 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlacenta Accreta Spectrum Detection using Multimodal Deep Learning
Dec 31, 2025Placenta Accreta Spectrum (PAS) is a life-threatening obstetric complication involving abnormal placental invasion into the uterine wall. Early and accurate prenatal diagnosis is essential to reduce maternal and neonatal risks. This study aimed to develop and validate a deep learning framework that enhances PAS detection by integrating multiple imaging modalities. A multimodal deep learning model was designed using an intermediate feature-level fusion architecture combining 3D Magnetic Resonance Imaging (MRI) and 2D Ultrasound (US) scans. Unimodal feature extractors, a 3D DenseNet121-Vision Transformer for MRI and a 2D ResNet50 for US, were selected after systematic comparative analysis. Curated datasets comprising 1,293 MRI and 1,143 US scans were used to train the unimodal models and paired samples of patient-matched MRI-US scans was isolated for multimodal model development and evaluation. On an independent test set, the multimodal fusion model achieved superior performance, with an accuracy of 92.5% and an Area Under the Receiver Operating Characteristic Curve (AUC) of 0.927, outperforming the MRI-only (82.5%, AUC 0.825) and US-only (87.5%, AUC 0.879) models. Integrating MRI and US features provides complementary diagnostic information, demonstrating strong potential to enhance prenatal risk assessment and improve patient outcomes.
Placenta Accreta Spectrum Detection Using an MRI-based Hybrid CNN-Transformer Model
Dec 21, 2025Placenta Accreta Spectrum (PAS) is a serious obstetric condition that can be challenging to diagnose with Magnetic Resonance Imaging (MRI) due to variability in radiologists' interpretations. To overcome this challenge, a hybrid 3D deep learning model for automated PAS detection from volumetric MRI scans is proposed in this study. The model integrates a 3D DenseNet121 to capture local features and a 3D Vision Transformer (ViT) to model global spatial context. It was developed and evaluated on a retrospective dataset of 1,133 MRI volumes. Multiple 3D deep learning architectures were also evaluated for comparison. On an independent test set, the DenseNet121-ViT model achieved the highest performance with a five-run average accuracy of 84.3%. These results highlight the strength of hybrid CNN-Transformer models as a computer-aided diagnosis tool. The model's performance demonstrates a clear potential to assist radiologists by providing a robust decision support to improve diagnostic consistency across interpretations, and ultimately enhance the accuracy and timeliness of PAS diagnosis.
ArbESC+: Arabic Enhanced Edit Selection System Combination for Grammatical Error Correction Resolving conflict and improving system combination in Arabic GEC
Nov 18, 2025Grammatical Error Correction (GEC) is an important aspect of natural language processing. Arabic has a complicated morphological and syntactic structure, posing a greater challenge than other languages. Even though modern neural models have improved greatly in recent years, the majority of previous attempts used individual models without taking into account the potential benefits of combining different systems. In this paper, we present one of the first multi-system approaches for correcting grammatical errors in Arabic, the Arab Enhanced Edit Selection System Complication (ArbESC+). Several models are used to collect correction proposals, which are represented as numerical features in the framework. A classifier determines and implements the appropriate corrections based on these features. In order to improve output quality, the framework uses support techniques to filter overlapping corrections and estimate decision reliability. A combination of AraT5, ByT5, mT5, AraBART, AraBART+Morph+GEC, and Text editing systems gave better results than a single model alone, with F0.5 at 82.63% on QALB-14 test data, 84.64% on QALB-15 L1 data, and 65.55% on QALB-15 L2 data. As one of the most significant contributions of this work, it's the first Arab attempt to integrate linguistic error correction. Improving existing models provides a practical step towards developing advanced tools that will benefit users and researchers of Arabic text processing.
Continuous Saudi Sign Language Recognition: A Vision Transformer Approach
Sep 03, 2025Sign language (SL) is an essential communication form for hearing-impaired and deaf people, enabling engagement within the broader society. Despite its significance, limited public awareness of SL often leads to inequitable access to educational and professional opportunities, thereby contributing to social exclusion, particularly in Saudi Arabia, where over 84,000 individuals depend on Saudi Sign Language (SSL) as their primary form of communication. Although certain technological approaches have helped to improve communication for individuals with hearing impairments, there continues to be an urgent requirement for more precise and dependable translation techniques, especially for Arabic sign language variants like SSL. Most state-of-the-art solutions have primarily focused on non-Arabic sign languages, resulting in a considerable absence of resources dedicated to Arabic sign language, specifically SSL. The complexity of the Arabic language and the prevalence of isolated sign language datasets that concentrate on individual words instead of continuous speech contribute to this issue. To address this gap, our research represents an important step in developing SSL resources. To address this, we introduce the first continuous Saudi Sign Language dataset called KAU-CSSL, focusing on complete sentences to facilitate further research and enable sophisticated recognition systems for SSL recognition and translation. Additionally, we propose a transformer-based model, utilizing a pretrained ResNet-18 for spatial feature extraction and a Transformer Encoder with Bidirectional LSTM for temporal dependencies, achieving 99.02\% accuracy at signer dependent mode and 77.71\% accuracy at signer independent mode. This development leads the way to not only improving communication tools for the SSL community but also making a substantial contribution to the wider field of sign language.
Towards the Development of Balanced Synthetic Data for Correcting Grammatical Errors in Arabic: An Approach Based on Error Tagging Model and Synthetic Data Generating Model
Feb 07, 2025Synthetic data generation is widely recognized as a way to enhance the quality of neural grammatical error correction (GEC) systems. However, current approaches often lack diversity or are too simplistic to generate the wide range of grammatical errors made by humans, especially for low-resource languages such as Arabic. In this paper, we will develop the error tagging model and the synthetic data generation model to create a large synthetic dataset in Arabic for grammatical error correction. In the error tagging model, the correct sentence is categorized into multiple error types by using the DeBERTav3 model. Arabic Error Type Annotation tool (ARETA) is used to guide multi-label classification tasks in an error tagging model in which each sentence is classified into 26 error tags. The synthetic data generation model is a back-translation-based model that generates incorrect sentences by appending error tags before the correct sentence that was generated from the error tagging model using the ARAT5 model. In the QALB-14 and QALB-15 Test sets, the error tagging model achieved 94.42% F1, which is state-of-the-art in identifying error tags in clean sentences. As a result of our syntactic data training in grammatical error correction, we achieved a new state-of-the-art result of F1-Score: 79.36% in the QALB-14 Test set. We generate 30,219,310 synthetic sentence pairs by using a synthetic data generation model.
Tibyan Corpus: Balanced and Comprehensive Error Coverage Corpus Using ChatGPT for Arabic Grammatical Error Correction
Nov 07, 2024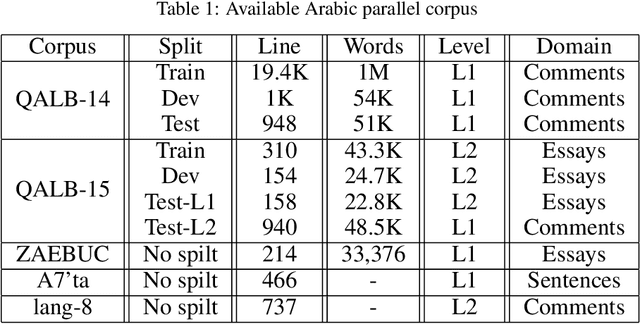
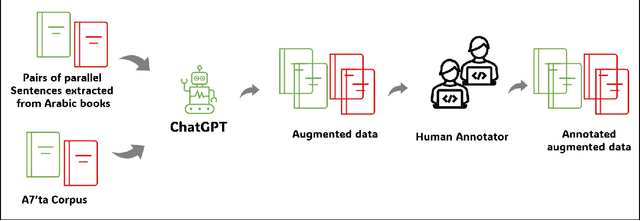
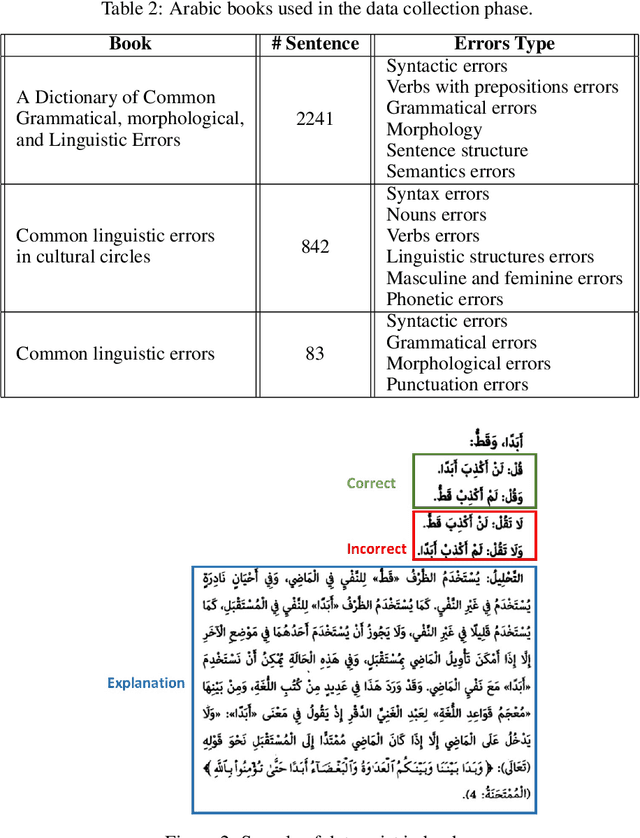

Natural language processing (NLP) utilizes text data augmentation to overcome sample size constraints. Increasing the sample size is a natural and widely used strategy for alleviating these challenges. In this study, we chose Arabic to increase the sample size and correct grammatical errors. Arabic is considered one of the languages with limited resources for grammatical error correction (GEC). Furthermore, QALB-14 and QALB-15 are the only datasets used in most Arabic grammatical error correction research, with approximately 20,500 parallel examples, which is considered low compared with other languages. Therefore, this study aims to develop an Arabic corpus called "Tibyan" for grammatical error correction using ChatGPT. ChatGPT is used as a data augmenter tool based on a pair of Arabic sentences containing grammatical errors matched with a sentence free of errors extracted from Arabic books, called guide sentences. Multiple steps were involved in establishing our corpus, including the collection and pre-processing of a pair of Arabic texts from various sources, such as books and open-access corpora. We then used ChatGPT to generate a parallel corpus based on the text collected previously, as a guide for generating sentences with multiple types of errors. By engaging linguistic experts to review and validate the automatically generated sentences, we ensured that they were correct and error-free. The corpus was validated and refined iteratively based on feedback provided by linguistic experts to improve its accuracy. Finally, we used the Arabic Error Type Annotation tool (ARETA) to analyze the types of errors in the Tibyan corpus. Our corpus contained 49 of errors, including seven types: orthography, morphology, syntax, semantics, punctuation, merge, and split. The Tibyan corpus contains approximately 600 K tokens.
Enhancing Textbook Question Answering Task with Large Language Models and Retrieval Augmented Generation
Feb 14, 2024
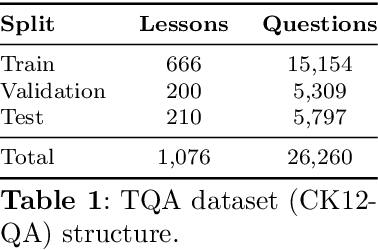
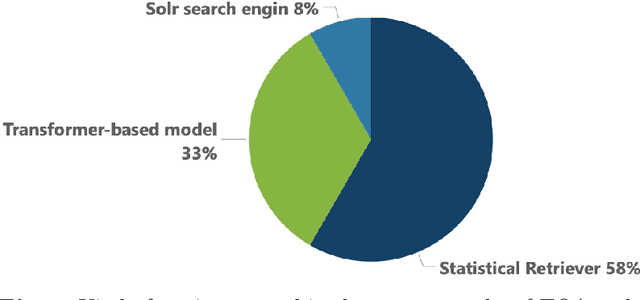
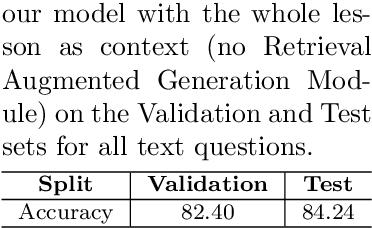
Textbook question answering (TQA) is a challenging task in artificial intelligence due to the complex nature of context and multimodal data. Although previous research has significantly improved the task, there are still some limitations including the models' weak reasoning and inability to capture contextual information in the lengthy context. The introduction of large language models (LLMs) has revolutionized the field of AI, however, directly applying LLMs often leads to inaccurate answers. This paper proposes a methodology that handle the out-of-domain scenario in TQA where concepts are spread across different lessons by incorporating the retrieval augmented generation (RAG) technique and utilize transfer learning to handle the long context and enhance reasoning abilities. Through supervised fine-tuning of the LLM model Llama-2 and the incorporation of RAG, our architecture outperforms the baseline, achieving a 4.12% accuracy improvement on validation set and 9.84% on test set for non-diagram multiple-choice questions.
Arabic Tweet Act: A Weighted Ensemble Pre-Trained Transformer Model for Classifying Arabic Speech Acts on Twitter
Jan 30, 2024Speech acts are a speakers actions when performing an utterance within a conversation, such as asking, recommending, greeting, or thanking someone, expressing a thought, or making a suggestion. Understanding speech acts helps interpret the intended meaning and actions behind a speakers or writers words. This paper proposes a Twitter dialectal Arabic speech act classification approach based on a transformer deep learning neural network. Twitter and social media, are becoming more and more integrated into daily life. As a result, they have evolved into a vital source of information that represents the views and attitudes of their users. We proposed a BERT based weighted ensemble learning approach to integrate the advantages of various BERT models in dialectal Arabic speech acts classification. We compared the proposed model against several variants of Arabic BERT models and sequence-based models. We developed a dialectal Arabic tweet act dataset by annotating a subset of a large existing Arabic sentiment analysis dataset (ASAD) based on six speech act categories. We also evaluated the models on a previously developed Arabic Tweet Act dataset (ArSAS). To overcome the class imbalance issue commonly observed in speech act problems, a transformer-based data augmentation model was implemented to generate an equal proportion of speech act categories. The results show that the best BERT model is araBERTv2-Twitter models with a macro-averaged F1 score and an accuracy of 0.73 and 0.84, respectively. The performance improved using a BERT-based ensemble method with a 0.74 and 0.85 averaged F1 score and accuracy on our dataset, respectively.
Detecting Suicidality in Arabic Tweets Using Machine Learning and Deep Learning Techniques
Sep 01, 2023



Social media platforms have revolutionized traditional communication techniques by enabling people globally to connect instantaneously, openly, and frequently. People use social media to share personal stories and express their opinion. Negative emotions such as thoughts of death, self-harm, and hardship are commonly expressed on social media, particularly among younger generations. As a result, using social media to detect suicidal thoughts will help provide proper intervention that will ultimately deter others from self-harm and committing suicide and stop the spread of suicidal ideation on social media. To investigate the ability to detect suicidal thoughts in Arabic tweets automatically, we developed a novel Arabic suicidal tweets dataset, examined several machine learning models, including Na\"ive Bayes, Support Vector Machine, K-Nearest Neighbor, Random Forest, and XGBoost, trained on word frequency and word embedding features, and investigated the ability of pre-trained deep learning models, AraBert, AraELECTRA, and AraGPT2, to identify suicidal thoughts in Arabic tweets. The results indicate that SVM and RF models trained on character n-gram features provided the best performance in the machine learning models, with 86% accuracy and an F1 score of 79%. The results of the deep learning models show that AraBert model outperforms other machine and deep learning models, achieving an accuracy of 91\% and an F1-score of 88%, which significantly improves the detection of suicidal ideation in the Arabic tweets dataset. To the best of our knowledge, this is the first study to develop an Arabic suicidality detection dataset from Twitter and to use deep-learning approaches in detecting suicidality in Arabic posts.
ALJP: An Arabic Legal Judgment Prediction in Personal Status Cases Using Machine Learning Models
Sep 01, 2023



Legal Judgment Prediction (LJP) aims to predict judgment outcomes based on case description. Several researchers have developed techniques to assist potential clients by predicting the outcome in the legal profession. However, none of the proposed techniques were implemented in Arabic, and only a few attempts were implemented in English, Chinese, and Hindi. In this paper, we develop a system that utilizes deep learning (DL) and natural language processing (NLP) techniques to predict the judgment outcome from Arabic case scripts, especially in cases of custody and annulment of marriage. This system will assist judges and attorneys in improving their work and time efficiency while reducing sentencing disparity. In addition, it will help litigants, lawyers, and law students analyze the probable outcomes of any given case before trial. We use a different machine and deep learning models such as Support Vector Machine (SVM), Logistic regression (LR), Long Short Term Memory (LSTM), and Bidirectional Long Short-Term Memory (BiLSTM) using representation techniques such as TF-IDF and word2vec on the developed dataset. Experimental results demonstrate that compared with the five baseline methods, the SVM model with word2vec and LR with TF-IDF achieve the highest accuracy of 88% and 78% in predicting the judgment on custody cases and annulment of marriage, respectively. Furthermore, the LR and SVM with word2vec and BiLSTM model with TF-IDF achieved the highest accuracy of 88% and 69% in predicting the probability of outcomes on custody cases and annulment of marriage, respectively.