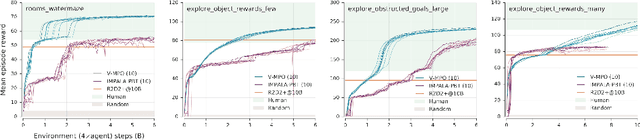

Some of the most successful applications of deep reinforcement learning to challenging domains in discrete and continuous control have used policy gradient methods in the on-policy setting. However, policy gradients can suffer from large variance that may limit performance, and in practice require carefully tuned entropy regularization to prevent policy collapse. As an alternative to policy gradient algorithms, we introduce V-MPO, an on-policy adaptation of Maximum a Posteriori Policy Optimization (MPO) that performs policy iteration based on a learned state-value function. We show that V-MPO surpasses previously reported scores for both the Atari-57 and DMLab-30 benchmark suites in the multi-task setting, and does so reliably without importance weighting, entropy regularization, or population-based tuning of hyperparameters. On individual DMLab and Atari levels, the proposed algorithm can achieve scores that are substantially higher than has previously been reported. V-MPO is also applicable to problems with high-dimensional, continuous action spaces, which we demonstrate in the context of learning to control simulated humanoids with 22 degrees of freedom from full state observations and 56 degrees of freedom from pixel observations, as well as example OpenAI Gym tasks where V-MPO achieves substantially higher asymptotic scores than previously reported.
TF-Replicator: Distributed Machine Learning for Researchers
Feb 01, 2019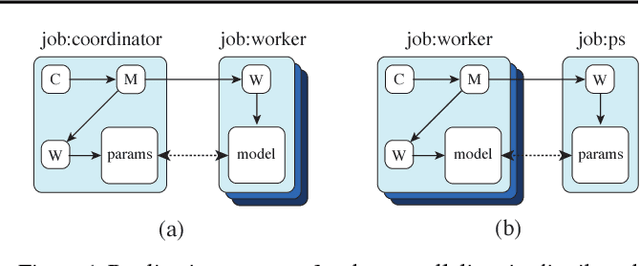

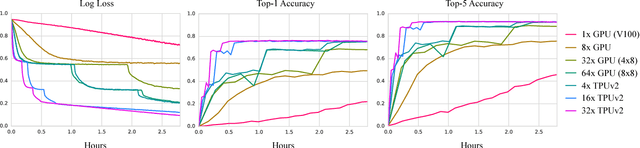
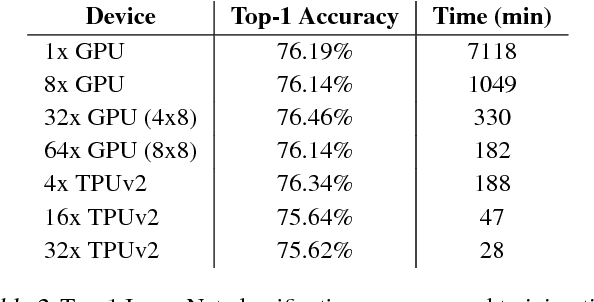
We describe TF-Replicator, a framework for distributed machine learning designed for DeepMind researchers and implemented as an abstraction over TensorFlow. TF-Replicator simplifies writing data-parallel and model-parallel research code. The same models can be effortlessly deployed to different cluster architectures (i.e. one or many machines containing CPUs, GPUs or TPU accelerators) using synchronous or asynchronous training regimes. To demonstrate the generality and scalability of TF-Replicator, we implement and benchmark three very different models: (1) A ResNet-50 for ImageNet classification, (2) a SN-GAN for class-conditional ImageNet image generation, and (3) a D4PG reinforcement learning agent for continuous control. Our results show strong scalability performance without demanding any distributed systems expertise of the user. The TF-Replicator programming model will be open-sourced as part of TensorFlow 2.0 (see https://github.com/tensorflow/community/pull/25).
Relative Entropy Regularized Policy Iteration
Dec 05, 2018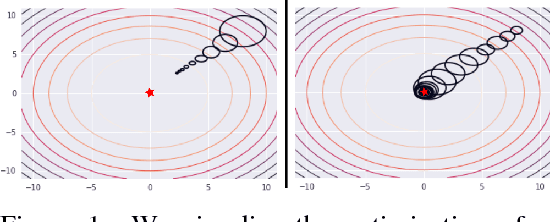

We present an off-policy actor-critic algorithm for Reinforcement Learning (RL) that combines ideas from gradient-free optimization via stochastic search with learned action-value function. The result is a simple procedure consisting of three steps: i) policy evaluation by estimating a parametric action-value function; ii) policy improvement via the estimation of a local non-parametric policy; and iii) generalization by fitting a parametric policy. Each step can be implemented in different ways, giving rise to several algorithm variants. Our algorithm draws on connections to existing literature on black-box optimization and 'RL as an inference' and it can be seen either as an extension of the Maximum a Posteriori Policy Optimisation algorithm (MPO) [Abdolmaleki et al., 2018a], or as an extension of Trust Region Covariance Matrix Adaptation Evolutionary Strategy (CMA-ES) [Abdolmaleki et al., 2017b; Hansen et al., 1997] to a policy iteration scheme. Our comparison on 31 continuous control tasks from parkour suite [Heess et al., 2017], DeepMind control suite [Tassa et al., 2018] and OpenAI Gym [Brockman et al., 2016] with diverse properties, limited amount of compute and a single set of hyperparameters, demonstrate the effectiveness of our method and the state of art results. Videos, summarizing results, can be found at goo.gl/HtvJKR .
Parallel WaveNet: Fast High-Fidelity Speech Synthesis
Nov 28, 2017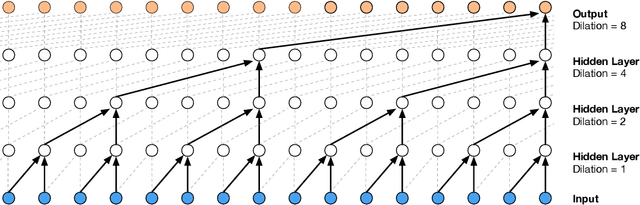
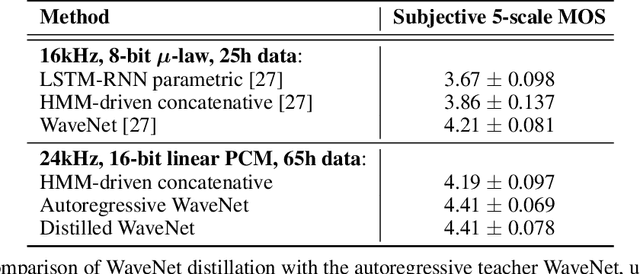
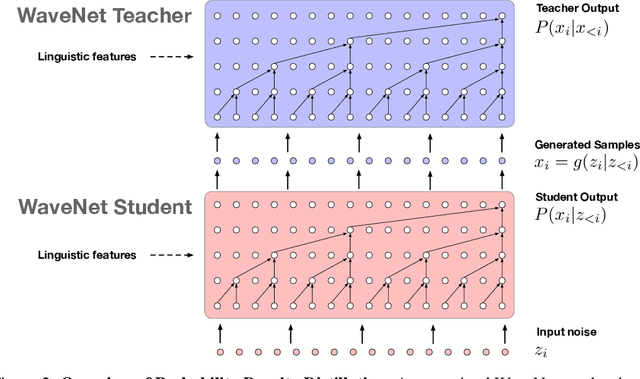
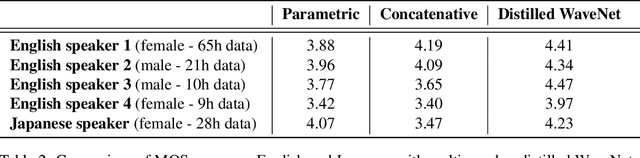
The recently-developed WaveNet architecture is the current state of the art in realistic speech synthesis, consistently rated as more natural sounding for many different languages than any previous system. However, because WaveNet relies on sequential generation of one audio sample at a time, it is poorly suited to today's massively parallel computers, and therefore hard to deploy in a real-time production setting. This paper introduces Probability Density Distillation, a new method for training a parallel feed-forward network from a trained WaveNet with no significant difference in quality. The resulting system is capable of generating high-fidelity speech samples at more than 20 times faster than real-time, and is deployed online by Google Assistant, including serving multiple English and Japanese voices.
Parallel Multiscale Autoregressive Density Estimation
Mar 10, 2017
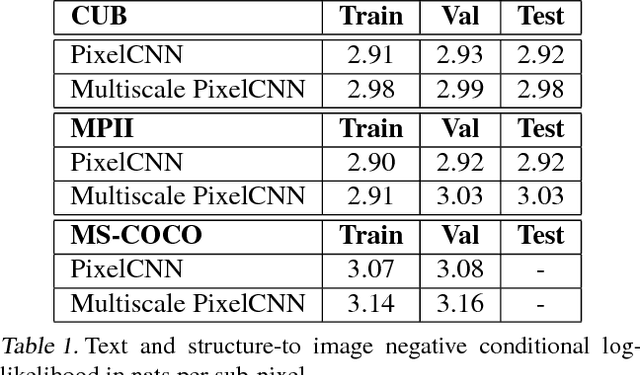
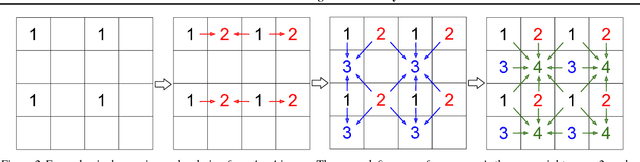
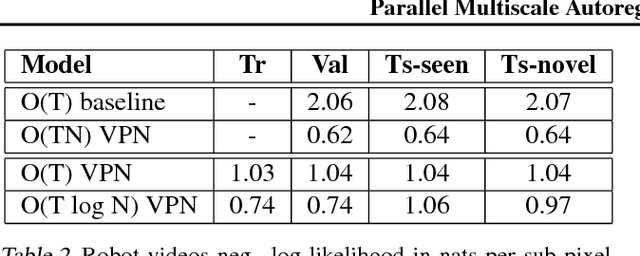
PixelCNN achieves state-of-the-art results in density estimation for natural images. Although training is fast, inference is costly, requiring one network evaluation per pixel; O(N) for N pixels. This can be sped up by caching activations, but still involves generating each pixel sequentially. In this work, we propose a parallelized PixelCNN that allows more efficient inference by modeling certain pixel groups as conditionally independent. Our new PixelCNN model achieves competitive density estimation and orders of magnitude speedup - O(log N) sampling instead of O(N) - enabling the practical generation of 512x512 images. We evaluate the model on class-conditional image generation, text-to-image synthesis, and action-conditional video generation, showing that our model achieves the best results among non-pixel-autoregressive density models that allow efficient sampling.