 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrans-defense: Transformer-based Denoiser for Adversarial Defense with Spatial-Frequency Domain Representation
Oct 31, 2025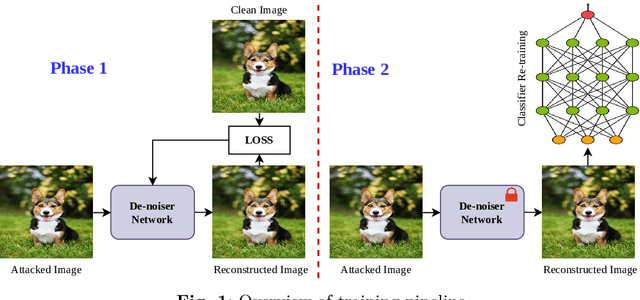
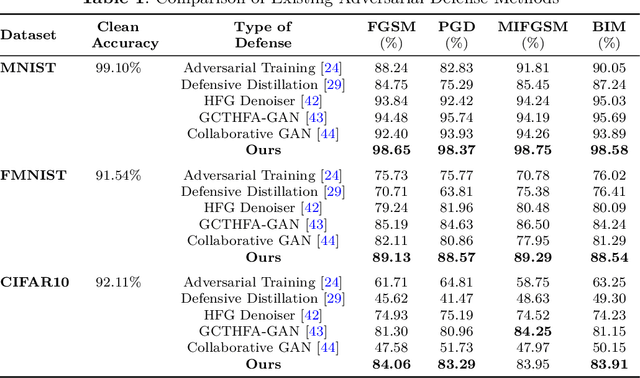
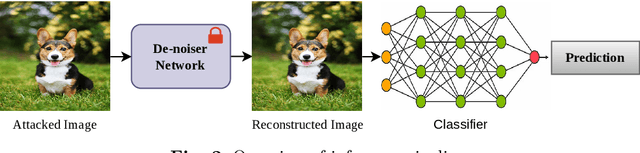

In recent times, deep neural networks (DNNs) have been successfully adopted for various applications. Despite their notable achievements, it has become evident that DNNs are vulnerable to sophisticated adversarial attacks, restricting their applications in security-critical systems. In this paper, we present two-phase training methods to tackle the attack: first, training the denoising network, and second, the deep classifier model. We propose a novel denoising strategy that integrates both spatial and frequency domain approaches to defend against adversarial attacks on images. Our analysis reveals that high-frequency components of attacked images are more severely corrupted compared to their lower-frequency counterparts. To address this, we leverage Discrete Wavelet Transform (DWT) for frequency analysis and develop a denoising network that combines spatial image features with wavelets through a transformer layer. Next, we retrain the classifier using the denoised images, which enhances the classifier's robustness against adversarial attacks. Experimental results across the MNIST, CIFAR-10, and Fashion-MNIST datasets reveal that the proposed method remarkably elevates classification accuracy, substantially exceeding the performance by utilizing a denoising network and adversarial training approaches. The code is available at https://github.com/Mayank94/Trans-Defense.
ML-CrAIST: Multi-scale Low-high Frequency Information-based Cross black Attention with Image Super-resolving Transformer
Aug 19, 2024



Recently, transformers have captured significant interest in the area of single-image super-resolution tasks, demonstrating substantial gains in performance. Current models heavily depend on the network's extensive ability to extract high-level semantic details from images while overlooking the effective utilization of multi-scale image details and intermediate information within the network. Furthermore, it has been observed that high-frequency areas in images present significant complexity for super-resolution compared to low-frequency areas. This work proposes a transformer-based super-resolution architecture called ML-CrAIST that addresses this gap by utilizing low-high frequency information in multiple scales. Unlike most of the previous work (either spatial or channel), we operate spatial and channel self-attention, which concurrently model pixel interaction from both spatial and channel dimensions, exploiting the inherent correlations across spatial and channel axis. Further, we devise a cross-attention block for super-resolution, which explores the correlations between low and high-frequency information. Quantitative and qualitative assessments indicate that our proposed ML-CrAIST surpasses state-of-the-art super-resolution methods (e.g., 0.15 dB gain @Manga109 $\times$4). Code is available on: https://github.com/Alik033/ML-CrAIST.
Harnessing Multi-resolution and Multi-scale Attention for Underwater Image Restoration
Aug 19, 2024Underwater imagery is often compromised by factors such as color distortion and low contrast, posing challenges for high-level vision tasks. Recent underwater image restoration (UIR) methods either analyze the input image at full resolution, resulting in spatial richness but contextual weakness, or progressively from high to low resolution, yielding reliable semantic information but reduced spatial accuracy. Here, we propose a lightweight multi-stage network called Lit-Net that focuses on multi-resolution and multi-scale image analysis for restoring underwater images while retaining original resolution during the first stage, refining features in the second, and focusing on reconstruction in the final stage. Our novel encoder block utilizes parallel $1\times1$ convolution layers to capture local information and speed up operations. Further, we incorporate a modified weighted color channel-specific $l_1$ loss ($cl_1$) function to recover color and detail information. Extensive experimentations on publicly available datasets suggest our model's superiority over recent state-of-the-art methods, with significant improvement in qualitative and quantitative measures, such as $29.477$ dB PSNR ($1.92\%$ improvement) and $0.851$ SSIM ($2.87\%$ improvement) on the EUVP dataset. The contributions of Lit-Net offer a more robust approach to underwater image enhancement and super-resolution, which is of considerable importance for underwater autonomous vehicles and surveillance. The code is available at: https://github.com/Alik033/Lit-Net.
Segmentation of tibiofemoral joint tissues from knee MRI using MtRA-Unet and incorporating shape information: Data from the Osteoarthritis Initiative
Jan 23, 2024Knee Osteoarthritis (KOA) is the third most prevalent Musculoskeletal Disorder (MSD) after neck and back pain. To monitor such a severe MSD, a segmentation map of the femur, tibia and tibiofemoral cartilage is usually accessed using the automated segmentation algorithm from the Magnetic Resonance Imaging (MRI) of the knee. But, in recent works, such segmentation is conceivable only from the multistage framework thus creating data handling issues and needing continuous manual inference rendering it unable to make a quick and precise clinical diagnosis. In order to solve these issues, in this paper the Multi-Resolution Attentive-Unet (MtRA-Unet) is proposed to segment the femur, tibia and tibiofemoral cartilage automatically. The proposed work has included a novel Multi-Resolution Feature Fusion (MRFF) and Shape Reconstruction (SR) loss that focuses on multi-contextual information and structural anatomical details of the femur, tibia and tibiofemoral cartilage. Unlike previous approaches, the proposed work is a single-stage and end-to-end framework producing a Dice Similarity Coefficient (DSC) of 98.5% for the femur, 98.4% for the tibia, 89.1% for Femoral Cartilage (FC) and 86.1% for Tibial Cartilage (TC) for critical MRI slices that can be helpful to clinicians for KOA grading. The time to segment MRI volume (160 slices) per subject is 22 sec. which is one of the fastest among state-of-the-art. Moreover, comprehensive experimentation on the segmentation of FC and TC which is of utmost importance for morphology-based studies to check KOA progression reveals that the proposed method has produced an excellent result with binary segmentation