 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKeypoint Detection
Keypoint detection is essential for analyzing and interpreting images in computer vision. It involves simultaneously detecting and localizing interesting points in an image. Keypoints, also known as interest points, are spatial locations or points in the image that define what is interesting or what stands out. They are invariant to image rotation, shrinkage, translation, distortion, etc. Keypoint examples include body joints, facial landmarks, or any other salient points in objects. Keypoints have uses in problems such as pose estimation, object detection and tracking, facial analysis, and augmented reality.
Papers and Code
ZENITH: Automated Gradient Norm Informed Stochastic Optimization
Jan 21, 2026Training deep computer vision models requires manual oversight or hyperparameter tuning of the learning rate (LR) schedule. While existing adaptive optimizers schedule the LR automatically, they suffer from computational and memory overhead, incompatibility with regularization, and suboptimal LR choices. In this work, we introduce the ZENITH (Zero-overhead Evolution using Norm-Informed Training History) optimizer, which adapts the LR using the temporal evolution of the gradient norm. Image classification experiments spanning 6 CNN architectures and 6 benchmarks demonstrate that ZENITH achieves higher test accuracy in lower wall-clock time than baselines. It also yielded superior mAP in object detection, keypoint detection, and instance segmentation on MS COCO using the R-CNN family of models. Furthermore, its compatibility with regularization enables even better generalization.
Coarse-to-Fine Non-rigid Multi-modal Image Registration for Historical Panel Paintings based on Crack Structures
Jan 22, 2026Art technological investigations of historical panel paintings rely on acquiring multi-modal image data, including visual light photography, infrared reflectography, ultraviolet fluorescence photography, x-radiography, and macro photography. For a comprehensive analysis, the multi-modal images require pixel-wise alignment, which is still often performed manually. Multi-modal image registration can reduce this laborious manual work, is substantially faster, and enables higher precision. Due to varying image resolutions, huge image sizes, non-rigid distortions, and modality-dependent image content, registration is challenging. Therefore, we propose a coarse-to-fine non-rigid multi-modal registration method efficiently relying on sparse keypoints and thin-plate-splines. Historical paintings exhibit a fine crack pattern, called craquelure, on the paint layer, which is captured by all image systems and is well-suited as a feature for registration. In our one-stage non-rigid registration approach, we employ a convolutional neural network for joint keypoint detection and description based on the craquelure and a graph neural network for descriptor matching in a patch-based manner, and filter matches based on homography reprojection errors in local areas. For coarse-to-fine registration, we introduce a novel multi-level keypoint refinement approach to register mixed-resolution images up to the highest resolution. We created a multi-modal dataset of panel paintings with a high number of keypoint annotations, and a large test set comprising five multi-modal domains and varying image resolutions. The ablation study demonstrates the effectiveness of all modules of our refinement method. Our proposed approaches achieve the best registration results compared to competing keypoint and dense matching methods and refinement methods.
A Multi-View Pipeline and Benchmark Dataset for 3D Hand Pose Estimation in Surgery
Jan 22, 2026Purpose: Accurate 3D hand pose estimation supports surgical applications such as skill assessment, robot-assisted interventions, and geometry-aware workflow analysis. However, surgical environments pose severe challenges, including intense and localized lighting, frequent occlusions by instruments or staff, and uniform hand appearance due to gloves, combined with a scarcity of annotated datasets for reliable model training. Method: We propose a robust multi-view pipeline for 3D hand pose estimation in surgical contexts that requires no domain-specific fine-tuning and relies solely on off-the-shelf pretrained models. The pipeline integrates reliable person detection, whole-body pose estimation, and state-of-the-art 2D hand keypoint prediction on tracked hand crops, followed by a constrained 3D optimization. In addition, we introduce a novel surgical benchmark dataset comprising over 68,000 frames and 3,000 manually annotated 2D hand poses with triangulated 3D ground truth, recorded in a replica operating room under varying levels of scene complexity. Results: Quantitative experiments demonstrate that our method consistently outperforms baselines, achieving a 31% reduction in 2D mean joint error and a 76% reduction in 3D mean per-joint position error. Conclusion: Our work establishes a strong baseline for 3D hand pose estimation in surgery, providing both a training-free pipeline and a comprehensive annotated dataset to facilitate future research in surgical computer vision.
COMPOSE: Hypergraph Cover Optimization for Multi-view 3D Human Pose Estimation
Jan 14, 20263D pose estimation from sparse multi-views is a critical task for numerous applications, including action recognition, sports analysis, and human-robot interaction. Optimization-based methods typically follow a two-stage pipeline, first detecting 2D keypoints in each view and then associating these detections across views to triangulate the 3D pose. Existing methods rely on mere pairwise associations to model this correspondence problem, treating global consistency between views (i.e., cycle consistency) as a soft constraint. Yet, reconciling these constraints for multiple views becomes brittle when spurious associations propagate errors. We thus propose COMPOSE, a novel framework that formulates multi-view pose correspondence matching as a hypergraph partitioning problem rather than through pairwise association. While the complexity of the resulting integer linear program grows exponentially in theory, we introduce an efficient geometric pruning strategy to substantially reduce the search space. COMPOSE achieves improvements of up to 23% in average precision over previous optimization-based methods and up to 11% over self-supervised end-to-end learned methods, offering a promising solution to a widely studied problem.
GlovEgo-HOI: Bridging the Synthetic-to-Real Gap for Industrial Egocentric Human-Object Interaction Detection
Jan 14, 2026Egocentric Human-Object Interaction (EHOI) analysis is crucial for industrial safety, yet the development of robust models is hindered by the scarcity of annotated domain-specific data. We address this challenge by introducing a data generation framework that combines synthetic data with a diffusion-based process to augment real-world images with realistic Personal Protective Equipment (PPE). We present GlovEgo-HOI, a new benchmark dataset for industrial EHOI, and GlovEgo-Net, a model integrating Glove-Head and Keypoint- Head modules to leverage hand pose information for enhanced interaction detection. Extensive experiments demonstrate the effectiveness of the proposed data generation framework and GlovEgo-Net. To foster further research, we release the GlovEgo-HOI dataset, augmentation pipeline, and pre-trained models at: GitHub project.
UnrealPose: Leveraging Game Engine Kinematics for Large-Scale Synthetic Human Pose Data
Jan 02, 2026Diverse, accurately labeled 3D human pose data is expensive and studio-bound, while in-the-wild datasets lack known ground truth. We introduce UnrealPose-Gen, an Unreal Engine 5 pipeline built on Movie Render Queue for high-quality offline rendering. Our generated frames include: (i) 3D joints in world and camera coordinates, (ii) 2D projections and COCO-style keypoints with occlusion and joint-visibility flags, (iii) person bounding boxes, and (iv) camera intrinsics and extrinsics. We use UnrealPose-Gen to present UnrealPose-1M, an approximately one million frame corpus comprising eight sequences: five scripted "coherent" sequences spanning five scenes, approximately 40 actions, and five subjects; and three randomized sequences across three scenes, approximately 100 actions, and five subjects, all captured from diverse camera trajectories for broad viewpoint coverage. As a fidelity check, we report real-to-synthetic results on four tasks: image-to-3D pose, 2D keypoint detection, 2D-to-3D lifting, and person detection/segmentation. Though time and resources constrain us from an unlimited dataset, we release the UnrealPose-1M dataset, as well as the UnrealPose-Gen pipeline to support third-party generation of human pose data.
Geometric Multi-Session Map Merging with Learned Local Descriptors
Dec 30, 2025Multi-session map merging is crucial for extended autonomous operations in large-scale environments. In this paper, we present GMLD, a learning-based local descriptor framework for large-scale multi-session point cloud map merging that systematically aligns maps collected across different sessions with overlapping regions. The proposed framework employs a keypoint-aware encoder and a plane-based geometric transformer to extract discriminative features for loop closure detection and relative pose estimation. To further improve global consistency, we include inter-session scan matching cost factors in the factor-graph optimization stage. We evaluate our framework on the public datasets, as well as self-collected data from diverse environments. The results show accurate and robust map merging with low error, and the learned features deliver strong performance in both loop closure detection and relative pose estimation.
BLANKET: Anonymizing Faces in Infant Video Recordings
Dec 17, 2025



Ensuring the ethical use of video data involving human subjects, particularly infants, requires robust anonymization methods. We propose BLANKET (Baby-face Landmark-preserving ANonymization with Keypoint dEtection consisTency), a novel approach designed to anonymize infant faces in video recordings while preserving essential facial attributes. Our method comprises two stages. First, a new random face, compatible with the original identity, is generated via inpainting using a diffusion model. Second, the new identity is seamlessly incorporated into each video frame through temporally consistent face swapping with authentic expression transfer. The method is evaluated on a dataset of short video recordings of babies and is compared to the popular anonymization method, DeepPrivacy2. Key metrics assessed include the level of de-identification, preservation of facial attributes, impact on human pose estimation (as an example of a downstream task), and presence of artifacts. Both methods alter the identity, and our method outperforms DeepPrivacy2 in all other respects. The code is available as an easy-to-use anonymization demo at https://github.com/ctu-vras/blanket-infant-face-anonym.
* Project website: https://github.com/ctu-vras/blanket-infant-face-anonym
Off The Grid: Detection of Primitives for Feed-Forward 3D Gaussian Splatting
Dec 17, 2025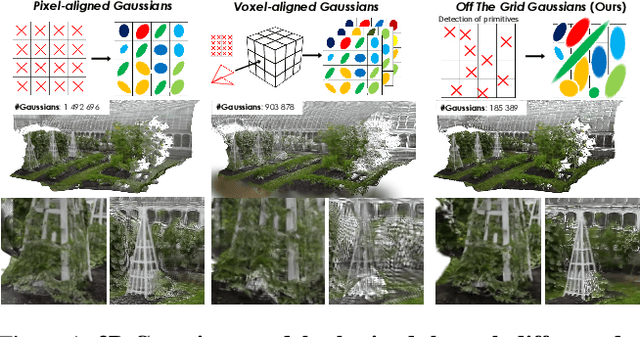
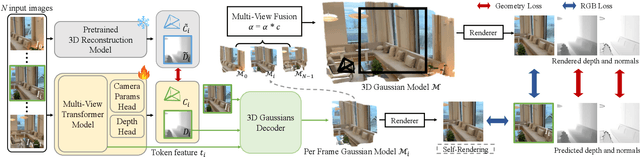


Feed-forward 3D Gaussian Splatting (3DGS) models enable real-time scene generation but are hindered by suboptimal pixel-aligned primitive placement, which relies on a dense, rigid grid and limits both quality and efficiency. We introduce a new feed-forward architecture that detects 3D Gaussian primitives at a sub-pixel level, replacing the pixel grid with an adaptive, "Off The Grid" distribution. Inspired by keypoint detection, our multi-resolution decoder learns to distribute primitives across image patches. This module is trained end-to-end with a 3D reconstruction backbone using self-supervised learning. Our resulting pose-free model generates photorealistic scenes in seconds, achieving state-of-the-art novel view synthesis for feed-forward models. It outperforms competitors while using far fewer primitives, demonstrating a more accurate and efficient allocation that captures fine details and reduces artifacts. Moreover, we observe that by learning to render 3D Gaussians, our 3D reconstruction backbone improves camera pose estimation, suggesting opportunities to train these foundational models without labels.
UnCageNet: Tracking and Pose Estimation of Caged Animal
Dec 16, 2025Animal tracking and pose estimation systems, such as STEP (Simultaneous Tracking and Pose Estimation) and ViTPose, experience substantial performance drops when processing images and videos with cage structures and systematic occlusions. We present a three-stage preprocessing pipeline that addresses this limitation through: (1) cage segmentation using a Gabor-enhanced ResNet-UNet architecture with tunable orientation filters, (2) cage inpainting using CRFill for content-aware reconstruction of occluded regions, and (3) evaluation of pose estimation and tracking on the uncaged frames. Our Gabor-enhanced segmentation model leverages orientation-aware features with 72 directional kernels to accurately identify and segment cage structures that severely impair the performance of existing methods. Experimental validation demonstrates that removing cage occlusions through our pipeline enables pose estimation and tracking performance comparable to that in environments without occlusions. We also observe significant improvements in keypoint detection accuracy and trajectory consistency.