 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRQR3D: Reparametrizing the regression targets for BEV-based 3D object detection
May 23, 2025Accurate, fast, and reliable 3D perception is essential for autonomous driving. Recently, bird's-eye view (BEV)-based perception approaches have emerged as superior alternatives to perspective-based solutions, offering enhanced spatial understanding and more natural outputs for planning. Existing BEV-based 3D object detection methods, typically adhering to angle-based representation, directly estimate the size and orientation of rotated bounding boxes. We observe that BEV-based 3D object detection is analogous to aerial oriented object detection, where angle-based methods are recognized for being affected by discontinuities in their loss functions. Drawing inspiration from this domain, we propose Restricted Quadrilateral Representation to define 3D regression targets. RQR3D regresses the smallest horizontal bounding box encapsulating the oriented box, along with the offsets between the corners of these two boxes, thereby transforming the oriented object detection problem into a keypoint regression task. RQR3D is compatible with any 3D object detection approach. We employ RQR3D within an anchor-free single-stage object detection method and introduce an objectness head to address class imbalance problem. Furthermore, we introduce a simplified radar fusion backbone that eliminates the need for voxel grouping and processes the BEV-mapped point cloud with standard 2D convolutions, rather than sparse convolutions. Extensive evaluations on the nuScenes dataset demonstrate that RQR3D achieves state-of-the-art performance in camera-radar 3D object detection, outperforming the previous best method by +4% in NDS and +2.4% in mAP, and significantly reducing the translation and orientation errors, which are crucial for safe autonomous driving. These consistent gains highlight the robustness, precision, and real-world readiness of our approach.
GLane3D : Detecting Lanes with Graph of 3D Keypoints
Mar 31, 2025Accurate and efficient lane detection in 3D space is essential for autonomous driving systems, where robust generalization is the foremost requirement for 3D lane detection algorithms. Considering the extensive variation in lane structures worldwide, achieving high generalization capacity is particularly challenging, as algorithms must accurately identify a wide variety of lane patterns worldwide. Traditional top-down approaches rely heavily on learning lane characteristics from training datasets, often struggling with lanes exhibiting previously unseen attributes. To address this generalization limitation, we propose a method that detects keypoints of lanes and subsequently predicts sequential connections between them to construct complete 3D lanes. Each key point is essential for maintaining lane continuity, and we predict multiple proposals per keypoint by allowing adjacent grids to predict the same keypoint using an offset mechanism. PointNMS is employed to eliminate overlapping proposal keypoints, reducing redundancy in the estimated BEV graph and minimizing computational overhead from connection estimations. Our model surpasses previous state-of-the-art methods on both the Apollo and OpenLane datasets, demonstrating superior F1 scores and a strong generalization capacity when models trained on OpenLane are evaluated on the Apollo dataset, compared to prior approaches.
TopoBDA: Towards Bezier Deformable Attention for Road Topology Understanding
Dec 25, 2024



Understanding road topology is crucial for autonomous driving. This paper introduces TopoBDA (Topology with Bezier Deformable Attention), a novel approach that enhances road topology understanding by leveraging Bezier Deformable Attention (BDA). BDA utilizes Bezier control points to drive the deformable attention mechanism, significantly improving the detection and representation of elongated and thin polyline structures, such as lane centerlines. TopoBDA processes multi-camera 360-degree imagery to generate Bird's Eye View (BEV) features, which are refined through a transformer decoder employing BDA. This method enhances computational efficiency while maintaining high accuracy in centerline prediction. Additionally, TopoBDA incorporates an instance mask formulation and an auxiliary one-to-many set prediction loss strategy to further refine centerline detection and improve road topology understanding. Experimental evaluations on the OpenLane-V2 dataset demonstrate that TopoBDA outperforms existing methods, achieving state-of-the-art results in centerline detection and topology reasoning. The integration of multi-modal data, including lidar and radar, specifically for road topology understanding, further enhances the model's performance, underscoring its importance in autonomous driving applications.
TopoMaskV2: Enhanced Instance-Mask-Based Formulation for the Road Topology Problem
Sep 17, 2024



Recently, the centerline has become a popular representation of lanes due to its advantages in solving the road topology problem. To enhance centerline prediction, we have developed a new approach called TopoMask. Unlike previous methods that rely on keypoints or parametric methods, TopoMask utilizes an instance-mask-based formulation coupled with a masked-attention-based transformer architecture. We introduce a quad-direction label representation to enrich the mask instances with flow information and design a corresponding post-processing technique for mask-to-centerline conversion. Additionally, we demonstrate that the instance-mask formulation provides complementary information to parametric Bezier regressions, and fusing both outputs leads to improved detection and topology performance. Moreover, we analyze the shortcomings of the pillar assumption in the Lift Splat technique and adapt a multi-height bin configuration. Experimental results show that TopoMask achieves state-of-the-art performance in the OpenLane-V2 dataset, increasing from 44.1 to 49.4 for Subset-A and 44.7 to 51.8 for Subset-B in the V1.1 OLS baseline.
TopoMask: Instance-Mask-Based Formulation for the Road Topology Problem via Transformer-Based Architecture
Jun 08, 2023



Driving scene understanding task involves detecting static elements such as lanes, traffic signs, and traffic lights, and their relationships with each other. To facilitate the development of comprehensive scene understanding solutions using multiple camera views, a new dataset called Road Genome (OpenLane-V2) has been released. This dataset allows for the exploration of complex road connections and situations where lane markings may be absent. Instead of using traditional lane markings, the lanes in this dataset are represented by centerlines, which offer a more suitable representation of lanes and their connections. In this study, we have introduced a new approach called TopoMask for predicting centerlines in road topology. Unlike existing approaches in the literature that rely on keypoints or parametric methods, TopoMask utilizes an instance-mask based formulation with a transformer-based architecture and, in order to enrich the mask instances with flow information, a direction label representation is proposed. TopoMask have ranked 4th in the OpenLane-V2 Score (OLS) and ranked 2nd in the F1 score of centerline prediction in OpenLane Topology Challenge 2023. In comparison to the current state-of-the-art method, TopoNet, the proposed method has achieved similar performance in Frechet-based lane detection and outperformed TopoNet in Chamfer-based lane detection without utilizing its scene graph neural network.
Follow the Object: Curriculum Learning for Manipulation Tasks with Imagined Goals
Aug 05, 2020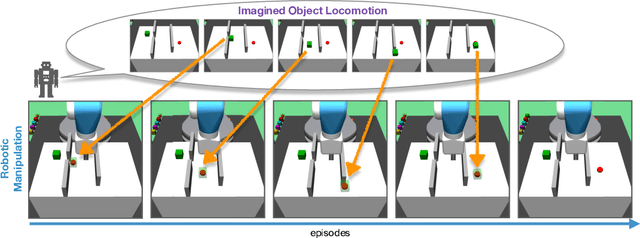


Learning robot manipulation through deep reinforcement learning in environments with sparse rewards is a challenging task. In this paper we address this problem by introducing a notion of imaginary object goals. For a given manipulation task, the object of interest is first trained to reach a desired target position on its own, without being manipulated, through physically realistic simulations. The object policy is then leveraged to build a predictive model of plausible object trajectories providing the robot with a curriculum of incrementally more difficult object goals to reach during training. The proposed algorithm, Follow the Object (FO), has been evaluated on 7 MuJoCo environments requiring increasing degree of exploration, and has achieved higher success rates compared to alternative algorithms. In particularly challenging learning scenarios, e.g. where the object's initial and target positions are far apart, our approach can still learn a policy whereas competing methods currently fail.
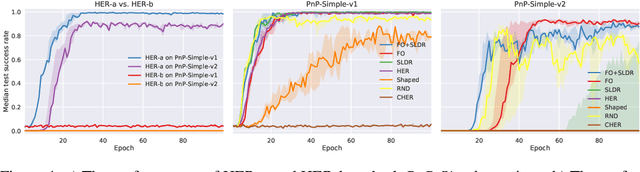
Reinforcement Learning for Robotic Manipulation using Simulated Locomotion Demonstrations
Oct 17, 2019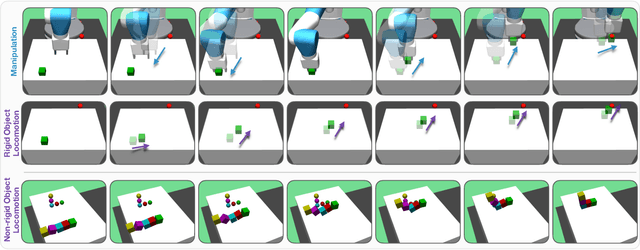
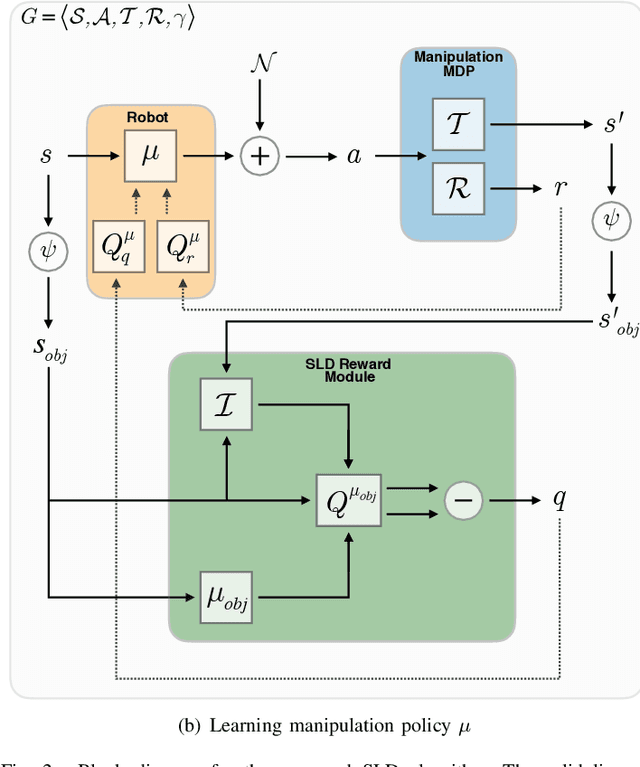
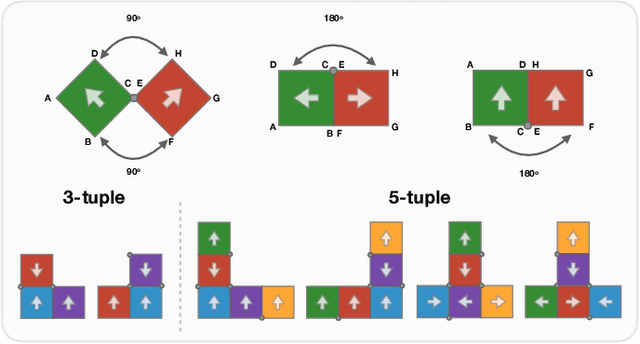
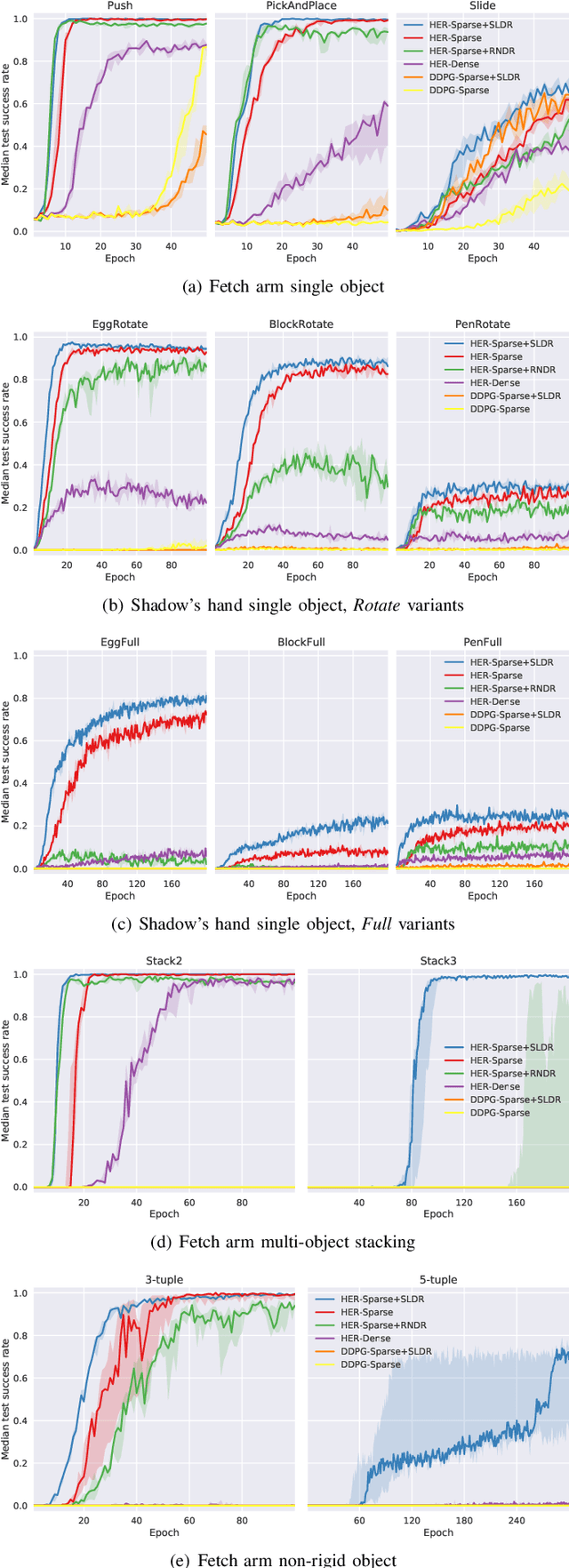
Learning robot manipulation policies through reinforcement learning (RL) with only sparse rewards is still considered a largely unsolved problem. Although learning with human demonstrations can make the training process more sample efficient, the demonstrations are often expensive to obtain, and their benefits heavily depend on the expertise of the demonstrators. In this paper we propose a novel approach for learning complex robot manipulation tasks with self-learned demonstrations. We note that a robot manipulation task can be interpreted, from the object's perspective, as a locomotion task. In a virtual world, the object might be able to learn how to move from its initial position to the final target position on its own, without being manipulated. Although objects cannot move on their own in the real world, a policy to achieve object locomotion can be learned through physically-realistic simulators, which are nowadays widely available and routinely adopted to train RL systems. The resulting object-level trajectories are called Simulated Locomotion Demonstrations (SLD). The SLDs are then leveraged to learn the robot manipulation policy through deep RL using only sparse rewards. We thoroughly evaluate the proposed approach on 13 tasks of increasing complexity, and demonstrate that our framework can result in faster learning rates and achieve higher success rate compared to alternative algorithms. We demonstrate that SLDs are especially beneficial for complex tasks like multi-object stacking and non-rigid object manipulation.
Multi-agent Deep Reinforcement Learning with Extremely Noisy Observations
Dec 03, 2018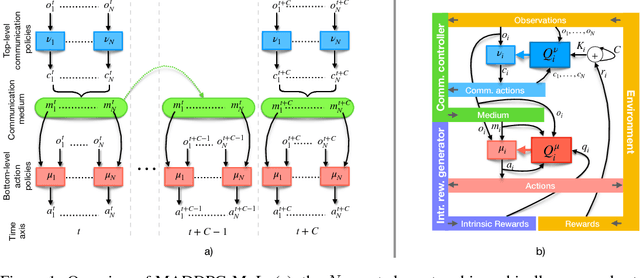
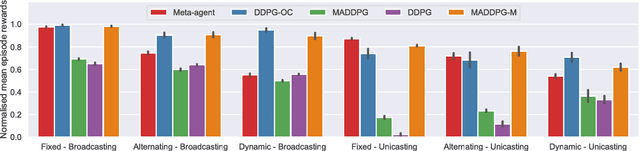


Multi-agent reinforcement learning systems aim to provide interacting agents with the ability to collaboratively learn and adapt to the behaviour of other agents. In many real-world applications, the agents can only acquire a partial view of the world. Here we consider a setting whereby most agents' observations are also extremely noisy, hence only weakly correlated to the true state of the environment. Under these circumstances, learning an optimal policy becomes particularly challenging, even in the unrealistic case that an agent's policy can be made conditional upon all other agents' observations. To overcome these difficulties, we propose a multi-agent deep deterministic policy gradient algorithm enhanced by a communication medium (MADDPG-M), which implements a two-level, concurrent learning mechanism. An agent's policy depends on its own private observations as well as those explicitly shared by others through a communication medium. At any given point in time, an agent must decide whether its private observations are sufficiently informative to be shared with others. However, our environments provide no explicit feedback informing an agent whether a communication action is beneficial, rather the communication policies must also be learned through experience concurrently to the main policies. Our experimental results demonstrate that the algorithm performs well in six highly non-stationary environments of progressively higher complexity, and offers substantial performance gains compared to the baselines.
GAR: An efficient and scalable Graph-based Activity Regularization for semi-supervised learning
Feb 08, 2018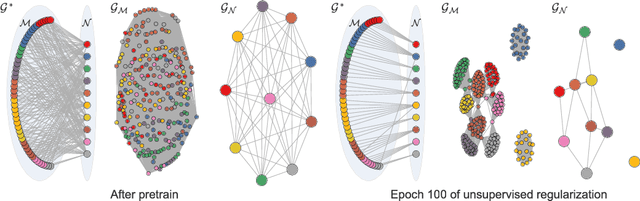

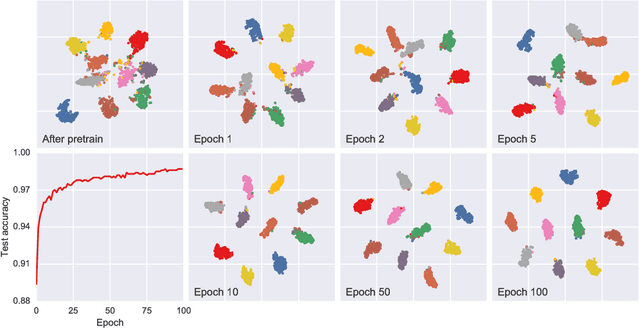
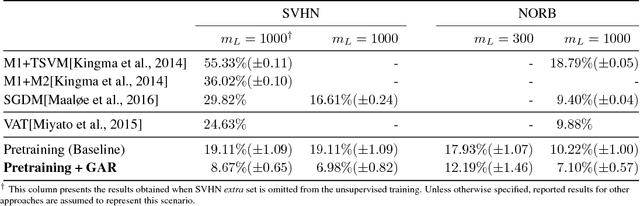
In this paper, we propose a novel graph-based approach for semi-supervised learning problems, which considers an adaptive adjacency of the examples throughout the unsupervised portion of the training. Adjacency of the examples is inferred using the predictions of a neural network model which is first initialized by a supervised pretraining. These predictions are then updated according to a novel unsupervised objective which regularizes another adjacency, now linking the output nodes. Regularizing the adjacency of the output nodes, inferred from the predictions of the network, creates an easier optimization problem and ultimately provides that the predictions of the network turn into the optimal embedding. Ultimately, the proposed framework provides an effective and scalable graph-based solution which is natural to the operational mechanism of deep neural networks. Our results show comparable performance with state-of-the-art generative approaches for semi-supervised learning on an easier-to-train, low-cost framework.
Learning Latent Representations in Neural Networks for Clustering through Pseudo Supervision and Graph-based Activity Regularization
Feb 08, 2018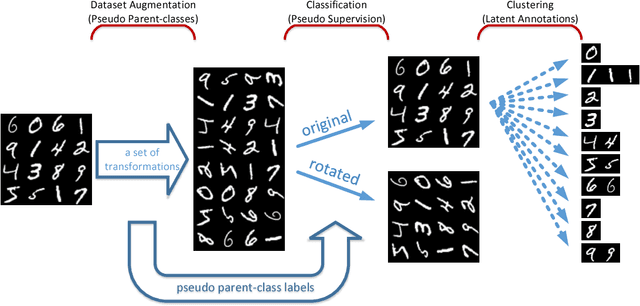

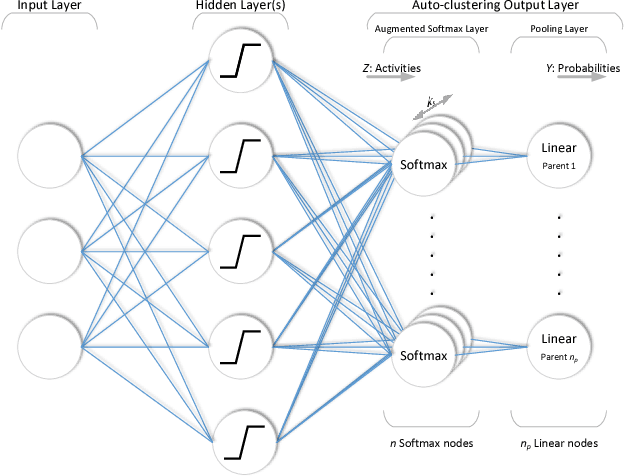
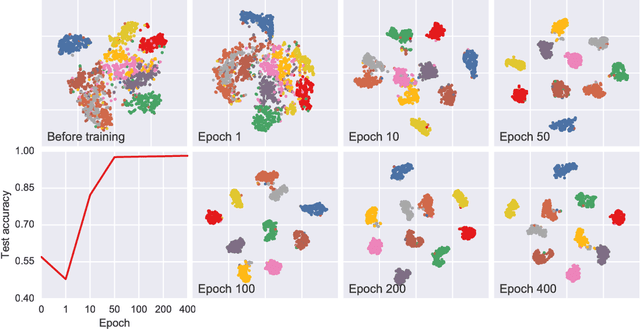
In this paper, we propose a novel unsupervised clustering approach exploiting the hidden information that is indirectly introduced through a pseudo classification objective. Specifically, we randomly assign a pseudo parent-class label to each observation which is then modified by applying the domain specific transformation associated with the assigned label. Generated pseudo observation-label pairs are subsequently used to train a neural network with Auto-clustering Output Layer (ACOL) that introduces multiple softmax nodes for each pseudo parent-class. Due to the unsupervised objective based on Graph-based Activity Regularization (GAR) terms, softmax duplicates of each parent-class are specialized as the hidden information captured through the help of domain specific transformations is propagated during training. Ultimately we obtain a k-means friendly latent representation. Furthermore, we demonstrate how the chosen transformation type impacts performance and helps propagate the latent information that is useful in revealing unknown clusters. Our results show state-of-the-art performance for unsupervised clustering tasks on MNIST, SVHN and USPS datasets, with the highest accuracies reported to date in the literature.