 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManga109
Papers and Code
Robust Symbolic Reasoning for Visual Narratives via Hierarchical and Semantically Normalized Knowledge Graphs
Aug 20, 2025Understanding visual narratives such as comics requires structured representations that capture events, characters, and their relations across multiple levels of story organization. However, symbolic narrative graphs often suffer from inconsistency and redundancy, where similar actions or events are labeled differently across annotations or contexts. Such variance limits the effectiveness of reasoning and generalization. This paper introduces a semantic normalization framework for hierarchical narrative knowledge graphs. Building on cognitively grounded models of narrative comprehension, we propose methods that consolidate semantically related actions and events using lexical similarity and embedding-based clustering. The normalization process reduces annotation noise, aligns symbolic categories across narrative levels, and preserves interpretability. We demonstrate the framework on annotated manga stories from the Manga109 dataset, applying normalization to panel-, event-, and story-level graphs. Preliminary evaluations across narrative reasoning tasks, such as action retrieval, character grounding, and event summarization, show that semantic normalization improves coherence and robustness, while maintaining symbolic transparency. These findings suggest that normalization is a key step toward scalable, cognitively inspired graph models for multimodal narrative understanding.
A Lightweight Image Super-Resolution Transformer Trained on Low-Resolution Images Only
Mar 30, 2025Transformer architectures prominently lead single-image super-resolution (SISR) benchmarks, reconstructing high-resolution (HR) images from their low-resolution (LR) counterparts. Their strong representative power, however, comes with a higher demand for training data compared to convolutional neural networks (CNNs). For many real-world SR applications, the availability of high-quality HR training images is not given, sparking interest in LR-only training methods. The LR-only SISR benchmark mimics this condition by allowing only low-resolution (LR) images for model training. For a 4x super-resolution, this effectively reduces the amount of available training data to 6.25% of the HR image pixels, which puts the employment of a data-hungry transformer model into question. In this work, we are the first to utilize a lightweight vision transformer model with LR-only training methods addressing the unsupervised SISR LR-only benchmark. We adopt and configure a recent LR-only training method from microscopy image super-resolution to macroscopic real-world data, resulting in our multi-scale training method for bicubic degradation (MSTbic). Furthermore, we compare it with reference methods and prove its effectiveness both for a transformer and a CNN model. We evaluate on the classic SR benchmark datasets Set5, Set14, BSD100, Urban100, and Manga109, and show superior performance over state-of-the-art (so far: CNN-based) LR-only SISR methods. The code is available on GitHub: https://github.com/ifnspaml/SuperResolutionMultiscaleTraining.
FourierSR: A Fourier Token-based Plugin for Efficient Image Super-Resolution
Mar 13, 2025Image super-resolution (SR) aims to recover low-resolution images to high-resolution images, where improving SR efficiency is a high-profile challenge. However, commonly used units in SR, like convolutions and window-based Transformers, have limited receptive fields, making it challenging to apply them to improve SR under extremely limited computational cost. To address this issue, inspired by modeling convolution theorem through token mix, we propose a Fourier token-based plugin called FourierSR to improve SR uniformly, which avoids the instability or inefficiency of existing token mix technologies when applied as plug-ins. Furthermore, compared to convolutions and windows-based Transformers, our FourierSR only utilizes Fourier transform and multiplication operations, greatly reducing complexity while having global receptive fields. Experimental results show that our FourierSR as a plug-and-play unit brings an average PSNR gain of 0.34dB for existing efficient SR methods on Manga109 test set at the scale of x4, while the average increase in the number of Params and FLOPs is only 0.6% and 1.5% of original sizes. We will release our codes upon acceptance.
How Panel Layouts Define Manga: Insights from Visual Ablation Experiments
Dec 26, 2024



Today, manga has gained worldwide popularity. However, the question of how various elements of manga, such as characters, text, and panel layouts, reflect the uniqueness of a particular work, or even define it, remains an unexplored area. In this paper, we aim to quantitatively and qualitatively analyze the visual characteristics of manga works, with a particular focus on panel layout features. As a research method, we used facing page images of manga as input to train a deep learning model for predicting manga titles, examining classification accuracy to quantitatively analyze these features. Specifically, we conducted ablation studies by limiting page image information to panel frames to analyze the characteristics of panel layouts. Through a series of quantitative experiments using all 104 works, 12 genres, and 10,122 facing page images from the Manga109 dataset, as well as qualitative analysis using Grad-CAM, our study demonstrates that the uniqueness of manga works is strongly reflected in their panel layouts.
Hi-Mamba: Hierarchical Mamba for Efficient Image Super-Resolution
Oct 14, 2024



State Space Models (SSM), such as Mamba, have shown strong representation ability in modeling long-range dependency with linear complexity, achieving successful applications from high-level to low-level vision tasks. However, SSM's sequential nature necessitates multiple scans in different directions to compensate for the loss of spatial dependency when unfolding the image into a 1D sequence. This multi-direction scanning strategy significantly increases the computation overhead and is unbearable for high-resolution image processing. To address this problem, we propose a novel Hierarchical Mamba network, namely, Hi-Mamba, for image super-resolution (SR). Hi-Mamba consists of two key designs: (1) The Hierarchical Mamba Block (HMB) assembled by a Local SSM (L-SSM) and a Region SSM (R-SSM) both with the single-direction scanning, aggregates multi-scale representations to enhance the context modeling ability. (2) The Direction Alternation Hierarchical Mamba Group (DA-HMG) allocates the isomeric single-direction scanning into cascading HMBs to enrich the spatial relationship modeling. Extensive experiments demonstrate the superiority of Hi-Mamba across five benchmark datasets for efficient SR. For example, Hi-Mamba achieves a significant PSNR improvement of 0.29 dB on Manga109 for $\times3$ SR, compared to the strong lightweight MambaIR.
HiTSR: A Hierarchical Transformer for Reference-based Super-Resolution
Aug 30, 2024In this paper, we propose HiTSR, a hierarchical transformer model for reference-based image super-resolution, which enhances low-resolution input images by learning matching correspondences from high-resolution reference images. Diverging from existing multi-network, multi-stage approaches, we streamline the architecture and training pipeline by incorporating the double attention block from GAN literature. Processing two visual streams independently, we fuse self-attention and cross-attention blocks through a gating attention strategy. The model integrates a squeeze-and-excitation module to capture global context from the input images, facilitating long-range spatial interactions within window-based attention blocks. Long skip connections between shallow and deep layers further enhance information flow. Our model demonstrates superior performance across three datasets including SUN80, Urban100, and Manga109. Specifically, on the SUN80 dataset, our model achieves PSNR/SSIM values of 30.24/0.821. These results underscore the effectiveness of attention mechanisms in reference-based image super-resolution. The transformer-based model attains state-of-the-art results without the need for purpose-built subnetworks, knowledge distillation, or multi-stage training, emphasizing the potency of attention in meeting reference-based image super-resolution requirements.
ML-CrAIST: Multi-scale Low-high Frequency Information-based Cross black Attention with Image Super-resolving Transformer
Aug 19, 2024



Recently, transformers have captured significant interest in the area of single-image super-resolution tasks, demonstrating substantial gains in performance. Current models heavily depend on the network's extensive ability to extract high-level semantic details from images while overlooking the effective utilization of multi-scale image details and intermediate information within the network. Furthermore, it has been observed that high-frequency areas in images present significant complexity for super-resolution compared to low-frequency areas. This work proposes a transformer-based super-resolution architecture called ML-CrAIST that addresses this gap by utilizing low-high frequency information in multiple scales. Unlike most of the previous work (either spatial or channel), we operate spatial and channel self-attention, which concurrently model pixel interaction from both spatial and channel dimensions, exploiting the inherent correlations across spatial and channel axis. Further, we devise a cross-attention block for super-resolution, which explores the correlations between low and high-frequency information. Quantitative and qualitative assessments indicate that our proposed ML-CrAIST surpasses state-of-the-art super-resolution methods (e.g., 0.15 dB gain @Manga109 $\times$4). Code is available on: https://github.com/Alik033/ML-CrAIST.
LeRF: Learning Resampling Function for Adaptive and Efficient Image Interpolation
Jul 13, 2024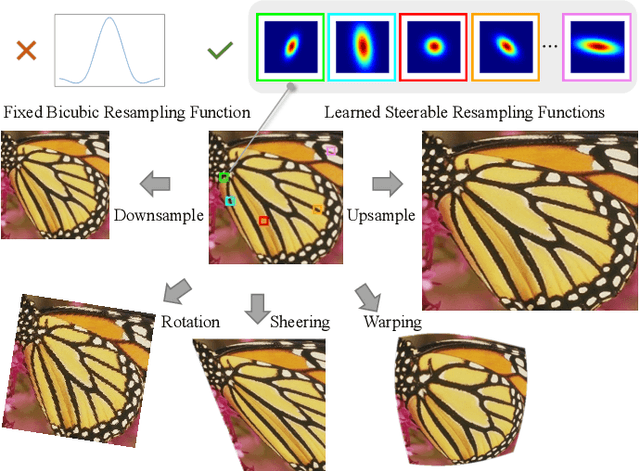

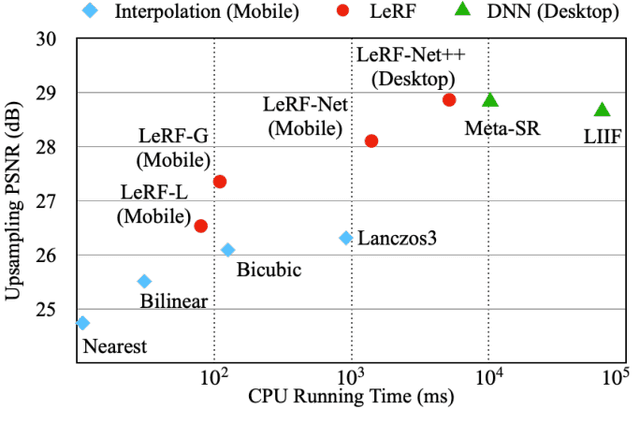
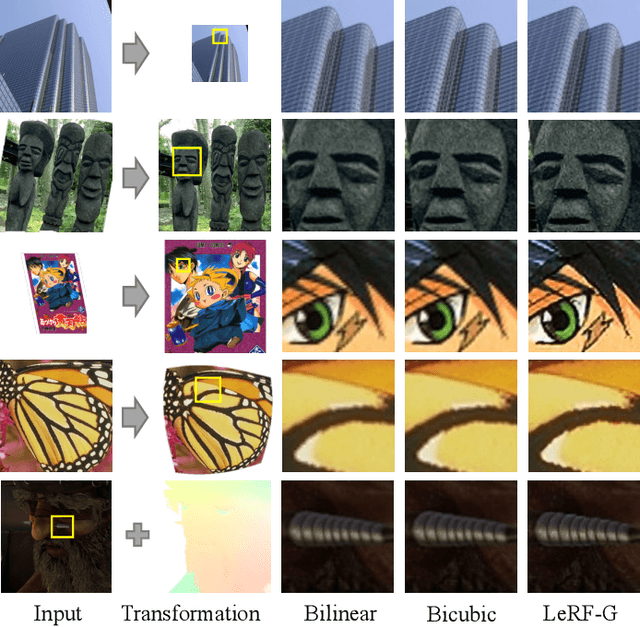
Image resampling is a basic technique that is widely employed in daily applications, such as camera photo editing. Recent deep neural networks (DNNs) have made impressive progress in performance by introducing learned data priors. Still, these methods are not the perfect substitute for interpolation, due to the drawbacks in efficiency and versatility. In this work, we propose a novel method of Learning Resampling Function (termed LeRF), which takes advantage of both the structural priors learned by DNNs and the locally continuous assumption of interpolation. Specifically, LeRF assigns spatially varying resampling functions to input image pixels and learns to predict the hyper-parameters that determine the shapes of these resampling functions with a neural network. Based on the formulation of LeRF, we develop a family of models, including both efficiency-orientated and performance-orientated ones. To achieve interpolation-level efficiency, we adopt look-up tables (LUTs) to accelerate the inference of the learned neural network. Furthermore, we design a directional ensemble strategy and edge-sensitive indexing patterns to better capture local structures. On the other hand, to obtain DNN-level performance, we propose an extension of LeRF to enable it in cooperation with pre-trained upsampling models for cascaded resampling. Extensive experiments show that the efficiency-orientated version of LeRF runs as fast as interpolation, generalizes well to arbitrary transformations, and outperforms interpolation significantly, e.g., up to 3dB PSNR gain over Bicubic for x2 upsampling on Manga109. Besides, the performance-orientated version of LeRF reaches comparable performance with existing DNNs at much higher efficiency, e.g., less than 25% running time on a desktop GPU.
Activating Wider Areas in Image Super-Resolution
Mar 13, 2024

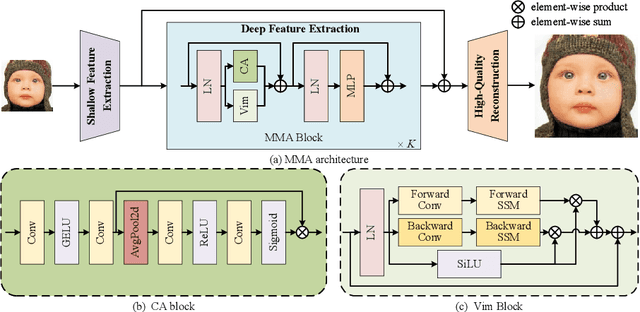

The prevalence of convolution neural networks (CNNs) and vision transformers (ViTs) has markedly revolutionized the area of single-image super-resolution (SISR). To further boost the SR performances, several techniques, such as residual learning and attention mechanism, are introduced, which can be largely attributed to a wider range of activated area, that is, the input pixels that strongly influence the SR results. However, the possibility of further improving SR performance through another versatile vision backbone remains an unresolved challenge. To address this issue, in this paper, we unleash the representation potential of the modern state space model, i.e., Vision Mamba (Vim), in the context of SISR. Specifically, we present three recipes for better utilization of Vim-based models: 1) Integration into a MetaFormer-style block; 2) Pre-training on a larger and broader dataset; 3) Employing complementary attention mechanism, upon which we introduce the MMA. The resulting network MMA is capable of finding the most relevant and representative input pixels to reconstruct the corresponding high-resolution images. Comprehensive experimental analysis reveals that MMA not only achieves competitive or even superior performance compared to state-of-the-art SISR methods but also maintains relatively low memory and computational overheads (e.g., +0.5 dB PSNR elevation on Manga109 dataset with 19.8 M parameters at the scale of 2). Furthermore, MMA proves its versatility in lightweight SR applications. Through this work, we aim to illuminate the potential applications of state space models in the broader realm of image processing rather than SISR, encouraging further exploration in this innovative direction.
Learning from History: Task-agnostic Model Contrastive Learning for Image Restoration
Sep 12, 2023Contrastive learning has emerged as a prevailing paradigm for high-level vision tasks, which, by introducing properly negative samples, has also been exploited for low-level vision tasks to achieve a compact optimization space to account for their ill-posed nature. However, existing methods rely on manually predefined, task-oriented negatives, which often exhibit pronounced task-specific biases. In this paper, we propose a innovative approach for the adaptive generation of negative samples directly from the target model itself, called ``learning from history``. We introduce the Self-Prior guided Negative loss for image restoration (SPNIR) to enable this approach. Our approach is task-agnostic and generic, making it compatible with any existing image restoration method or task. We demonstrate the effectiveness of our approach by retraining existing models with SPNIR. The results show significant improvements in image restoration across various tasks and architectures. For example, models retrained with SPNIR outperform the original FFANet and DehazeFormer by 3.41 dB and 0.57 dB on the RESIDE indoor dataset for image dehazing. Similarly, they achieve notable improvements of 0.47 dB on SPA-Data over IDT for image deraining and 0.12 dB on Manga109 for a 4x scale super-resolution over lightweight SwinIR, respectively. Code and retrained models are available at https://github.com/Aitical/Task-agnostic_Model_Contrastive_Learning_Image_Restoration.