 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePre-trained Transformer-Based Approach for Arabic Question Answering : A Comparative Study
Nov 10, 2021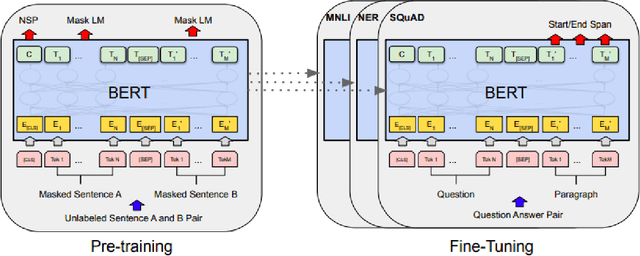
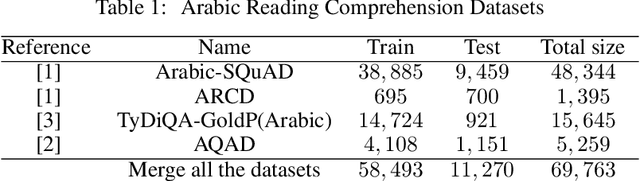
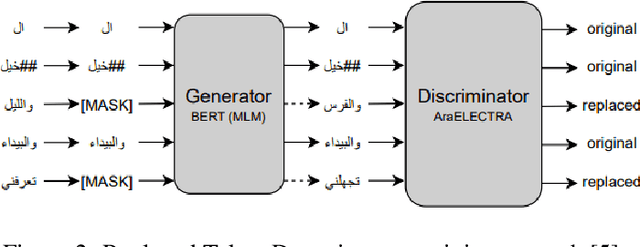
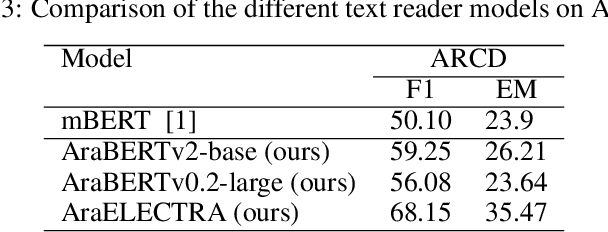
Question answering(QA) is one of the most challenging yet widely investigated problems in Natural Language Processing (NLP). Question-answering (QA) systems try to produce answers for given questions. These answers can be generated from unstructured or structured text. Hence, QA is considered an important research area that can be used in evaluating text understanding systems. A large volume of QA studies was devoted to the English language, investigating the most advanced techniques and achieving state-of-the-art results. However, research efforts in the Arabic question-answering progress at a considerably slower pace due to the scarcity of research efforts in Arabic QA and the lack of large benchmark datasets. Recently many pre-trained language models provided high performance in many Arabic NLP problems. In this work, we evaluate the state-of-the-art pre-trained transformers models for Arabic QA using four reading comprehension datasets which are Arabic-SQuAD, ARCD, AQAD, and TyDiQA-GoldP datasets. We fine-tuned and compared the performance of the AraBERTv2-base model, AraBERTv0.2-large model, and AraELECTRA model. In the last, we provide an analysis to understand and interpret the low-performance results obtained by some models.