 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClustering-based Source-aware Assessment of True Robustness for Learning Models
Paper and Code
Apr 01, 2017
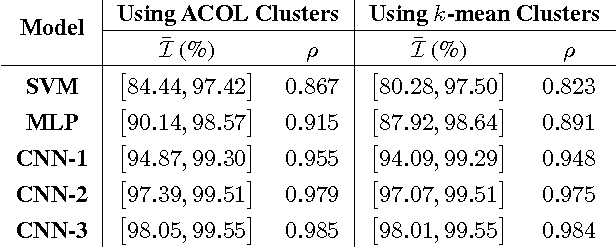
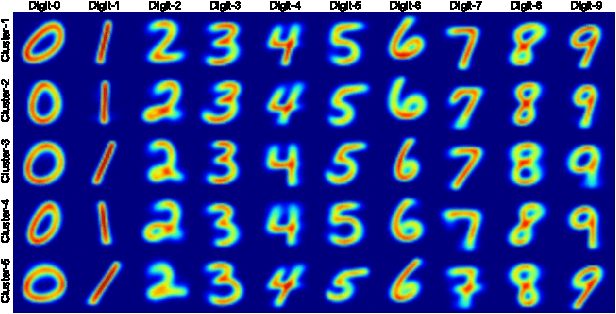
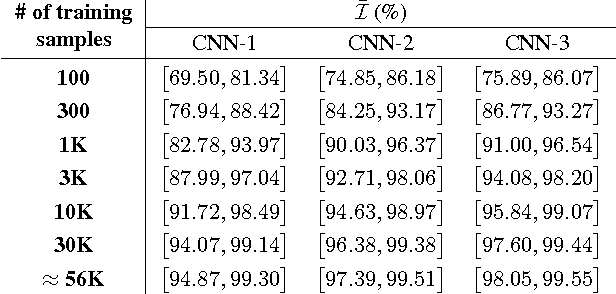
We introduce a novel validation framework to measure the true robustness of learning models for real-world applications by creating source-inclusive and source-exclusive partitions in a dataset via clustering. We develop a robustness metric derived from source-aware lower and upper bounds of model accuracy even when data source labels are not readily available. We clearly demonstrate that even on a well-explored dataset like MNIST, challenging training scenarios can be constructed under the proposed assessment framework for two separate yet equally important applications: i) more rigorous learning model comparison and ii) dataset adequacy evaluation. In addition, our findings not only promise a more complete identification of trade-offs between model complexity, accuracy and robustness but can also help researchers optimize their efforts in data collection by identifying the less robust and more challenging class labels.