 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-agent Deep Reinforcement Learning with Extremely Noisy Observations
Paper and Code
Dec 03, 2018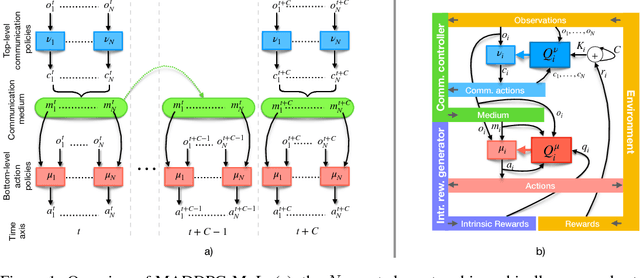
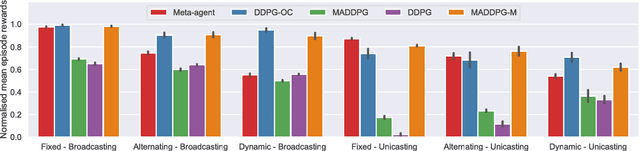


Multi-agent reinforcement learning systems aim to provide interacting agents with the ability to collaboratively learn and adapt to the behaviour of other agents. In many real-world applications, the agents can only acquire a partial view of the world. Here we consider a setting whereby most agents' observations are also extremely noisy, hence only weakly correlated to the true state of the environment. Under these circumstances, learning an optimal policy becomes particularly challenging, even in the unrealistic case that an agent's policy can be made conditional upon all other agents' observations. To overcome these difficulties, we propose a multi-agent deep deterministic policy gradient algorithm enhanced by a communication medium (MADDPG-M), which implements a two-level, concurrent learning mechanism. An agent's policy depends on its own private observations as well as those explicitly shared by others through a communication medium. At any given point in time, an agent must decide whether its private observations are sufficiently informative to be shared with others. However, our environments provide no explicit feedback informing an agent whether a communication action is beneficial, rather the communication policies must also be learned through experience concurrently to the main policies. Our experimental results demonstrate that the algorithm performs well in six highly non-stationary environments of progressively higher complexity, and offers substantial performance gains compared to the baselines.