 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Single Object Tracking
Papers and Code
UniStateDLO: Unified Generative State Estimation and Tracking of Deformable Linear Objects Under Occlusion for Constrained Manipulation
Dec 19, 2025Perception of deformable linear objects (DLOs), such as cables, ropes, and wires, is the cornerstone for successful downstream manipulation. Although vision-based methods have been extensively explored, they remain highly vulnerable to occlusions that commonly arise in constrained manipulation environments due to surrounding obstacles, large and varying deformations, and limited viewpoints. Moreover, the high dimensionality of the state space, the lack of distinctive visual features, and the presence of sensor noises further compound the challenges of reliable DLO perception. To address these open issues, this paper presents UniStateDLO, the first complete DLO perception pipeline with deep-learning methods that achieves robust performance under severe occlusion, covering both single-frame state estimation and cross-frame state tracking from partial point clouds. Both tasks are formulated as conditional generative problems, leveraging the strong capability of diffusion models to capture the complex mapping between highly partial observations and high-dimensional DLO states. UniStateDLO effectively handles a wide range of occlusion patterns, including initial occlusion, self-occlusion, and occlusion caused by multiple objects. In addition, it exhibits strong data efficiency as the entire network is trained solely on a large-scale synthetic dataset, enabling zero-shot sim-to-real generalization without any real-world training data. Comprehensive simulation and real-world experiments demonstrate that UniStateDLO outperforms all state-of-the-art baselines in both estimation and tracking, producing globally smooth yet locally precise DLO state predictions in real time, even under substantial occlusions. Its integration as the front-end module in a closed-loop DLO manipulation system further demonstrates its ability to support stable feedback control in complex, constrained 3-D environments.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Nov 06, 2025Building Behavioral Foundation Models (BFMs) for humanoid robots has the potential to unify diverse control tasks under a single, promptable generalist policy. However, existing approaches are either exclusively deployed on simulated humanoid characters, or specialized to specific tasks such as tracking. We propose BFM-Zero, a framework that learns an effective shared latent representation that embeds motions, goals, and rewards into a common space, enabling a single policy to be prompted for multiple downstream tasks without retraining. This well-structured latent space in BFM-Zero enables versatile and robust whole-body skills on a Unitree G1 humanoid in the real world, via diverse inference methods, including zero-shot motion tracking, goal reaching, and reward optimization, and few-shot optimization-based adaptation. Unlike prior on-policy reinforcement learning (RL) frameworks, BFM-Zero builds upon recent advancements in unsupervised RL and Forward-Backward (FB) models, which offer an objective-centric, explainable, and smooth latent representation of whole-body motions. We further extend BFM-Zero with critical reward shaping, domain randomization, and history-dependent asymmetric learning to bridge the sim-to-real gap. Those key design choices are quantitatively ablated in simulation. A first-of-its-kind model, BFM-Zero establishes a step toward scalable, promptable behavioral foundation models for whole-body humanoid control.
Constraint-Preserving Data Generation for Visuomotor Policy Learning
Aug 05, 2025



Large-scale demonstration data has powered key breakthroughs in robot manipulation, but collecting that data remains costly and time-consuming. We present Constraint-Preserving Data Generation (CP-Gen), a method that uses a single expert trajectory to generate robot demonstrations containing novel object geometries and poses. These generated demonstrations are used to train closed-loop visuomotor policies that transfer zero-shot to the real world and generalize across variations in object geometries and poses. Similar to prior work using pose variations for data generation, CP-Gen first decomposes expert demonstrations into free-space motions and robot skills. But unlike those works, we achieve geometry-aware data generation by formulating robot skills as keypoint-trajectory constraints: keypoints on the robot or grasped object must track a reference trajectory defined relative to a task-relevant object. To generate a new demonstration, CP-Gen samples pose and geometry transforms for each task-relevant object, then applies these transforms to the object and its associated keypoints or keypoint trajectories. We optimize robot joint configurations so that the keypoints on the robot or grasped object track the transformed keypoint trajectory, and then motion plan a collision-free path to the first optimized joint configuration. Experiments on 16 simulation tasks and four real-world tasks, featuring multi-stage, non-prehensile and tight-tolerance manipulation, show that policies trained using CP-Gen achieve an average success rate of 77%, outperforming the best baseline that achieves an average of 50%.
SAM2MOT: A Novel Paradigm of Multi-Object Tracking by Segmentation
Apr 06, 2025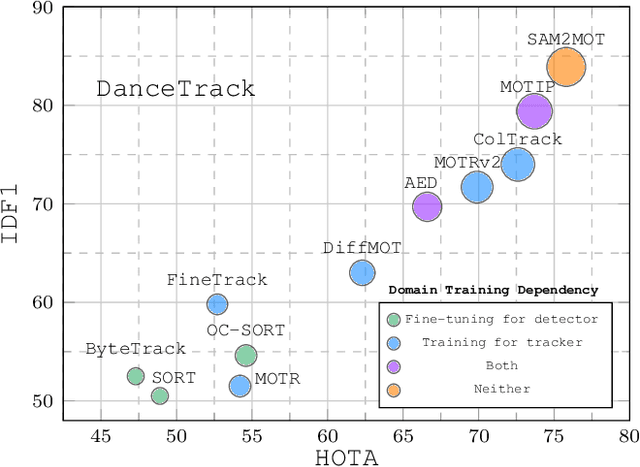
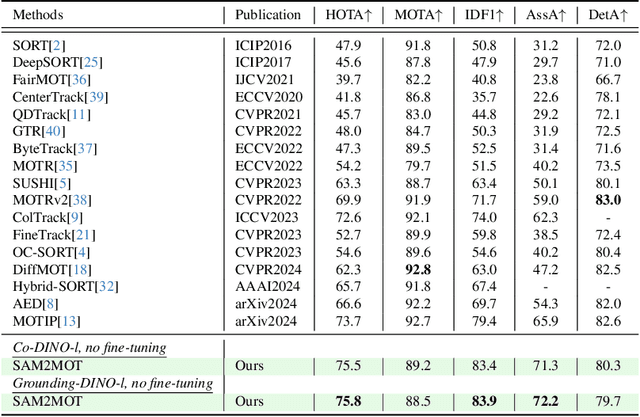
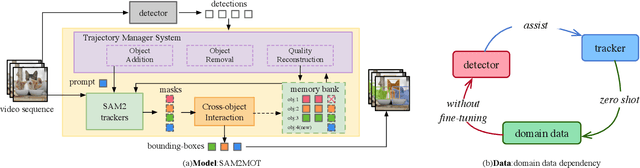
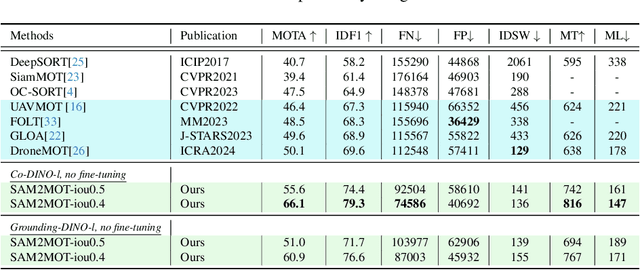
Segment Anything 2 (SAM2) enables robust single-object tracking using segmentation. To extend this to multi-object tracking (MOT), we propose SAM2MOT, introducing a novel Tracking by Segmentation paradigm. Unlike Tracking by Detection or Tracking by Query, SAM2MOT directly generates tracking boxes from segmentation masks, reducing reliance on detection accuracy. SAM2MOT has two key advantages: zero-shot generalization, allowing it to work across datasets without fine-tuning, and strong object association, inherited from SAM2. To further improve performance, we integrate a trajectory manager system for precise object addition and removal, and a cross-object interaction module to handle occlusions. Experiments on DanceTrack, UAVDT, and BDD100K show state-of-the-art results. Notably, SAM2MOT outperforms existing methods on DanceTrack by +2.1 HOTA and +4.5 IDF1, highlighting its effectiveness in MOT.
Seurat: From Moving Points to Depth
Apr 20, 2025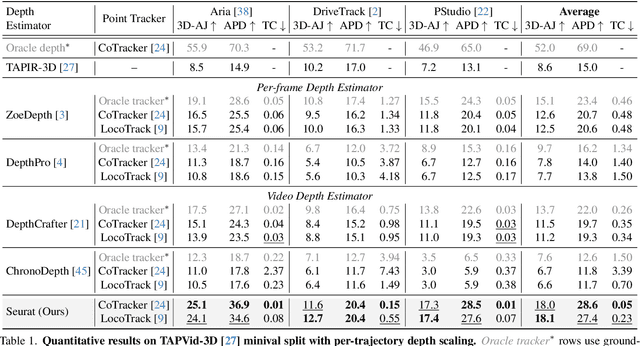
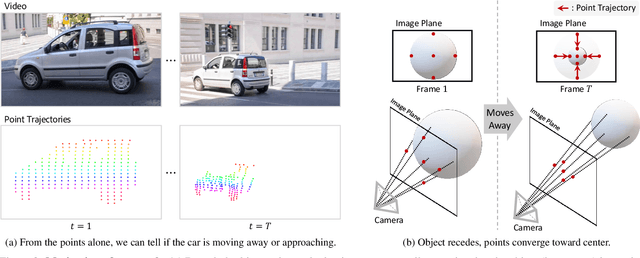
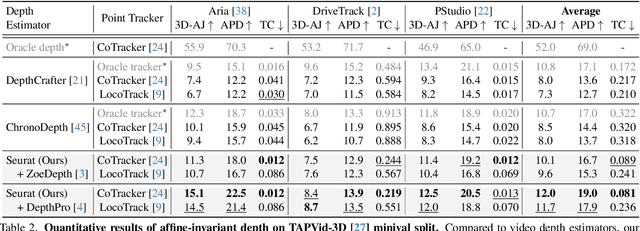
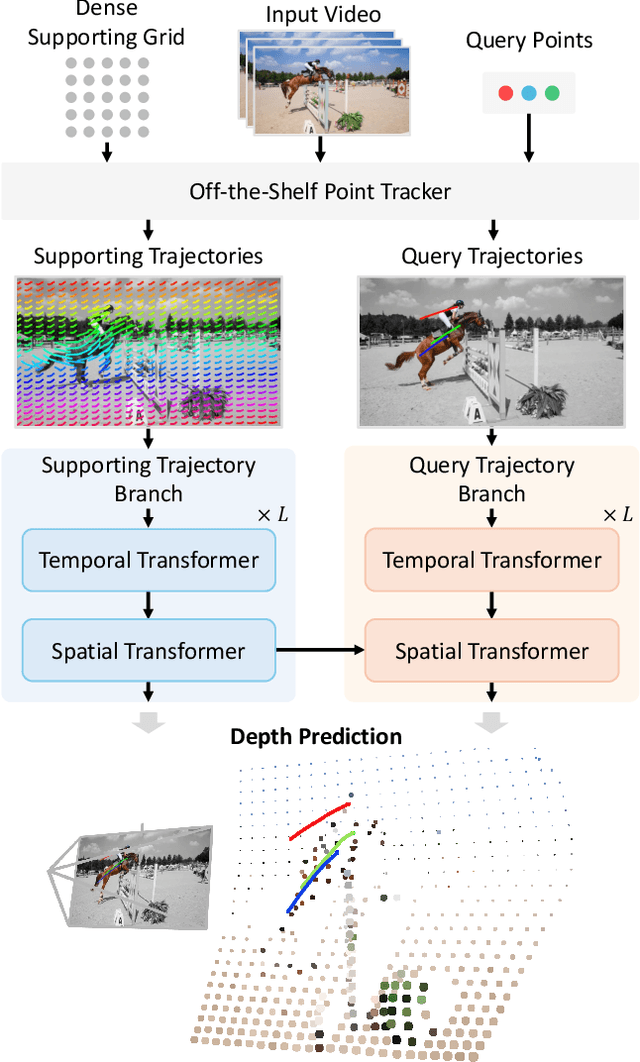
Accurate depth estimation from monocular videos remains challenging due to ambiguities inherent in single-view geometry, as crucial depth cues like stereopsis are absent. However, humans often perceive relative depth intuitively by observing variations in the size and spacing of objects as they move. Inspired by this, we propose a novel method that infers relative depth by examining the spatial relationships and temporal evolution of a set of tracked 2D trajectories. Specifically, we use off-the-shelf point tracking models to capture 2D trajectories. Then, our approach employs spatial and temporal transformers to process these trajectories and directly infer depth changes over time. Evaluated on the TAPVid-3D benchmark, our method demonstrates robust zero-shot performance, generalizing effectively from synthetic to real-world datasets. Results indicate that our approach achieves temporally smooth, high-accuracy depth predictions across diverse domains.
Track Anything Behind Everything: Zero-Shot Amodal Video Object Segmentation
Nov 28, 2024



We present Track Anything Behind Everything (TABE), a novel dataset, pipeline, and evaluation framework for zero-shot amodal completion from visible masks. Unlike existing methods that require pretrained class labels, our approach uses a single query mask from the first frame where the object is visible, enabling flexible, zero-shot inference. Our dataset, TABE-51 provides highly accurate ground truth amodal segmentation masks without the need for human estimation or 3D reconstruction. Our TABE pipeline is specifically designed to handle amodal completion, even in scenarios where objects are completely occluded. We also introduce a specialised evaluation framework that isolates amodal completion performance, free from the influence of traditional visual segmentation metrics.
HOLa: HoloLens Object Labeling
Dec 06, 2024In the context of medical Augmented Reality (AR) applications, object tracking is a key challenge and requires a significant amount of annotation masks. As segmentation foundation models like the Segment Anything Model (SAM) begin to emerge, zero-shot segmentation requires only minimal human participation obtaining high-quality object masks. We introduce a HoloLens-Object-Labeling (HOLa) Unity and Python application based on the SAM-Track algorithm that offers fully automatic single object annotation for HoloLens 2 while requiring minimal human participation. HOLa does not have to be adjusted to a specific image appearance and could thus alleviate AR research in any application field. We evaluate HOLa for different degrees of image complexity in open liver surgery and in medical phantom experiments. Using HOLa for image annotation can increase the labeling speed by more than 500 times while providing Dice scores between 0.875 and 0.982, which are comparable to human annotators. Our code is publicly available at: https://github.com/mschwimmbeck/HOLa
Vision-Based Detection of Uncooperative Targets and Components on Small Satellites
Aug 22, 2024Space debris and inactive satellites pose a threat to the safety and integrity of operational spacecraft and motivate the need for space situational awareness techniques. These uncooperative targets create a challenging tracking and detection problem due to a lack of prior knowledge of their features, trajectories, or even existence. Recent advancements in computer vision models can be used to improve upon existing methods for tracking such uncooperative targets to make them more robust and reliable to the wide-ranging nature of the target. This paper introduces an autonomous detection model designed to identify and monitor these objects using learning and computer vision. The autonomous detection method aims to identify and accurately track the uncooperative targets in varied circumstances, including different camera spectral sensitivities, lighting, and backgrounds. Our method adapts to the relative distance between the observing spacecraft and the target, and different detection strategies are adjusted based on distance. At larger distances, we utilize You Only Look Once (YOLOv8), a multitask Convolutional Neural Network (CNN), for zero-shot and domain-specific single-shot real time detection of the target. At shorter distances, we use knowledge distillation to combine visual foundation models with a lightweight fast segmentation CNN (Fast-SCNN) to segment the spacecraft components with low storage requirements and fast inference times, and to enable weight updates from earth and possible onboard training. Lastly, we test our method on a custom dataset simulating the unique conditions encountered in space, as well as a publicly-available dataset.
TrafficMOT: A Challenging Dataset for Multi-Object Tracking in Complex Traffic Scenarios
Nov 30, 2023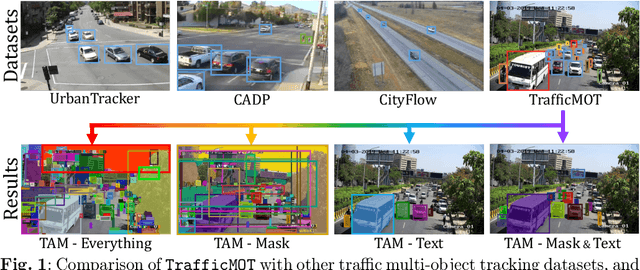
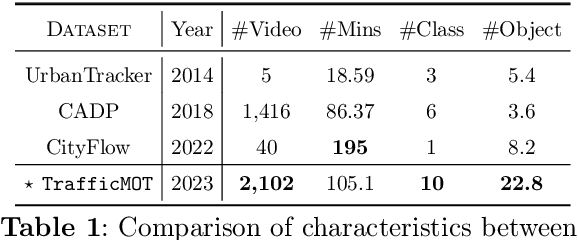

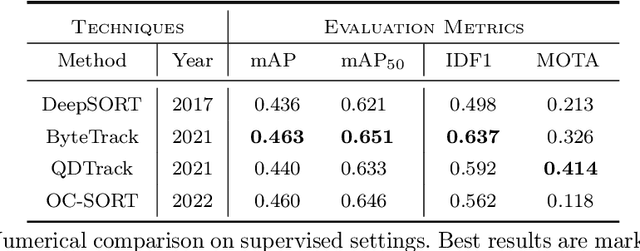
Multi-object tracking in traffic videos is a crucial research area, offering immense potential for enhancing traffic monitoring accuracy and promoting road safety measures through the utilisation of advanced machine learning algorithms. However, existing datasets for multi-object tracking in traffic videos often feature limited instances or focus on single classes, which cannot well simulate the challenges encountered in complex traffic scenarios. To address this gap, we introduce TrafficMOT, an extensive dataset designed to encompass diverse traffic situations with complex scenarios. To validate the complexity and challenges presented by TrafficMOT, we conducted comprehensive empirical studies using three different settings: fully-supervised, semi-supervised, and a recent powerful zero-shot foundation model Tracking Anything Model (TAM). The experimental results highlight the inherent complexity of this dataset, emphasising its value in driving advancements in the field of traffic monitoring and multi-object tracking.
Multi-Scale Memory Comparison for Zero-/Few-Shot Anomaly Detection
Aug 09, 2023Anomaly detection has gained considerable attention due to its broad range of applications, particularly in industrial defect detection. To address the challenges of data collection, researchers have introduced zero-/few-shot anomaly detection techniques that require minimal normal images for each category. However, complex industrial scenarios often involve multiple objects, presenting a significant challenge. In light of this, we propose a straightforward yet powerful multi-scale memory comparison framework for zero-/few-shot anomaly detection. Our approach employs a global memory bank to capture features across the entire image, while an individual memory bank focuses on simplified scenes containing a single object. The efficacy of our method is validated by its remarkable achievement of 4th place in the zero-shot track and 2nd place in the few-shot track of the Visual Anomaly and Novelty Detection (VAND) competition.