 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMusic Source Separation
Music source separation is the process of separating individual sound sources from a mixed audio signal.
Papers and Code
UNMIXX: Untangling Highly Correlated Singing Voices Mixtures
Jan 19, 2026We introduce UNMIXX, a novel framework for multiple singing voices separation (MSVS). While related to speech separation, MSVS faces unique challenges: data scarcity and the highly correlated nature of singing voices mixture. To address these issues, we propose UNMIXX with three key components: (1) musically informed mixing strategy to construct highly correlated, music-like mixtures, (2) cross-source attention that drives representations of two singers apart via reverse attention, and (3) magnitude penalty loss penalizing erroneously assigned interfering energy. UNMIXX not only addresses data scarcity by simulating realistic training data, but also excels at separating highly correlated mixtures through cross-source interactions at both the architectural and loss levels. Our extensive experiments demonstrate that UNMIXX greatly enhances performance, with SDRi gains exceeding 2.2 dB over prior work.
A Conditioned UNet for Music Source Separation
Dec 17, 2025In this paper we propose a conditioned UNet for Music Source Separation (MSS). MSS is generally performed by multi-output neural networks, typically UNets, with each output representing a particular stem from a predefined instrument vocabulary. In contrast, conditioned MSS networks accept an audio query related to a stem of interest alongside the signal from which that stem is to be extracted. Thus, a strict vocabulary is not required and this enables more realistic tasks in MSS. The potential of conditioned approaches for such tasks has been somewhat hidden due to a lack of suitable data, an issue recently addressed with the MoisesDb dataset. A recent method, Banquet, employs this dataset with promising results seen on larger vocabularies. Banquet uses Bandsplit RNN rather than a UNet and the authors state that UNets should not be suitable for conditioned MSS. We counter this argument and propose QSCNet, a novel conditioned UNet for MSS that integrates network conditioning elements in the Sparse Compressed Network for MSS. We find QSCNet to outperform Banquet by over 1dB SNR on a couple of MSS tasks, while using less than half the number of parameters.
SAM Audio: Segment Anything in Audio
Dec 19, 2025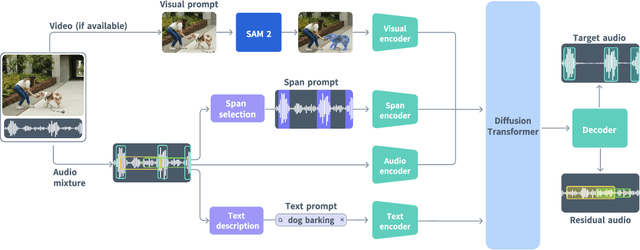

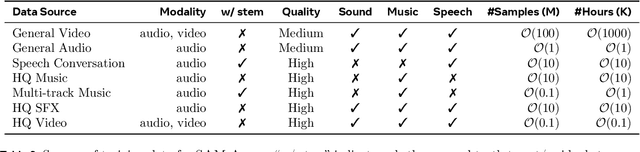
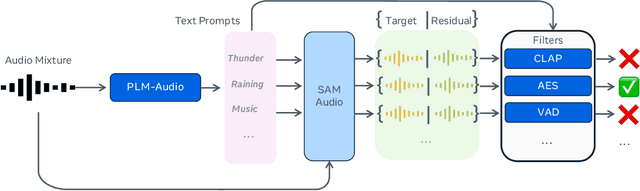
General audio source separation is a key capability for multimodal AI systems that can perceive and reason about sound. Despite substantial progress in recent years, existing separation models are either domain-specific, designed for fixed categories such as speech or music, or limited in controllability, supporting only a single prompting modality such as text. In this work, we present SAM Audio, a foundation model for general audio separation that unifies text, visual, and temporal span prompting within a single framework. Built on a diffusion transformer architecture, SAM Audio is trained with flow matching on large-scale audio data spanning speech, music, and general sounds, and can flexibly separate target sources described by language, visual masks, or temporal spans. The model achieves state-of-the-art performance across a diverse suite of benchmarks, including general sound, speech, music, and musical instrument separation in both in-the-wild and professionally produced audios, substantially outperforming prior general-purpose and specialized systems. Furthermore, we introduce a new real-world separation benchmark with human-labeled multimodal prompts and a reference-free evaluation model that correlates strongly with human judgment.
PolyLingua: Margin-based Inter-class Transformer for Robust Cross-domain Language Detection
Dec 10, 2025Language identification is a crucial first step in multilingual systems such as chatbots and virtual assistants, enabling linguistically and culturally accurate user experiences. Errors at this stage can cascade into downstream failures, setting a high bar for accuracy. Yet, existing language identification tools struggle with key cases -- such as music requests where the song title and user language differ. Open-source tools like LangDetect, FastText are fast but less accurate, while large language models, though effective, are often too costly for low-latency or low-resource settings. We introduce PolyLingua, a lightweight Transformer-based model for in-domain language detection and fine-grained language classification. It employs a two-level contrastive learning framework combining instance-level separation and class-level alignment with adaptive margins, yielding compact and well-separated embeddings even for closely related languages. Evaluated on two challenging datasets -- Amazon Massive (multilingual digital assistant utterances) and a Song dataset (music requests with frequent code-switching) -- PolyLingua achieves 99.25% F1 and 98.15% F1, respectively, surpassing Sonnet 3.5 while using 10x fewer parameters, making it ideal for compute- and latency-constrained environments.
ACMID: Automatic Curation of Musical Instrument Dataset for 7-Stem Music Source Separation
Oct 09, 2025Most current music source separation (MSS) methods rely on supervised learning, limited by training data quan- tity and quality. Though web-crawling can bring abundant data, platform-level track labeling often causes metadata mismatches, impeding accurate "audio-label" pair acquisi- tion. To address this, we present ACMID: a dataset for MSS generated through web crawling of extensive raw data, fol- lowed by automatic cleaning via an instrument classifier built on a pre-trained audio encoder that filters and aggregates clean segments of target instruments from the crawled tracks, resulting in the refined ACMID-Cleaned dataset. Leverag- ing abundant data, we expand the conventional classifica- tion from 4-stem (Vocal/Bass/Drums/Others) to 7-stem (Pi- ano/Drums/Bass/Acoustic Guitar/Electric Guitar/Strings/Wind- Brass), enabling high granularity MSS systems. Experiments on SOTA MSS model demonstrates two key results: (i) MSS model trained with ACMID-Cleaned achieved a 2.39dB improvement in SDR performance compared to that with ACMID-Uncleaned, demostrating the effectiveness of our data cleaning procedure; (ii) incorporating ACMID-Cleaned to training enhances MSS model's average performance by 1.16dB, confirming the value of our dataset. Our data crawl- ing code, cleaning model code and weights are available at: https://github.com/scottishfold0621/ACMID.
R2-SVC: Towards Real-World Robust and Expressive Zero-shot Singing Voice Conversion
Oct 23, 2025In real-world singing voice conversion (SVC) applications, environmental noise and the demand for expressive output pose significant challenges. Conventional methods, however, are typically designed without accounting for real deployment scenarios, as both training and inference usually rely on clean data. This mismatch hinders practical use, given the inevitable presence of diverse noise sources and artifacts from music separation. To tackle these issues, we propose R2-SVC, a robust and expressive SVC framework. First, we introduce simulation-based robustness enhancement through random fundamental frequency ($F_0$) perturbations and music separation artifact simulations (e.g., reverberation, echo), substantially improving performance under noisy conditions. Second, we enrich speaker representation using domain-specific singing data: alongside clean vocals, we incorporate DNSMOS-filtered separated vocals and public singing corpora, enabling the model to preserve speaker timbre while capturing singing style nuances. Third, we integrate the Neural Source-Filter (NSF) model to explicitly represent harmonic and noise components, enhancing the naturalness and controllability of converted singing. R2-SVC achieves state-of-the-art results on multiple SVC benchmarks under both clean and noisy conditions.
Source Separation for A Cappella Music
Sep 30, 2025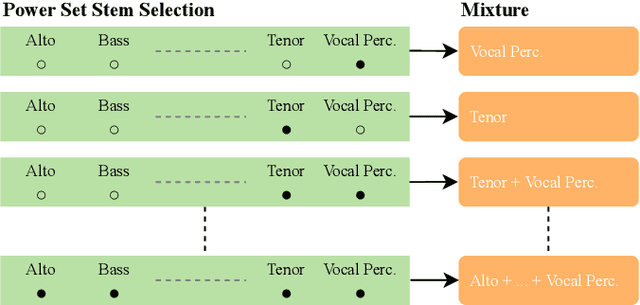
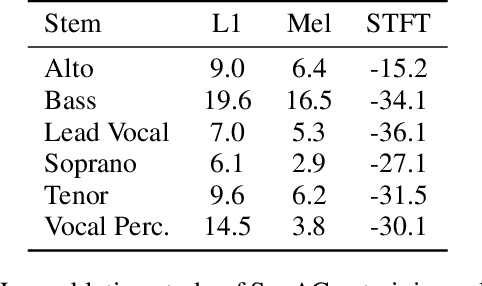
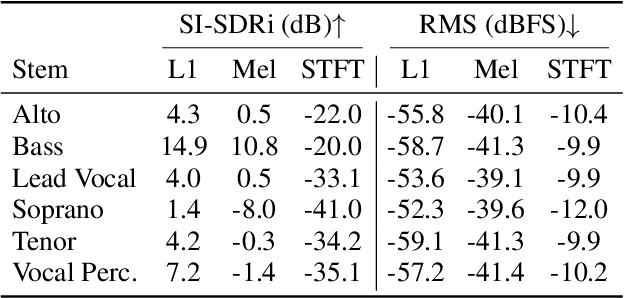
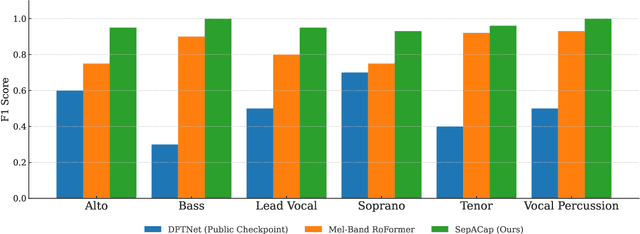
In this work, we study the task of multi-singer separation in a cappella music, where the number of active singers varies across mixtures. To address this, we use a power set-based data augmentation strategy that expands limited multi-singer datasets into exponentially more training samples. To separate singers, we introduce SepACap, an adaptation of SepReformer, a state-of-the-art speaker separation model architecture. We adapt the model with periodic activations and a composite loss function that remains effective when stems are silent, enabling robust detection and separation. Experiments on the JaCappella dataset demonstrate that our approach achieves state-of-the-art performance in both full-ensemble and subset singer separation scenarios, outperforming spectrogram-based baselines while generalizing to realistic mixtures with varying numbers of singers.
DeePAQ: A Perceptual Audio Quality Metric Based On Foundational Models and Weakly Supervised Learning
Oct 14, 2025This paper presents the Deep learning-based Perceptual Audio Quality metric (DeePAQ) for evaluating general audio quality. Our approach leverages metric learning together with the music foundation model MERT, guided by surrogate labels, to construct an embedding space that captures distortion intensity in general audio. To the best of our knowledge, DeePAQ is the first in the general audio quality domain to leverage weakly supervised labels and metric learning for fine-tuning a music foundation model with Low-Rank Adaptation (LoRA), a direction not yet explored by other state-of-the-art methods. We benchmark the proposed model against state-of-the-art objective audio quality metrics across listening tests spanning audio coding and source separation. Results show that our method surpasses existing metrics in detecting coding artifacts and generalizes well to unseen distortions such as source separation, highlighting its robustness and versatility.
TISDiSS: A Training-Time and Inference-Time Scalable Framework for Discriminative Source Separation
Sep 19, 2025Source separation is a fundamental task in speech, music, and audio processing, and it also provides cleaner and larger data for training generative models. However, improving separation performance in practice often depends on increasingly large networks, inflating training and deployment costs. Motivated by recent advances in inference-time scaling for generative modeling, we propose Training-Time and Inference-Time Scalable Discriminative Source Separation (TISDiSS), a unified framework that integrates early-split multi-loss supervision, shared-parameter design, and dynamic inference repetitions. TISDiSS enables flexible speed-performance trade-offs by adjusting inference depth without retraining additional models. We further provide systematic analyses of architectural and training choices and show that training with more inference repetitions improves shallow-inference performance, benefiting low-latency applications. Experiments on standard speech separation benchmarks demonstrate state-of-the-art performance with a reduced parameter count, establishing TISDiSS as a scalable and practical framework for adaptive source separation.
Mamba2 Meets Silence: Robust Vocal Source Separation for Sparse Regions
Aug 20, 2025We introduce a new music source separation model tailored for accurate vocal isolation. Unlike Transformer-based approaches, which often fail to capture intermittently occurring vocals, our model leverages Mamba2, a recent state space model, to better capture long-range temporal dependencies. To handle long input sequences efficiently, we combine a band-splitting strategy with a dual-path architecture. Experiments show that our approach outperforms recent state-of-the-art models, achieving a cSDR of 11.03 dB-the best reported to date-and delivering substantial gains in uSDR. Moreover, the model exhibits stable and consistent performance across varying input lengths and vocal occurrence patterns. These results demonstrate the effectiveness of Mamba-based models for high-resolution audio processing and open up new directions for broader applications in audio research.