 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Human Activity Recognition: A Unified Review of Concepts and Mechanisms
Apr 10, 2026Human activity recognition (HAR) has become a key component of intelligent systems for healthcare monitoring, assistive living, smart environments, and human-computer interaction. Although deep learning has substantially improved HAR performance on multivariate sensor data, the resulting models often remain opaque, limiting trust, reliability, and real-world deployment. Explainable artificial intelligence (XAI) has therefore emerged as a critical direction for making HAR systems more transparent and human-centered. This paper presents a comprehensive review of explainable HAR methods across wearable, ambient, physiological, and multimodal sensing settings. We introduce a unified perspective that separates conceptual dimensions of explainability from algorithmic explanation mechanisms, reducing ambiguities in prior surveys. Building on this distinction, we present a mechanism-centric taxonomy of XAI-HAR methods covering major explanation paradigms. The review examines how these methods address the temporal, multimodal, and semantic complexities of HAR, and summarize their interpretability objectives, explanation targets, and limitations. In addition, we discuss current evaluation practices, highlight key challenges in achieving reliable and deployable XAI-HAR, and outline directions toward trustworthy activity recognition systems that better support human understanding and decision-making.
A Time-Temperature Dataset for the Strawberry Cold Chain Across Multiple Shipments and Locations
Mar 23, 2021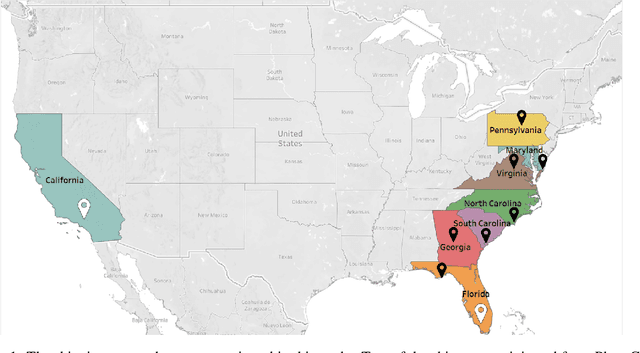

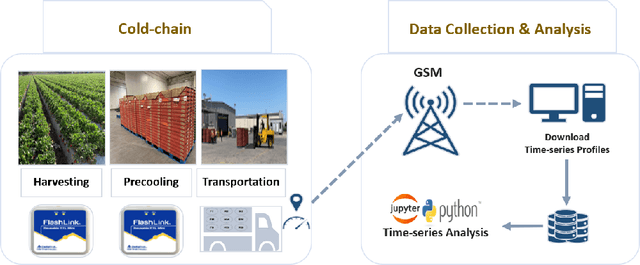
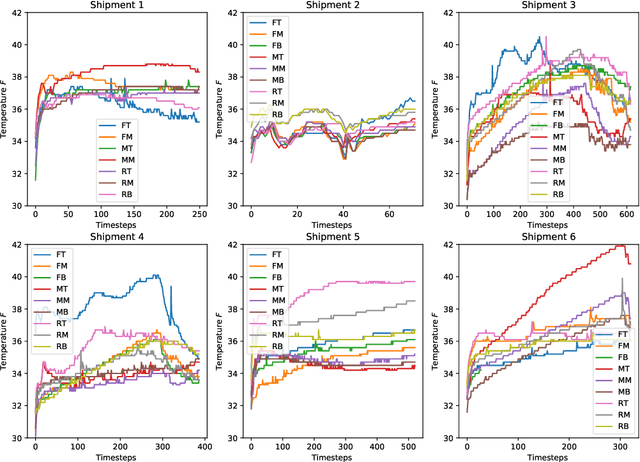
This article describes location aware temperature profiles from six strawberry shipments across the continental United States. Three pallets were instrumented in each shipment with three vertically placed loggers to take a longitudinal and latitudinal snapshot of 9 strategically different locations (including the top, middle and bottom layers of the pallets placed in the back, middle and the front of the shipping container) for a combined 54 measurement points across shipments of varying lengths. The sensors were instrumented in the field, right at the point of harvest, recorded temperatures every every 5 to 10 minutes depending on the shipment, and uploaded their data periodically via cellular radios on each device. The data is a result of significant collaboration between stakeholders from farmers to distributors to retailers to academics, which can play an important role for researchers and educators in food engineering, cold-chain, machine learning, and data mining, as well as in other disciplines related to food and transportation.
GAR: An efficient and scalable Graph-based Activity Regularization for semi-supervised learning
Feb 08, 2018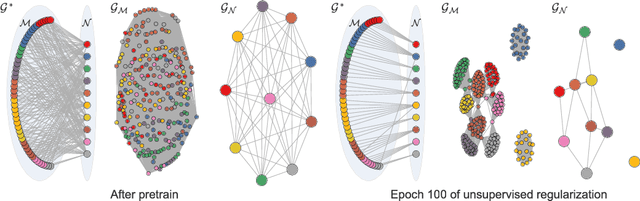

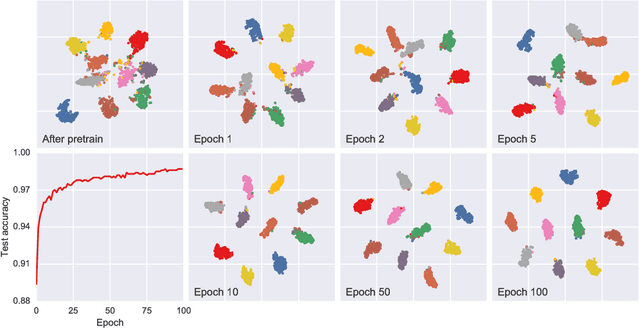
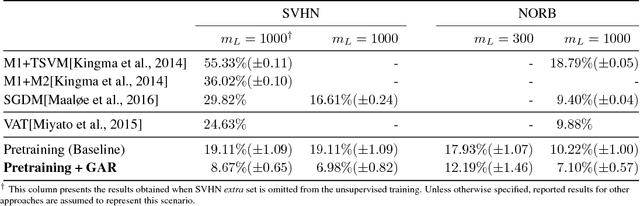
In this paper, we propose a novel graph-based approach for semi-supervised learning problems, which considers an adaptive adjacency of the examples throughout the unsupervised portion of the training. Adjacency of the examples is inferred using the predictions of a neural network model which is first initialized by a supervised pretraining. These predictions are then updated according to a novel unsupervised objective which regularizes another adjacency, now linking the output nodes. Regularizing the adjacency of the output nodes, inferred from the predictions of the network, creates an easier optimization problem and ultimately provides that the predictions of the network turn into the optimal embedding. Ultimately, the proposed framework provides an effective and scalable graph-based solution which is natural to the operational mechanism of deep neural networks. Our results show comparable performance with state-of-the-art generative approaches for semi-supervised learning on an easier-to-train, low-cost framework.
Learning Latent Representations in Neural Networks for Clustering through Pseudo Supervision and Graph-based Activity Regularization
Feb 08, 2018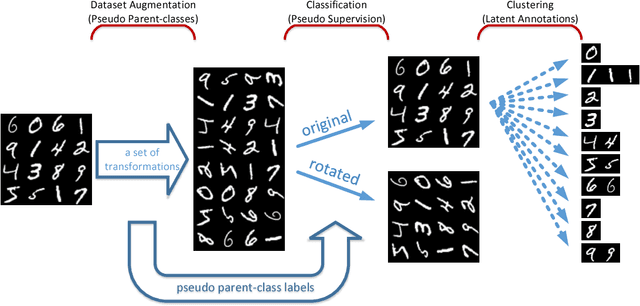

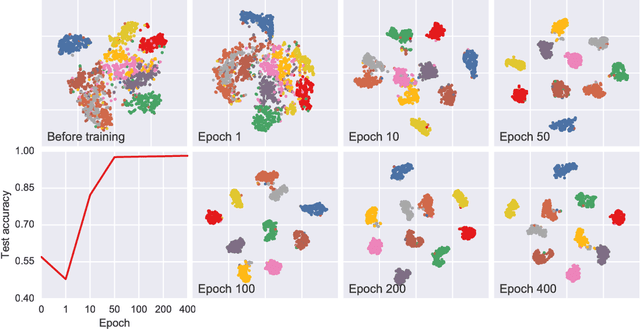
In this paper, we propose a novel unsupervised clustering approach exploiting the hidden information that is indirectly introduced through a pseudo classification objective. Specifically, we randomly assign a pseudo parent-class label to each observation which is then modified by applying the domain specific transformation associated with the assigned label. Generated pseudo observation-label pairs are subsequently used to train a neural network with Auto-clustering Output Layer (ACOL) that introduces multiple softmax nodes for each pseudo parent-class. Due to the unsupervised objective based on Graph-based Activity Regularization (GAR) terms, softmax duplicates of each parent-class are specialized as the hidden information captured through the help of domain specific transformations is propagated during training. Ultimately we obtain a k-means friendly latent representation. Furthermore, we demonstrate how the chosen transformation type impacts performance and helps propagate the latent information that is useful in revealing unknown clusters. Our results show state-of-the-art performance for unsupervised clustering tasks on MNIST, SVHN and USPS datasets, with the highest accuracies reported to date in the literature.
Auto-clustering Output Layer: Automatic Learning of Latent Annotations in Neural Networks
Aug 09, 2017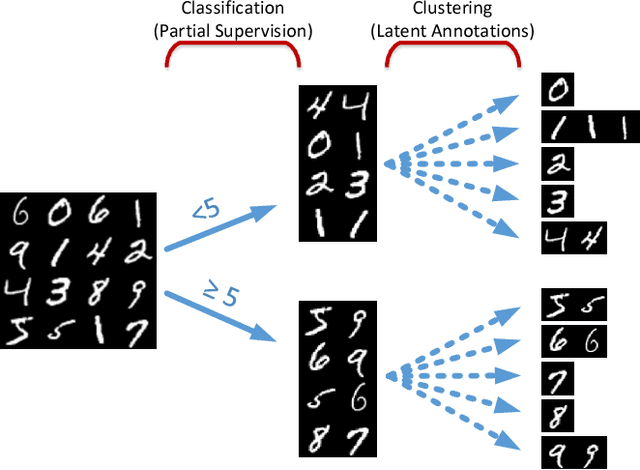
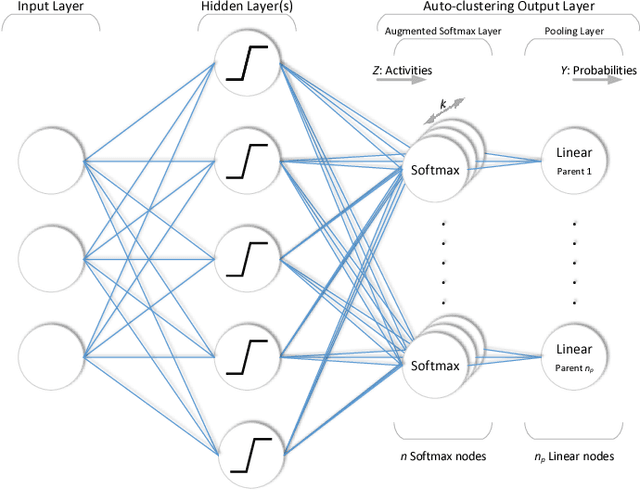
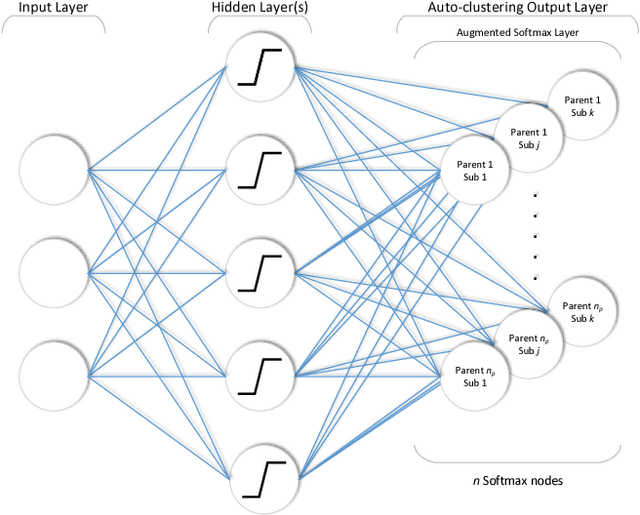
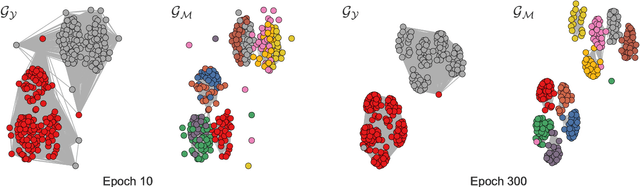
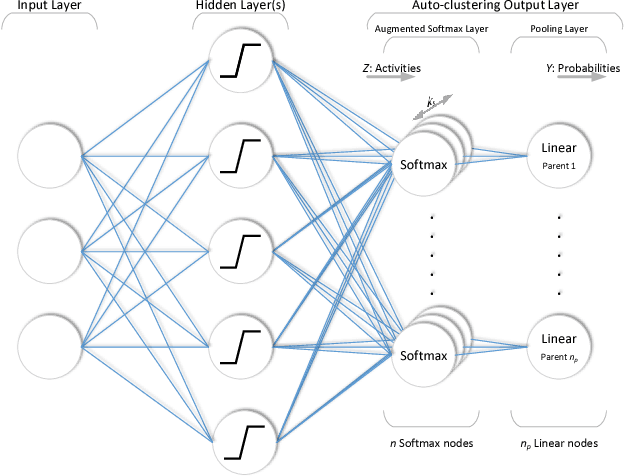
In this paper, we discuss a different type of semi-supervised setting: a coarse level of labeling is available for all observations but the model has to learn a fine level of latent annotation for each one of them. Problems in this setting are likely to be encountered in many domains such as text categorization, protein function prediction, image classification as well as in exploratory scientific studies such as medical and genomics research. We consider this setting as simultaneously performed supervised classification (per the available coarse labels) and unsupervised clustering (within each one of the coarse labels) and propose a novel output layer modification called auto-clustering output layer (ACOL) that allows concurrent classification and clustering based on Graph-based Activity Regularization (GAR) technique. As the proposed output layer modification duplicates the softmax nodes at the output layer for each class, GAR allows for competitive learning between these duplicates on a traditional error-correction learning framework to ultimately enable a neural network to learn the latent annotations in this partially supervised setup. We demonstrate how the coarse label supervision impacts performance and helps propagate useful clustering information between sub-classes. Comparative tests on three of the most popular image datasets MNIST, SVHN and CIFAR-100 rigorously demonstrate the effectiveness and competitiveness of the proposed approach.
Clustering-based Source-aware Assessment of True Robustness for Learning Models
Apr 01, 2017
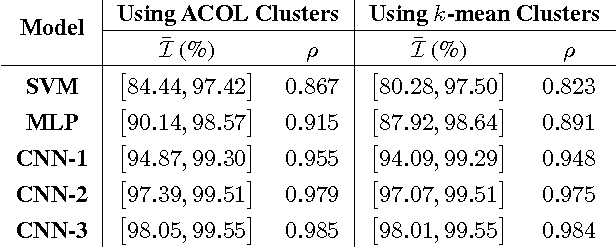
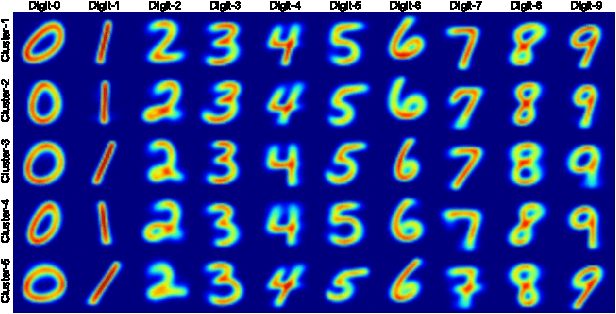
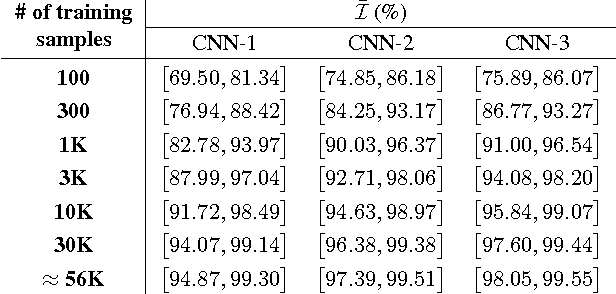
We introduce a novel validation framework to measure the true robustness of learning models for real-world applications by creating source-inclusive and source-exclusive partitions in a dataset via clustering. We develop a robustness metric derived from source-aware lower and upper bounds of model accuracy even when data source labels are not readily available. We clearly demonstrate that even on a well-explored dataset like MNIST, challenging training scenarios can be constructed under the proposed assessment framework for two separate yet equally important applications: i) more rigorous learning model comparison and ii) dataset adequacy evaluation. In addition, our findings not only promise a more complete identification of trade-offs between model complexity, accuracy and robustness but can also help researchers optimize their efforts in data collection by identifying the less robust and more challenging class labels.