 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiTSR: A Hierarchical Transformer for Reference-based Super-Resolution
Aug 30, 2024In this paper, we propose HiTSR, a hierarchical transformer model for reference-based image super-resolution, which enhances low-resolution input images by learning matching correspondences from high-resolution reference images. Diverging from existing multi-network, multi-stage approaches, we streamline the architecture and training pipeline by incorporating the double attention block from GAN literature. Processing two visual streams independently, we fuse self-attention and cross-attention blocks through a gating attention strategy. The model integrates a squeeze-and-excitation module to capture global context from the input images, facilitating long-range spatial interactions within window-based attention blocks. Long skip connections between shallow and deep layers further enhance information flow. Our model demonstrates superior performance across three datasets including SUN80, Urban100, and Manga109. Specifically, on the SUN80 dataset, our model achieves PSNR/SSIM values of 30.24/0.821. These results underscore the effectiveness of attention mechanisms in reference-based image super-resolution. The transformer-based model attains state-of-the-art results without the need for purpose-built subnetworks, knowledge distillation, or multi-stage training, emphasizing the potency of attention in meeting reference-based image super-resolution requirements.
DARTS: Double Attention Reference-based Transformer for Super-resolution
Jul 17, 2023We present DARTS, a transformer model for reference-based image super-resolution. DARTS learns joint representations of two image distributions to enhance the content of low-resolution input images through matching correspondences learned from high-resolution reference images. Current state-of-the-art techniques in reference-based image super-resolution are based on a multi-network, multi-stage architecture. In this work, we adapt the double attention block from the GAN literature, processing the two visual streams separately and combining self-attention and cross-attention blocks through a gating attention strategy. Our work demonstrates how the attention mechanism can be adapted for the particular requirements of reference-based image super-resolution, significantly simplifying the architecture and training pipeline. We show that our transformer-based model performs competitively with state-of-the-art models, while maintaining a simpler overall architecture and training process. In particular, we obtain state-of-the-art on the SUN80 dataset, with a PSNR/SSIM of 29.83 / .809. These results show that attention alone is sufficient for the RSR task, without multiple purpose-built subnetworks, knowledge distillation, or multi-stage training.
Unsupervised Domain Adaptation For Plant Organ Counting
Sep 02, 2020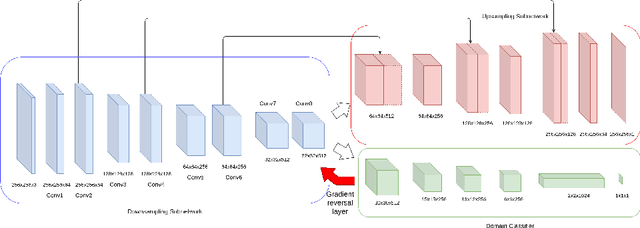
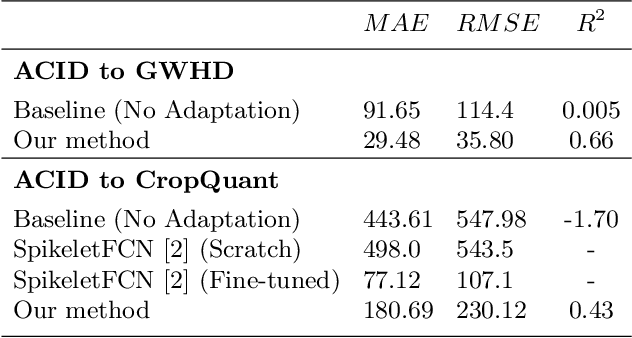


Supervised learning is often used to count objects in images, but for counting small, densely located objects, the required image annotations are burdensome to collect. Counting plant organs for image-based plant phenotyping falls within this category. Object counting in plant images is further challenged by having plant image datasets with significant domain shift due to different experimental conditions, e.g. applying an annotated dataset of indoor plant images for use on outdoor images, or on a different plant species. In this paper, we propose a domain-adversarial learning approach for domain adaptation of density map estimation for the purposes of object counting. The approach does not assume perfectly aligned distributions between the source and target datasets, which makes it more broadly applicable within general object counting and plant organ counting tasks. Evaluation on two diverse object counting tasks (wheat spikelets, leaves) demonstrates consistent performance on the target datasets across different classes of domain shift: from indoor-to-outdoor images and from species-to-species adaptation.
AutoCount: Unsupervised Segmentation and Counting of Organs in Field Images
Jul 17, 2020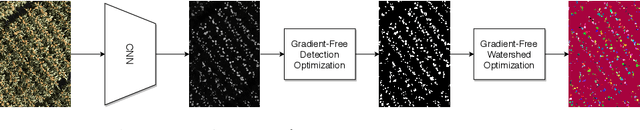

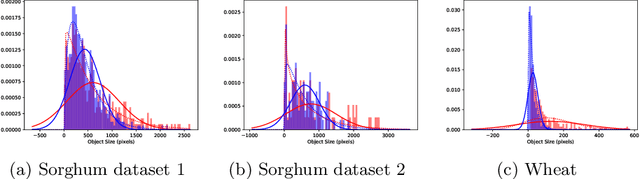

Counting plant organs such as heads or tassels from outdoor imagery is a popular benchmark computer vision task in plant phenotyping, which has been previously investigated in the literature using state-of-the-art supervised deep learning techniques. However, the annotation of organs in field images is time-consuming and prone to errors. In this paper, we propose a fully unsupervised technique for counting dense objects such as plant organs. We use a convolutional network-based unsupervised segmentation method followed by two post-hoc optimization steps. The proposed technique is shown to provide competitive counting performance on a range of organ counting tasks in sorghum (S. bicolor) and wheat (T. aestivum) with no dataset-dependent tuning or modifications.