 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDatUS^2: Data-driven Unsupervised Semantic Segmentation with Pre-trained Self-supervised Vision Transformer
Paper and Code
Jan 23, 2024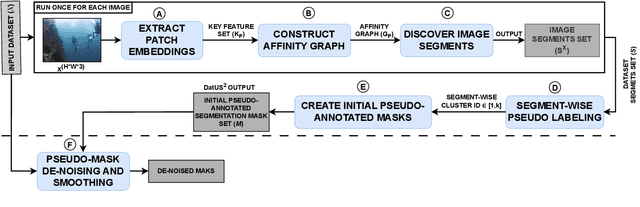

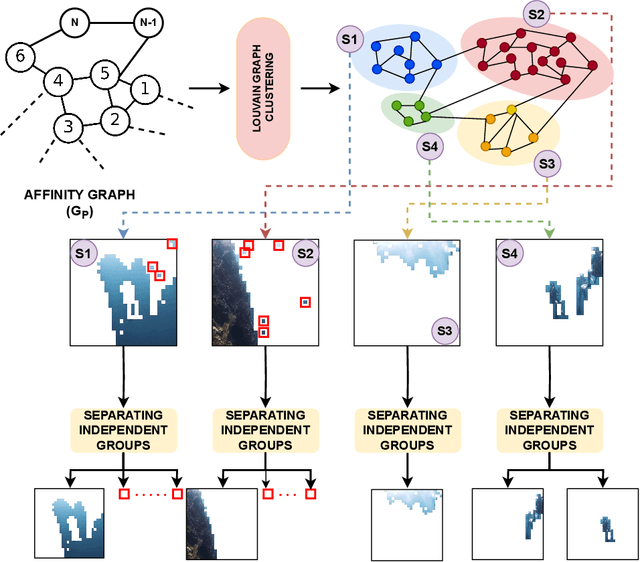

Successive proposals of several self-supervised training schemes continue to emerge, taking one step closer to developing a universal foundation model. In this process, the unsupervised downstream tasks are recognized as one of the evaluation methods to validate the quality of visual features learned with a self-supervised training scheme. However, unsupervised dense semantic segmentation has not been explored as a downstream task, which can utilize and evaluate the quality of semantic information introduced in patch-level feature representations during self-supervised training of a vision transformer. Therefore, this paper proposes a novel data-driven approach for unsupervised semantic segmentation (DatUS^2) as a downstream task. DatUS^2 generates semantically consistent and dense pseudo annotate segmentation masks for the unlabeled image dataset without using any visual-prior or synchronized data. We compare these pseudo-annotated segmentation masks with ground truth masks for evaluating recent self-supervised training schemes to learn shared semantic properties at the patch level and discriminative semantic properties at the segment level. Finally, we evaluate existing state-of-the-art self-supervised training schemes with our proposed downstream task, i.e., DatUS^2. Also, the best version of DatUS^2 outperforms the existing state-of-the-art method for the unsupervised dense semantic segmentation task with 15.02% MiOU and 21.47% Pixel accuracy on the SUIM dataset. It also achieves a competitive level of accuracy for a large-scale and complex dataset, i.e., the COCO dataset.