 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrammatical Error Correction
Grammatical error correction (GEC) is the task of correcting different kinds of errors in text such as spelling, punctuation, grammatical, and word-choice errors.
Papers and Code
Grammatical Error Correction Evaluation by Optimally Transporting Edit Representation
Feb 05, 2026Automatic evaluation in grammatical error correction (GEC) is crucial for selecting the best-performing systems. Currently, reference-based metrics are a popular choice, which basically measure the similarity between hypothesis and reference sentences. However, similarity measures based on embeddings, such as BERTScore, are often ineffective, since many words in the source sentences remain unchanged in both the hypothesis and the reference. This study focuses on edits specifically designed for GEC, i.e., ERRANT, and computes similarity measured over the edits from the source sentence. To this end, we propose edit vector, a representation for an edit, and introduce a new metric, UOT-ERRANT, which transports these edit vectors from hypothesis to reference using unbalanced optimal transport. Experiments with SEEDA meta-evaluation show that UOT-ERRANT improves evaluation performance, particularly in the +Fluency domain where many edits occur. Moreover, our method is highly interpretable because the transport plan can be interpreted as a soft edit alignment, making UOT-ERRANT a useful metric for both system ranking and analyzing GEC systems. Our code is available from https://github.com/gotutiyan/uot-errant.
NADIR: Differential Attention Flow for Non-Autoregressive Transliteration in Indic Languages
Jan 18, 2026In this work, we argue that not all sequence-to-sequence tasks require the strong inductive biases of autoregressive (AR) models. Tasks like multilingual transliteration, code refactoring, grammatical correction or text normalization often rely on local dependencies where the full modeling capacity of AR models can be overkill, creating a trade-off between their high accuracy and high inference latency. While non-autoregressive (NAR) models offer speed, they typically suffer from hallucinations and poor length control. To explore this trade-off, we focus on the multilingual transliteration task in Indic languages and introduce NADIR, a novel NAR architecture designed to strike a balance between speed and accuracy. NADIR integrates a Differential Transformer and a Mixture-of-Experts mechanism, enabling it to robustly model complex character mappings without sequential dependencies. NADIR achieves over a 13x speed-up compared to the state-of-the-art AR baseline. It maintains a competitive mean Character Error Rate of 15.78%, compared to 14.44% for the AR model and 21.88% for a standard NAR equivalent. Importantly, NADIR reduces Repetition errors by 49.53%, Substitution errors by 24.45%, Omission errors by 32.92%, and Insertion errors by 16.87%. This work provides a practical blueprint for building fast and reliable NAR systems, effectively bridging the gap between AR accuracy and the demands of real-time, large-scale deployment.
ArbESC+: Arabic Enhanced Edit Selection System Combination for Grammatical Error Correction Resolving conflict and improving system combination in Arabic GEC
Nov 18, 2025Grammatical Error Correction (GEC) is an important aspect of natural language processing. Arabic has a complicated morphological and syntactic structure, posing a greater challenge than other languages. Even though modern neural models have improved greatly in recent years, the majority of previous attempts used individual models without taking into account the potential benefits of combining different systems. In this paper, we present one of the first multi-system approaches for correcting grammatical errors in Arabic, the Arab Enhanced Edit Selection System Complication (ArbESC+). Several models are used to collect correction proposals, which are represented as numerical features in the framework. A classifier determines and implements the appropriate corrections based on these features. In order to improve output quality, the framework uses support techniques to filter overlapping corrections and estimate decision reliability. A combination of AraT5, ByT5, mT5, AraBART, AraBART+Morph+GEC, and Text editing systems gave better results than a single model alone, with F0.5 at 82.63% on QALB-14 test data, 84.64% on QALB-15 L1 data, and 65.55% on QALB-15 L2 data. As one of the most significant contributions of this work, it's the first Arab attempt to integrate linguistic error correction. Improving existing models provides a practical step towards developing advanced tools that will benefit users and researchers of Arabic text processing.
IndicGEC: Powerful Models, or a Measurement Mirage?
Nov 19, 2025In this paper, we report the results of the TeamNRC's participation in the BHASHA-Task 1 Grammatical Error Correction shared task https://github.com/BHASHA-Workshop/IndicGEC2025/ for 5 Indian languages. Our approach, focusing on zero/few-shot prompting of language models of varying sizes (4B to large proprietary models) achieved a Rank 4 in Telugu and Rank 2 in Hindi with GLEU scores of 83.78 and 84.31 respectively. In this paper, we extend the experiments to the other three languages of the shared task - Tamil, Malayalam and Bangla, and take a closer look at the data quality and evaluation metric used. Our results primarily highlight the potential of small language models, and summarize the concerns related to creating good quality datasets and appropriate metrics for this task that are suitable for Indian language scripts.
Introducing OmniGEC: A Silver Multilingual Dataset for Grammatical Error Correction
Sep 18, 2025



In this paper, we introduce OmniGEC, a collection of multilingual silver-standard datasets for the task of Grammatical Error Correction (GEC), covering eleven languages: Czech, English, Estonian, German, Greek, Icelandic, Italian, Latvian, Slovene, Swedish, and Ukrainian. These datasets facilitate the development of multilingual GEC solutions and help bridge the data gap in adapting English GEC solutions to multilingual GEC. The texts in the datasets originate from three sources: Wikipedia edits for the eleven target languages, subreddits from Reddit in the eleven target languages, and the Ukrainian-only UberText 2.0 social media corpus. While Wikipedia edits were derived from human-made corrections, the Reddit and UberText 2.0 data were automatically corrected with the GPT-4o-mini model. The quality of the corrections in the datasets was evaluated both automatically and manually. Finally, we fine-tune two open-source large language models - Aya-Expanse (8B) and Gemma-3 (12B) - on the multilingual OmniGEC corpora and achieve state-of-the-art (SOTA) results for paragraph-level multilingual GEC. The dataset collection and the best-performing models are available on Hugging Face.
Harnessing Rule-Based Reinforcement Learning for Enhanced Grammatical Error Correction
Aug 26, 2025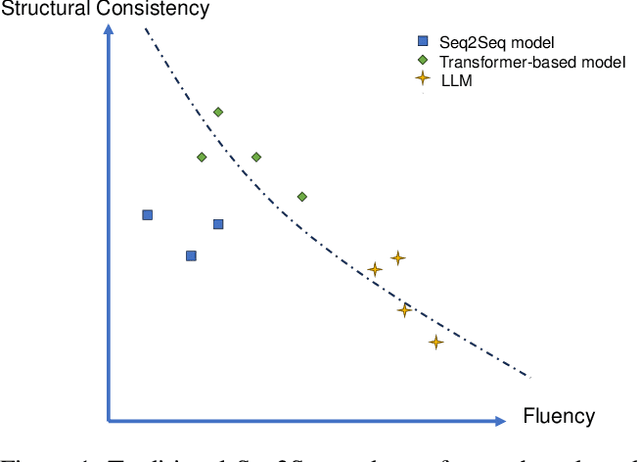

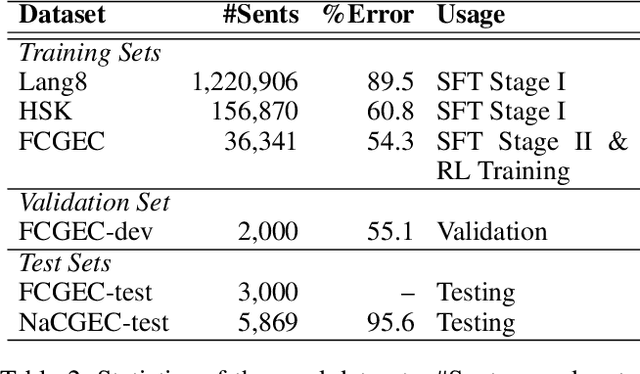

Grammatical error correction is a significant task in NLP. Traditional methods based on encoder-decoder models have achieved certain success, but the application of LLMs in this field is still underexplored. Current research predominantly relies on supervised fine-tuning to train LLMs to directly generate the corrected sentence, which limits the model's powerful reasoning ability. To address this limitation, we propose a novel framework based on Rule-Based RL. Through experiments on the Chinese datasets, our Rule-Based RL framework achieves \textbf{state-of-the-art }performance, with a notable increase in \textbf{recall}. This result clearly highlights the advantages of using RL to steer LLMs, offering a more controllable and reliable paradigm for future development in GEC.
COLA-GEC: A Bidirectional Framework for Enhancing Grammatical Acceptability and Error Correction
Jul 16, 2025Grammatical Error Correction (GEC) and grammatical acceptability judgment (COLA) are core tasks in natural language processing, sharing foundational grammatical knowledge yet typically evolving independently. This paper introduces COLA-GEC, a novel bidirectional framework that enhances both tasks through mutual knowledge transfer. First, we augment grammatical acceptability models using GEC datasets, significantly improving their performance across multiple languages. Second, we integrate grammatical acceptability signals into GEC model training via a dynamic loss function, effectively guiding corrections toward grammatically acceptable outputs. Our approach achieves state-of-the-art results on several multilingual benchmarks. Comprehensive error analysis highlights remaining challenges, particularly in punctuation error correction, providing insights for future improvements in grammatical modeling.
Adapting LLMs for Minimal-edit Grammatical Error Correction
Jun 16, 2025Decoder-only large language models have shown superior performance in the fluency-edit English Grammatical Error Correction, but their adaptation for minimal-edit English GEC is still underexplored. To improve their effectiveness in the minimal-edit approach, we explore the error rate adaptation topic and propose a novel training schedule method. Our experiments set a new state-of-the-art result for a single-model system on the BEA-test set. We also detokenize the most common English GEC datasets to match the natural way of writing text. During the process, we find that there are errors in them. Our experiments analyze whether training on detokenized datasets impacts the results and measure the impact of the usage of the datasets with corrected erroneous examples. To facilitate reproducibility, we have released the source code used to train our models.
Bridging ASR and LLMs for Dysarthric Speech Recognition: Benchmarking Self-Supervised and Generative Approaches
Aug 11, 2025


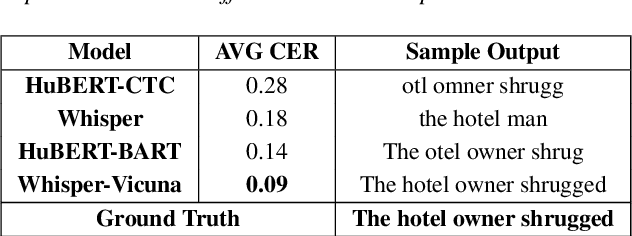
Speech Recognition (ASR) due to phoneme distortions and high variability. While self-supervised ASR models like Wav2Vec, HuBERT, and Whisper have shown promise, their effectiveness in dysarthric speech remains unclear. This study systematically benchmarks these models with different decoding strategies, including CTC, seq2seq, and LLM-enhanced decoding (BART,GPT-2, Vicuna). Our contributions include (1) benchmarking ASR architectures for dysarthric speech, (2) introducing LLM-based decoding to improve intelligibility, (3) analyzing generalization across datasets, and (4) providing insights into recognition errors across severity levels. Findings highlight that LLM-enhanced decoding improves dysarthric ASR by leveraging linguistic constraints for phoneme restoration and grammatical correction.
KoGEC : Korean Grammatical Error Correction with Pre-trained Translation Models
Jun 13, 2025This research introduces KoGEC, a Korean Grammatical Error Correction system using pre\--trained translation models. We fine-tuned NLLB (No Language Left Behind) models for Korean GEC, comparing their performance against large language models like GPT-4 and HCX-3. The study used two social media conversation datasets for training and testing. The NLLB models were fine-tuned using special language tokens to distinguish between original and corrected Korean sentences. Evaluation was done using BLEU scores and an "LLM as judge" method to classify error types. Results showed that the fine-tuned NLLB (KoGEC) models outperformed GPT-4o and HCX-3 in Korean GEC tasks. KoGEC demonstrated a more balanced error correction profile across various error types, whereas the larger LLMs tended to focus less on punctuation errors. We also developed a Chrome extension to make the KoGEC system accessible to users. Finally, we explored token vocabulary expansion to further improve the model but found it to decrease model performance. This research contributes to the field of NLP by providing an efficient, specialized Korean GEC system and a new evaluation method. It also highlights the potential of compact, task-specific models to compete with larger, general-purpose language models in specialized NLP tasks.
* 11 pages, 2 figures