 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatUS^2: Data-driven Unsupervised Semantic Segmentation with Pre-trained Self-supervised Vision Transformer
Jan 23, 2024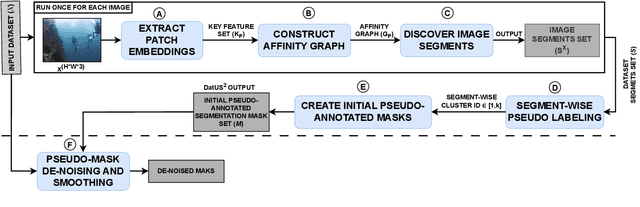

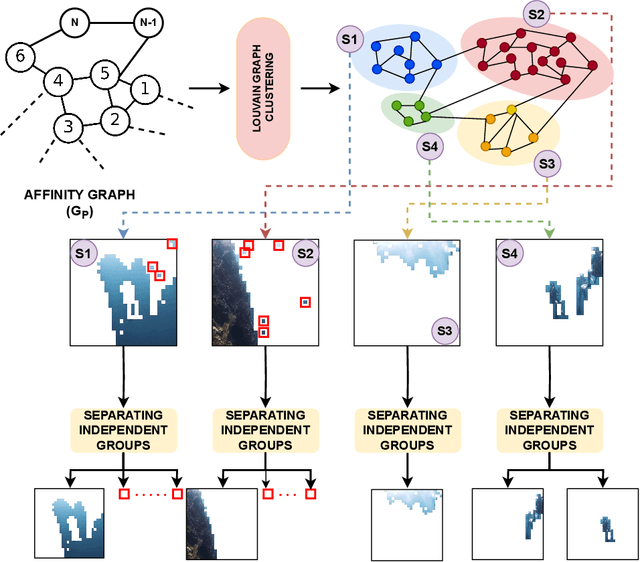

Successive proposals of several self-supervised training schemes continue to emerge, taking one step closer to developing a universal foundation model. In this process, the unsupervised downstream tasks are recognized as one of the evaluation methods to validate the quality of visual features learned with a self-supervised training scheme. However, unsupervised dense semantic segmentation has not been explored as a downstream task, which can utilize and evaluate the quality of semantic information introduced in patch-level feature representations during self-supervised training of a vision transformer. Therefore, this paper proposes a novel data-driven approach for unsupervised semantic segmentation (DatUS^2) as a downstream task. DatUS^2 generates semantically consistent and dense pseudo annotate segmentation masks for the unlabeled image dataset without using any visual-prior or synchronized data. We compare these pseudo-annotated segmentation masks with ground truth masks for evaluating recent self-supervised training schemes to learn shared semantic properties at the patch level and discriminative semantic properties at the segment level. Finally, we evaluate existing state-of-the-art self-supervised training schemes with our proposed downstream task, i.e., DatUS^2. Also, the best version of DatUS^2 outperforms the existing state-of-the-art method for the unsupervised dense semantic segmentation task with 15.02% MiOU and 21.47% Pixel accuracy on the SUIM dataset. It also achieves a competitive level of accuracy for a large-scale and complex dataset, i.e., the COCO dataset.
Explicit Context Integrated Recurrent Neural Network for Sensor Data Applications
Jan 12, 2023The development and progress in sensor, communication and computing technologies have led to data rich environments. In such environments, data can easily be acquired not only from the monitored entities but also from the surroundings where the entity is operating. The additional data that are available from the problem domain, which cannot be used independently for learning models, constitute context. Such context, if taken into account while learning, can potentially improve the performance of predictive models. Typically, the data from various sensors are present in the form of time series. Recurrent Neural Networks (RNNs) are preferred for such data as it can inherently handle temporal context. However, the conventional RNN models such as Elman RNN, Long Short-Term Memory (LSTM) and Gated Recurrent Unit (GRU) in their present form do not provide any mechanism to integrate explicit contexts. In this paper, we propose a Context Integrated RNN (CiRNN) that enables integrating explicit contexts represented in the form of contextual features. In CiRNN, the network weights are influenced by contextual features in such a way that the primary input features which are more relevant to a given context are given more importance. To show the efficacy of CiRNN, we selected an application domain, engine health prognostics, which captures data from various sensors and where contextual information is available. We used the NASA Turbofan Engine Degradation Simulation dataset for estimating Remaining Useful Life (RUL) as it provides contextual information. We compared CiRNN with baseline models as well as the state-of-the-art methods. The experimental results show an improvement of 39% and 87% respectively, over state-of-the art models, when performance is measured with RMSE and score from an asymmetric scoring function. The latter measure is specific to the task of RUL estimation.