 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning for Robotic Manipulation using Simulated Locomotion Demonstrations
Paper and Code
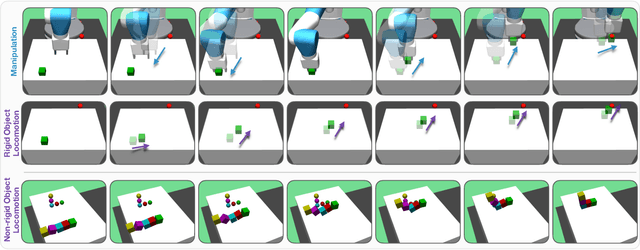
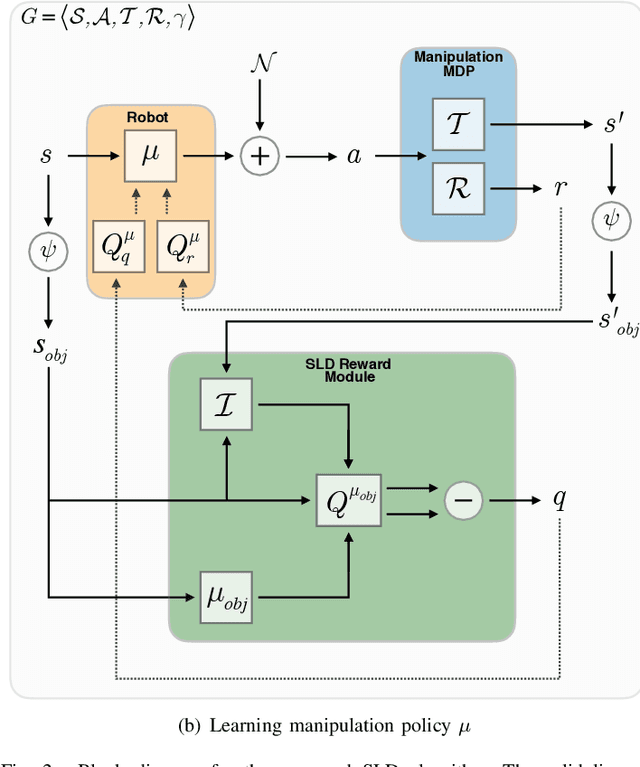
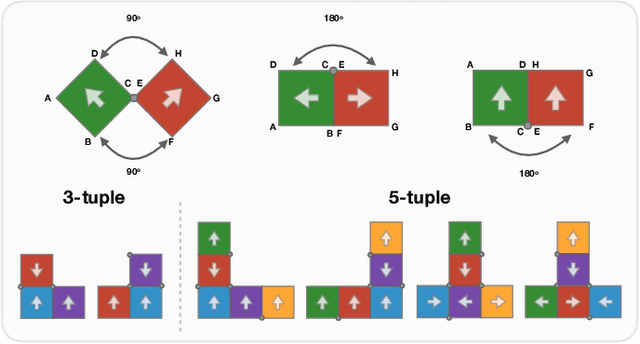
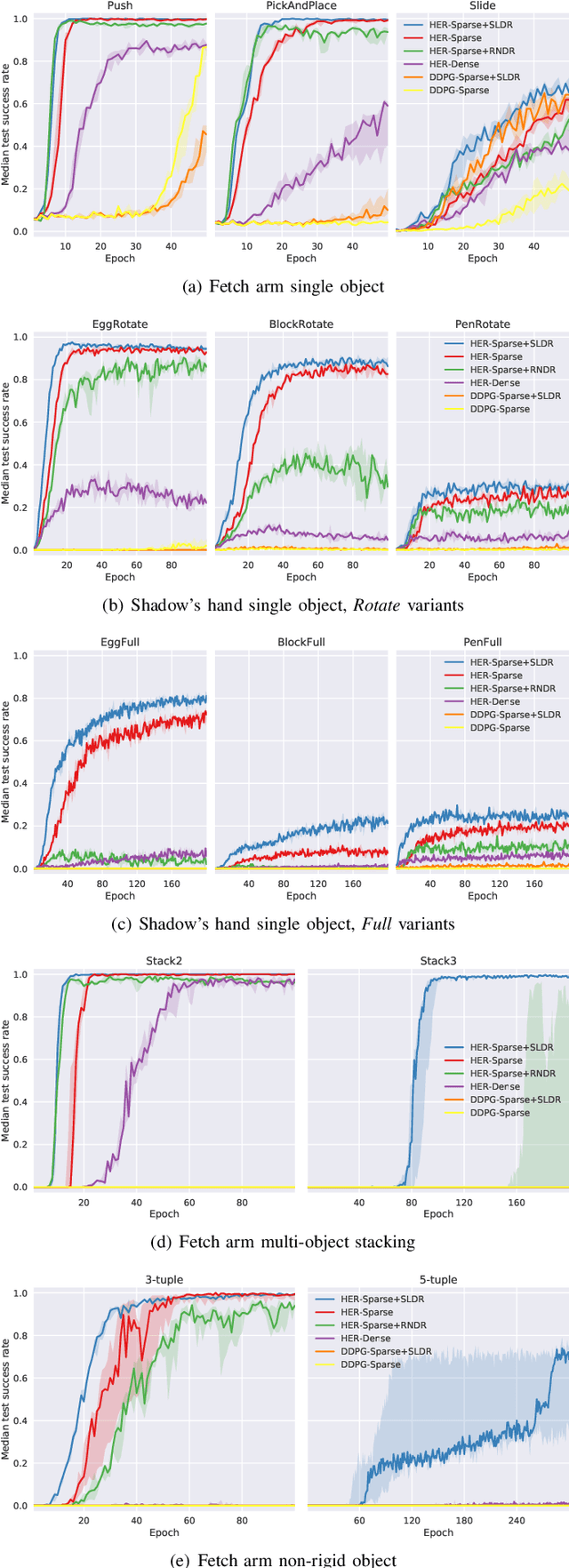
Learning robot manipulation policies through reinforcement learning (RL) with only sparse rewards is still considered a largely unsolved problem. Although learning with human demonstrations can make the training process more sample efficient, the demonstrations are often expensive to obtain, and their benefits heavily depend on the expertise of the demonstrators. In this paper we propose a novel approach for learning complex robot manipulation tasks with self-learned demonstrations. We note that a robot manipulation task can be interpreted, from the object's perspective, as a locomotion task. In a virtual world, the object might be able to learn how to move from its initial position to the final target position on its own, without being manipulated. Although objects cannot move on their own in the real world, a policy to achieve object locomotion can be learned through physically-realistic simulators, which are nowadays widely available and routinely adopted to train RL systems. The resulting object-level trajectories are called Simulated Locomotion Demonstrations (SLD). The SLDs are then leveraged to learn the robot manipulation policy through deep RL using only sparse rewards. We thoroughly evaluate the proposed approach on 13 tasks of increasing complexity, and demonstrate that our framework can result in faster learning rates and achieve higher success rate compared to alternative algorithms. We demonstrate that SLDs are especially beneficial for complex tasks like multi-object stacking and non-rigid object manipulation.