 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDGSSM: Diffusion guided state-space models for multimodal salient object detection
Apr 19, 2026Salient object detection (SOD) requires modeling both long-range contextual dependencies and fine-grained structural details, which remains challenging for convolutional, transformer-based, and Mamba-based state space models. While recent Mamba-based state space approaches enable efficient global reasoning, they often struggle to recover precise object boundaries. In contrast, diffusion models capture strong structural priors through iterative denoising, but their use in discriminative dense prediction is still limited due to computational cost and integration challenges. In this work, we propose DGSSM, a diffusion-guided state space (Mamba) framework that formulates multimodal salient object detection as a progressive denoising process. The framework integrates diffusion structural priors with multi-scale state space encoding, adaptive saliency prompting, and an iterative Mamba diffusion refinement mechanism to improve boundary accuracy. A boundary-aware refinement head and self-distillation strategy further enhance spatial coherence and feature consistency. Extensive experiments on 13 public benchmarks across RGB, RGB-D, and RGB-T settings demonstrate that DGSSM consistently outperforms state-of-the-art methods across multiple evaluation metrics while maintaining a compact model size. These results suggest that diffusion-guided state space modeling is an effective and generalizable paradigm for multimodal dense prediction tasks.
Universal Adversarial Suffixes for Language Models Using Reinforcement Learning with Calibrated Reward
Dec 09, 2025

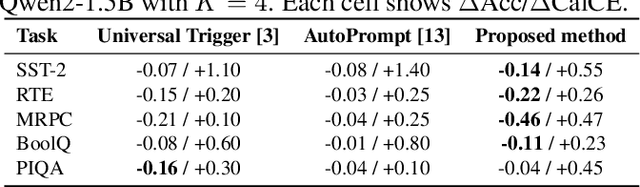
Language models are vulnerable to short adversarial suffixes that can reliably alter predictions. Previous works usually find such suffixes with gradient search or rule-based methods, but these are brittle and often tied to a single task or model. In this paper, a reinforcement learning framework is used where the suffix is treated as a policy and trained with Proximal Policy Optimization against a frozen model as a reward oracle. Rewards are shaped using calibrated cross-entropy, removing label bias and aggregating across surface forms to improve transferability. The proposed method is evaluated on five diverse NLP benchmark datasets, covering sentiment, natural language inference, paraphrase, and commonsense reasoning, using three distinct language models: Qwen2-1.5B Instruct, TinyLlama-1.1B Chat, and Phi-1.5. Results show that RL-trained suffixes consistently degrade accuracy and transfer more effectively across tasks and models than previous adversarial triggers of similar genres.
Universal Adversarial Suffixes Using Calibrated Gumbel-Softmax Relaxation
Dec 09, 2025Language models (LMs) are often used as zero-shot or few-shot classifiers by scoring label words, but they remain fragile to adversarial prompts. Prior work typically optimizes task- or model-specific triggers, making results difficult to compare and limiting transferability. We study universal adversarial suffixes: short token sequences (4-10 tokens) that, when appended to any input, broadly reduce accuracy across tasks and models. Our approach learns the suffix in a differentiable "soft" form using Gumbel-Softmax relaxation and then discretizes it for inference. Training maximizes calibrated cross-entropy on the label region while masking gold tokens to prevent trivial leakage, with entropy regularization to avoid collapse. A single suffix trained on one model transfers effectively to others, consistently lowering both accuracy and calibrated confidence. Experiments on sentiment analysis, natural language inference, paraphrase detection, commonsense QA, and physical reasoning with Qwen2-1.5B, Phi-1.5, and TinyLlama-1.1B demonstrate consistent attack effectiveness and transfer across tasks and model families.
C-LEAD: Contrastive Learning for Enhanced Adversarial Defense
Oct 31, 2025



Deep neural networks (DNNs) have achieved remarkable success in computer vision tasks such as image classification, segmentation, and object detection. However, they are vulnerable to adversarial attacks, which can cause incorrect predictions with small perturbations in input images. Addressing this issue is crucial for deploying robust deep-learning systems. This paper presents a novel approach that utilizes contrastive learning for adversarial defense, a previously unexplored area. Our method leverages the contrastive loss function to enhance the robustness of classification models by training them with both clean and adversarially perturbed images. By optimizing the model's parameters alongside the perturbations, our approach enables the network to learn robust representations that are less susceptible to adversarial attacks. Experimental results show significant improvements in the model's robustness against various types of adversarial perturbations. This suggests that contrastive loss helps extract more informative and resilient features, contributing to the field of adversarial robustness in deep learning.
Trans-defense: Transformer-based Denoiser for Adversarial Defense with Spatial-Frequency Domain Representation
Oct 31, 2025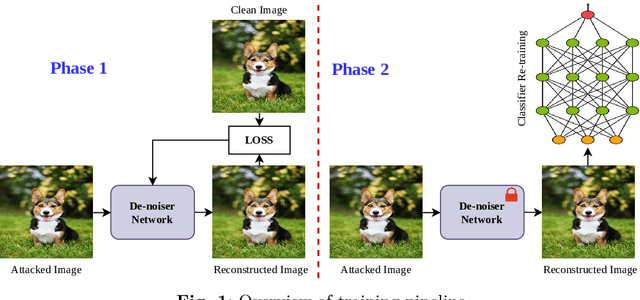
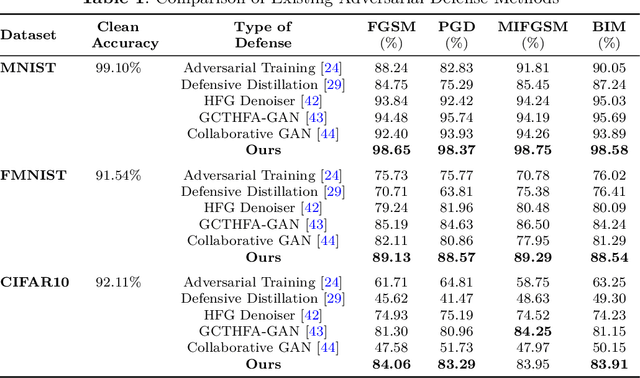
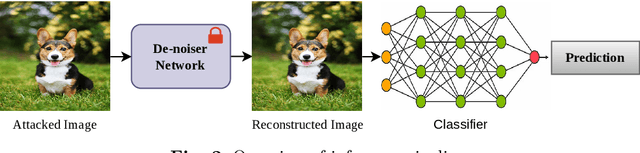

In recent times, deep neural networks (DNNs) have been successfully adopted for various applications. Despite their notable achievements, it has become evident that DNNs are vulnerable to sophisticated adversarial attacks, restricting their applications in security-critical systems. In this paper, we present two-phase training methods to tackle the attack: first, training the denoising network, and second, the deep classifier model. We propose a novel denoising strategy that integrates both spatial and frequency domain approaches to defend against adversarial attacks on images. Our analysis reveals that high-frequency components of attacked images are more severely corrupted compared to their lower-frequency counterparts. To address this, we leverage Discrete Wavelet Transform (DWT) for frequency analysis and develop a denoising network that combines spatial image features with wavelets through a transformer layer. Next, we retrain the classifier using the denoised images, which enhances the classifier's robustness against adversarial attacks. Experimental results across the MNIST, CIFAR-10, and Fashion-MNIST datasets reveal that the proposed method remarkably elevates classification accuracy, substantially exceeding the performance by utilizing a denoising network and adversarial training approaches. The code is available at https://github.com/Mayank94/Trans-Defense.
Harnessing Multi-resolution and Multi-scale Attention for Underwater Image Restoration
Aug 19, 2024Underwater imagery is often compromised by factors such as color distortion and low contrast, posing challenges for high-level vision tasks. Recent underwater image restoration (UIR) methods either analyze the input image at full resolution, resulting in spatial richness but contextual weakness, or progressively from high to low resolution, yielding reliable semantic information but reduced spatial accuracy. Here, we propose a lightweight multi-stage network called Lit-Net that focuses on multi-resolution and multi-scale image analysis for restoring underwater images while retaining original resolution during the first stage, refining features in the second, and focusing on reconstruction in the final stage. Our novel encoder block utilizes parallel $1\times1$ convolution layers to capture local information and speed up operations. Further, we incorporate a modified weighted color channel-specific $l_1$ loss ($cl_1$) function to recover color and detail information. Extensive experimentations on publicly available datasets suggest our model's superiority over recent state-of-the-art methods, with significant improvement in qualitative and quantitative measures, such as $29.477$ dB PSNR ($1.92\%$ improvement) and $0.851$ SSIM ($2.87\%$ improvement) on the EUVP dataset. The contributions of Lit-Net offer a more robust approach to underwater image enhancement and super-resolution, which is of considerable importance for underwater autonomous vehicles and surveillance. The code is available at: https://github.com/Alik033/Lit-Net.
ML-CrAIST: Multi-scale Low-high Frequency Information-based Cross black Attention with Image Super-resolving Transformer
Aug 19, 2024



Recently, transformers have captured significant interest in the area of single-image super-resolution tasks, demonstrating substantial gains in performance. Current models heavily depend on the network's extensive ability to extract high-level semantic details from images while overlooking the effective utilization of multi-scale image details and intermediate information within the network. Furthermore, it has been observed that high-frequency areas in images present significant complexity for super-resolution compared to low-frequency areas. This work proposes a transformer-based super-resolution architecture called ML-CrAIST that addresses this gap by utilizing low-high frequency information in multiple scales. Unlike most of the previous work (either spatial or channel), we operate spatial and channel self-attention, which concurrently model pixel interaction from both spatial and channel dimensions, exploiting the inherent correlations across spatial and channel axis. Further, we devise a cross-attention block for super-resolution, which explores the correlations between low and high-frequency information. Quantitative and qualitative assessments indicate that our proposed ML-CrAIST surpasses state-of-the-art super-resolution methods (e.g., 0.15 dB gain @Manga109 $\times$4). Code is available on: https://github.com/Alik033/ML-CrAIST.
Zero-Shot Underwater Gesture Recognition
Jul 19, 2024



Hand gesture recognition allows humans to interact with machines non-verbally, which has a huge application in underwater exploration using autonomous underwater vehicles. Recently, a new gesture-based language called CADDIAN has been devised for divers, and supervised learning methods have been applied to recognize the gestures with high accuracy. However, such methods fail when they encounter unseen gestures in real time. In this work, we advocate the need for zero-shot underwater gesture recognition (ZSUGR), where the objective is to train a model with visual samples of gestures from a few ``seen'' classes only and transfer the gained knowledge at test time to recognize semantically-similar unseen gesture classes as well. After discussing the problem and dataset-specific challenges, we propose new seen-unseen splits for gesture classes in CADDY dataset. Then, we present a two-stage framework, where a novel transformer learns strong visual gesture cues and feeds them to a conditional generative adversarial network that learns to mimic feature distribution. We use the trained generator as a feature synthesizer for unseen classes, enabling zero-shot learning. Extensive experiments demonstrate that our method outperforms the existing zero-shot techniques. We conclude by providing useful insights into our framework and suggesting directions for future research.
Segmentation of tibiofemoral joint tissues from knee MRI using MtRA-Unet and incorporating shape information: Data from the Osteoarthritis Initiative
Jan 23, 2024Knee Osteoarthritis (KOA) is the third most prevalent Musculoskeletal Disorder (MSD) after neck and back pain. To monitor such a severe MSD, a segmentation map of the femur, tibia and tibiofemoral cartilage is usually accessed using the automated segmentation algorithm from the Magnetic Resonance Imaging (MRI) of the knee. But, in recent works, such segmentation is conceivable only from the multistage framework thus creating data handling issues and needing continuous manual inference rendering it unable to make a quick and precise clinical diagnosis. In order to solve these issues, in this paper the Multi-Resolution Attentive-Unet (MtRA-Unet) is proposed to segment the femur, tibia and tibiofemoral cartilage automatically. The proposed work has included a novel Multi-Resolution Feature Fusion (MRFF) and Shape Reconstruction (SR) loss that focuses on multi-contextual information and structural anatomical details of the femur, tibia and tibiofemoral cartilage. Unlike previous approaches, the proposed work is a single-stage and end-to-end framework producing a Dice Similarity Coefficient (DSC) of 98.5% for the femur, 98.4% for the tibia, 89.1% for Femoral Cartilage (FC) and 86.1% for Tibial Cartilage (TC) for critical MRI slices that can be helpful to clinicians for KOA grading. The time to segment MRI volume (160 slices) per subject is 22 sec. which is one of the fastest among state-of-the-art. Moreover, comprehensive experimentation on the segmentation of FC and TC which is of utmost importance for morphology-based studies to check KOA progression reveals that the proposed method has produced an excellent result with binary segmentation
DatUS^2: Data-driven Unsupervised Semantic Segmentation with Pre-trained Self-supervised Vision Transformer
Jan 23, 2024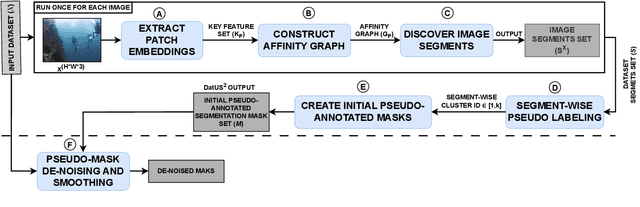

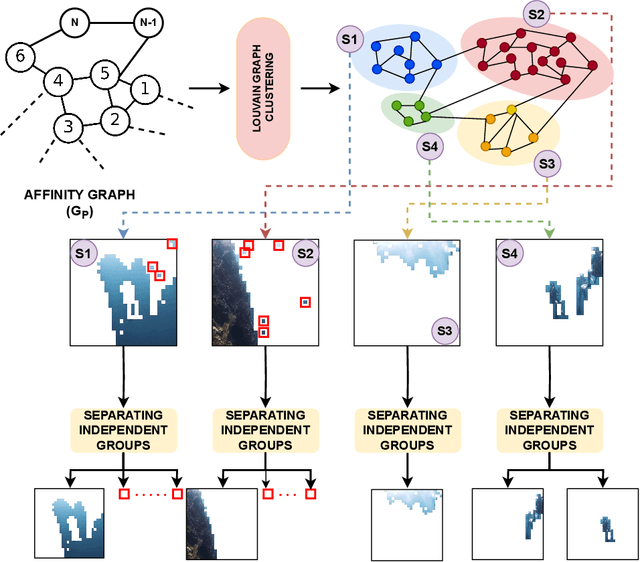

Successive proposals of several self-supervised training schemes continue to emerge, taking one step closer to developing a universal foundation model. In this process, the unsupervised downstream tasks are recognized as one of the evaluation methods to validate the quality of visual features learned with a self-supervised training scheme. However, unsupervised dense semantic segmentation has not been explored as a downstream task, which can utilize and evaluate the quality of semantic information introduced in patch-level feature representations during self-supervised training of a vision transformer. Therefore, this paper proposes a novel data-driven approach for unsupervised semantic segmentation (DatUS^2) as a downstream task. DatUS^2 generates semantically consistent and dense pseudo annotate segmentation masks for the unlabeled image dataset without using any visual-prior or synchronized data. We compare these pseudo-annotated segmentation masks with ground truth masks for evaluating recent self-supervised training schemes to learn shared semantic properties at the patch level and discriminative semantic properties at the segment level. Finally, we evaluate existing state-of-the-art self-supervised training schemes with our proposed downstream task, i.e., DatUS^2. Also, the best version of DatUS^2 outperforms the existing state-of-the-art method for the unsupervised dense semantic segmentation task with 15.02% MiOU and 21.47% Pixel accuracy on the SUIM dataset. It also achieves a competitive level of accuracy for a large-scale and complex dataset, i.e., the COCO dataset.