 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArbESC+: Arabic Enhanced Edit Selection System Combination for Grammatical Error Correction Resolving conflict and improving system combination in Arabic GEC
Nov 18, 2025Grammatical Error Correction (GEC) is an important aspect of natural language processing. Arabic has a complicated morphological and syntactic structure, posing a greater challenge than other languages. Even though modern neural models have improved greatly in recent years, the majority of previous attempts used individual models without taking into account the potential benefits of combining different systems. In this paper, we present one of the first multi-system approaches for correcting grammatical errors in Arabic, the Arab Enhanced Edit Selection System Complication (ArbESC+). Several models are used to collect correction proposals, which are represented as numerical features in the framework. A classifier determines and implements the appropriate corrections based on these features. In order to improve output quality, the framework uses support techniques to filter overlapping corrections and estimate decision reliability. A combination of AraT5, ByT5, mT5, AraBART, AraBART+Morph+GEC, and Text editing systems gave better results than a single model alone, with F0.5 at 82.63% on QALB-14 test data, 84.64% on QALB-15 L1 data, and 65.55% on QALB-15 L2 data. As one of the most significant contributions of this work, it's the first Arab attempt to integrate linguistic error correction. Improving existing models provides a practical step towards developing advanced tools that will benefit users and researchers of Arabic text processing.
Towards the Development of Balanced Synthetic Data for Correcting Grammatical Errors in Arabic: An Approach Based on Error Tagging Model and Synthetic Data Generating Model
Feb 07, 2025Synthetic data generation is widely recognized as a way to enhance the quality of neural grammatical error correction (GEC) systems. However, current approaches often lack diversity or are too simplistic to generate the wide range of grammatical errors made by humans, especially for low-resource languages such as Arabic. In this paper, we will develop the error tagging model and the synthetic data generation model to create a large synthetic dataset in Arabic for grammatical error correction. In the error tagging model, the correct sentence is categorized into multiple error types by using the DeBERTav3 model. Arabic Error Type Annotation tool (ARETA) is used to guide multi-label classification tasks in an error tagging model in which each sentence is classified into 26 error tags. The synthetic data generation model is a back-translation-based model that generates incorrect sentences by appending error tags before the correct sentence that was generated from the error tagging model using the ARAT5 model. In the QALB-14 and QALB-15 Test sets, the error tagging model achieved 94.42% F1, which is state-of-the-art in identifying error tags in clean sentences. As a result of our syntactic data training in grammatical error correction, we achieved a new state-of-the-art result of F1-Score: 79.36% in the QALB-14 Test set. We generate 30,219,310 synthetic sentence pairs by using a synthetic data generation model.
Tibyan Corpus: Balanced and Comprehensive Error Coverage Corpus Using ChatGPT for Arabic Grammatical Error Correction
Nov 07, 2024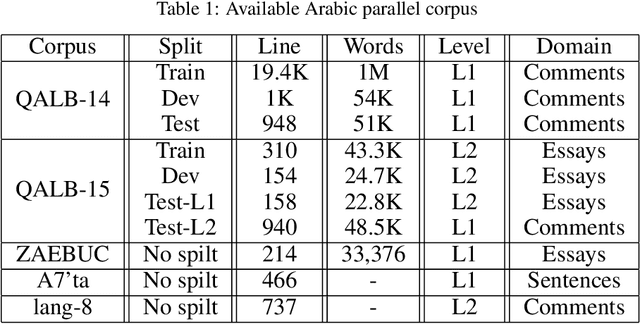
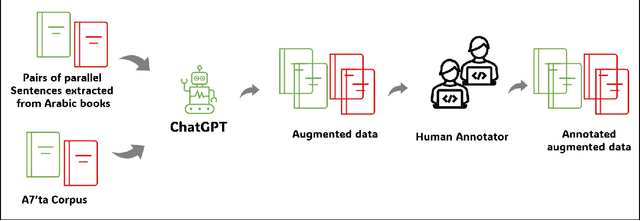
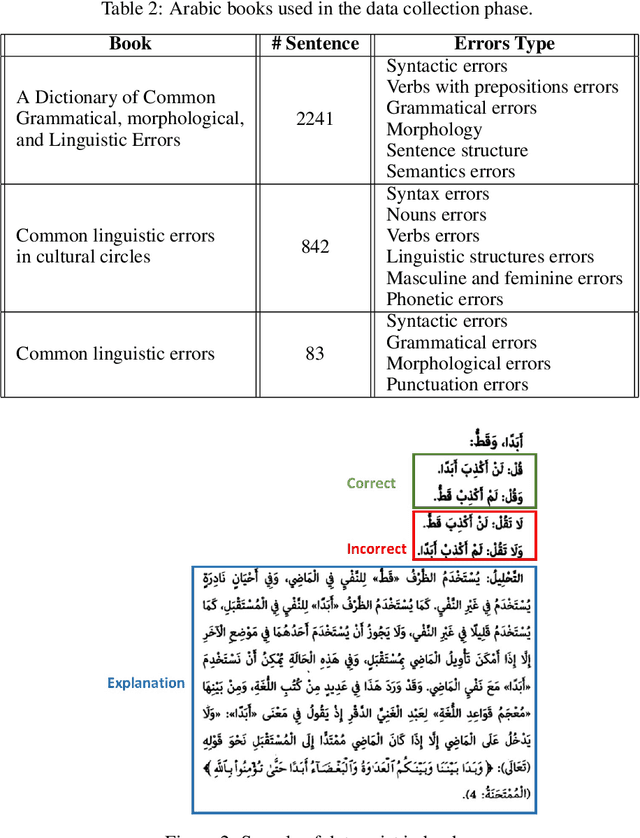

Natural language processing (NLP) utilizes text data augmentation to overcome sample size constraints. Increasing the sample size is a natural and widely used strategy for alleviating these challenges. In this study, we chose Arabic to increase the sample size and correct grammatical errors. Arabic is considered one of the languages with limited resources for grammatical error correction (GEC). Furthermore, QALB-14 and QALB-15 are the only datasets used in most Arabic grammatical error correction research, with approximately 20,500 parallel examples, which is considered low compared with other languages. Therefore, this study aims to develop an Arabic corpus called "Tibyan" for grammatical error correction using ChatGPT. ChatGPT is used as a data augmenter tool based on a pair of Arabic sentences containing grammatical errors matched with a sentence free of errors extracted from Arabic books, called guide sentences. Multiple steps were involved in establishing our corpus, including the collection and pre-processing of a pair of Arabic texts from various sources, such as books and open-access corpora. We then used ChatGPT to generate a parallel corpus based on the text collected previously, as a guide for generating sentences with multiple types of errors. By engaging linguistic experts to review and validate the automatically generated sentences, we ensured that they were correct and error-free. The corpus was validated and refined iteratively based on feedback provided by linguistic experts to improve its accuracy. Finally, we used the Arabic Error Type Annotation tool (ARETA) to analyze the types of errors in the Tibyan corpus. Our corpus contained 49 of errors, including seven types: orthography, morphology, syntax, semantics, punctuation, merge, and split. The Tibyan corpus contains approximately 600 K tokens.