 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeC-MORAL: Controllable Multi-Objective Molecular Optimization with Reinforcement Alignment for LLMs
Apr 24, 2026Large language models (LLMs) show promise for molecular optimization, but aligning them with selective and competing drug-design constraints remains challenging. We propose C-Moral, a reinforcement learning post-training framework for controllable multi-objective molecular optimization. C-Moral combines group-based relative optimization, property score alignment for heterogeneous objectives, and continuous non-linear reward aggregation to improve stability across competing properties. Experiments on the C-MuMOInstruct benchmark show that C-Moral consistently outperforms state-of-the-art models across both in-domain and out-of-domain settings, achieving the best Success Optimized Rate (SOR) of 48.9% on IND tasks and 39.5% on OOD tasks, while largely preserving scaffold similarity. These results suggest that RL post-training is an effective way to align molecular language models with continuous molecular design objectives. Our code and models are publicly available at https://github.com/Rwigie/C-MORAL.
RAGPPI: RAG Benchmark for Protein-Protein Interactions in Drug Discovery
May 28, 2025
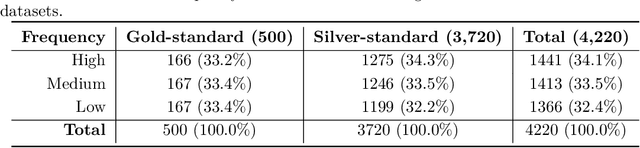


Retrieving the biological impacts of protein-protein interactions (PPIs) is essential for target identification (Target ID) in drug development. Given the vast number of proteins involved, this process remains time-consuming and challenging. Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) frameworks have supported Target ID; however, no benchmark currently exists for identifying the biological impacts of PPIs. To bridge this gap, we introduce the RAG Benchmark for PPIs (RAGPPI), a factual question-answer benchmark of 4,420 question-answer pairs that focus on the potential biological impacts of PPIs. Through interviews with experts, we identified criteria for a benchmark dataset, such as a type of QA and source. We built a gold-standard dataset (500 QA pairs) through expert-driven data annotation. We developed an ensemble auto-evaluation LLM that reflected expert labeling characteristics, which facilitates the construction of a silver-standard dataset (3,720 QA pairs). We are committed to maintaining RAGPPI as a resource to support the research community in advancing RAG systems for drug discovery QA solutions.
Voice Interaction With Conversational AI Could Facilitate Thoughtful Reflection and Substantive Revision in Writing
Apr 11, 2025Writing well requires not only expressing ideas but also refining them through revision, a process facilitated by reflection. Prior research suggests that feedback delivered through dialogues, such as those in writing center tutoring sessions, can help writers reflect more thoughtfully on their work compared to static feedback. Recent advancements in multi-modal large language models (LLMs) now offer new possibilities for supporting interactive and expressive voice-based reflection in writing. In particular, we propose that LLM-generated static feedback can be repurposed as conversation starters, allowing writers to seek clarification, request examples, and ask follow-up questions, thereby fostering deeper reflection on their writing. We argue that voice-based interaction can naturally facilitate this conversational exchange, encouraging writers' engagement with higher-order concerns, facilitating iterative refinement of their reflections, and reduce cognitive load compared to text-based interactions. To investigate these effects, we propose a formative study exploring how text vs. voice input influence writers' reflection and subsequent revisions. Findings from this study will inform the design of intelligent and interactive writing tools, offering insights into how voice-based interactions with LLM-powered conversational agents can support reflection and revision.
Z-Stack Scanning can Improve AI Detection of Mitosis: A Case Study of Meningiomas
Jan 27, 2025



Z-stack scanning is an emerging whole slide imaging technology that captures multiple focal planes alongside the z-axis of a glass slide. Because z-stacking can offer enhanced depth information compared to the single-layer whole slide imaging, this technology can be particularly useful in analyzing small-scaled histopathological patterns. However, its actual clinical impact remains debated with mixed results. To clarify this, we investigate the effect of z-stack scanning on artificial intelligence (AI) mitosis detection of meningiomas. With the same set of 22 Hematoxylin and Eosin meningioma glass slides scanned by three different digital pathology scanners, we tested the performance of three AI pipelines on both single-layer and z-stacked whole slide images (WSIs). Results showed that in all scanner-AI combinations, z-stacked WSIs significantly increased AI's sensitivity (+17.14%) on the mitosis detection with only a marginal impact on precision. Our findings provide quantitative evidence that highlights z-stack scanning as a promising technique for AI mitosis detection, paving the way for more reliable AI-assisted pathology workflows, which can ultimately benefit patient management.
RoCap: A Robotic Data Collection Pipeline for the Pose Estimation of Appearance-Changing Objects
Jul 10, 2024



Object pose estimation plays a vital role in mixed-reality interactions when users manipulate tangible objects as controllers. Traditional vision-based object pose estimation methods leverage 3D reconstruction to synthesize training data. However, these methods are designed for static objects with diffuse colors and do not work well for objects that change their appearance during manipulation, such as deformable objects like plush toys, transparent objects like chemical flasks, reflective objects like metal pitchers, and articulated objects like scissors. To address this limitation, we propose Rocap, a robotic pipeline that emulates human manipulation of target objects while generating data labeled with ground truth pose information. The user first gives the target object to a robotic arm, and the system captures many pictures of the object in various 6D configurations. The system trains a model by using captured images and their ground truth pose information automatically calculated from the joint angles of the robotic arm. We showcase pose estimation for appearance-changing objects by training simple deep-learning models using the collected data and comparing the results with a model trained with synthetic data based on 3D reconstruction via quantitative and qualitative evaluation. The findings underscore the promising capabilities of Rocap.
Supporting Mitosis Detection AI Training with Inter-Observer Eye-Gaze Consistencies
Apr 02, 2024

The expansion of artificial intelligence (AI) in pathology tasks has intensified the demand for doctors' annotations in AI development. However, collecting high-quality annotations from doctors is costly and time-consuming, creating a bottleneck in AI progress. This study investigates eye-tracking as a cost-effective technology to collect doctors' behavioral data for AI training with a focus on the pathology task of mitosis detection. One major challenge in using eye-gaze data is the low signal-to-noise ratio, which hinders the extraction of meaningful information. We tackled this by levering the properties of inter-observer eye-gaze consistencies and creating eye-gaze labels from consistent eye-fixations shared by a group of observers. Our study involved 14 non-medical participants, from whom we collected eye-gaze data and generated eye-gaze labels based on varying group sizes. We assessed the efficacy of such eye-gaze labels by training Convolutional Neural Networks (CNNs) and comparing their performance to those trained with ground truth annotations and a heuristic-based baseline. Results indicated that CNNs trained with our eye-gaze labels closely followed the performance of ground-truth-based CNNs, and significantly outperformed the baseline. Although primarily focused on mitosis, we envision that insights from this study can be generalized to other medical imaging tasks.
Domain generalization across tumor types, laboratories, and species -- insights from the 2022 edition of the Mitosis Domain Generalization Challenge
Sep 27, 2023



Recognition of mitotic figures in histologic tumor specimens is highly relevant to patient outcome assessment. This task is challenging for algorithms and human experts alike, with deterioration of algorithmic performance under shifts in image representations. Considerable covariate shifts occur when assessment is performed on different tumor types, images are acquired using different digitization devices, or specimens are produced in different laboratories. This observation motivated the inception of the 2022 challenge on MItosis Domain Generalization (MIDOG 2022). The challenge provided annotated histologic tumor images from six different domains and evaluated the algorithmic approaches for mitotic figure detection provided by nine challenge participants on ten independent domains. Ground truth for mitotic figure detection was established in two ways: a three-expert consensus and an independent, immunohistochemistry-assisted set of labels. This work represents an overview of the challenge tasks, the algorithmic strategies employed by the participants, and potential factors contributing to their success. With an $F_1$ score of 0.764 for the top-performing team, we summarize that domain generalization across various tumor domains is possible with today's deep learning-based recognition pipelines. When assessed against the immunohistochemistry-assisted reference standard, all methods resulted in reduced recall scores, but with only minor changes in the order of participants in the ranking.
Next Steps for Human-Centered Generative AI: A Technical Perspective
Jun 27, 2023
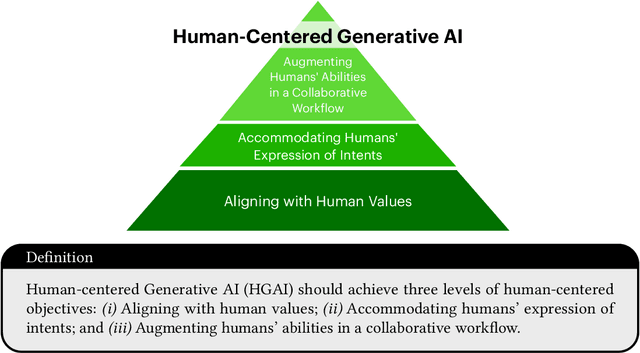
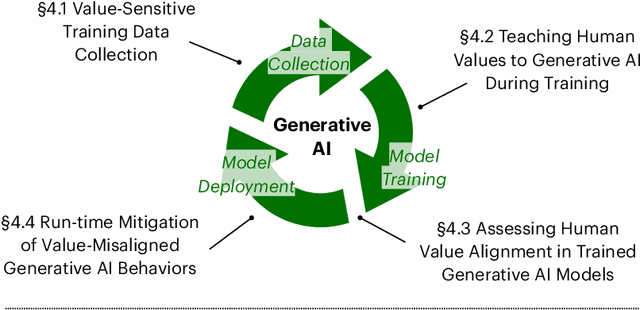

Through iterative, cross-disciplinary discussions, we define and propose next-steps for Human-centered Generative AI (HGAI) from a technical perspective. We contribute a roadmap that lays out future directions of Generative AI spanning three levels: Aligning with human values; Accommodating humans' expression of intents; and Augmenting humans' abilities in a collaborative workflow. This roadmap intends to draw interdisciplinary research teams to a comprehensive list of emergent ideas in HGAI, identifying their interested topics while maintaining a coherent big picture of the future work landscape.
Designing and Evaluating Interfaces that Highlight News Coverage Diversity Using Discord Questions
Feb 17, 2023



Modern news aggregators do the hard work of organizing a large news stream, creating collections for a given news story with tens of source options. This paper shows that navigating large source collections for a news story can be challenging without further guidance. In this work, we design three interfaces -- the Annotated Article, the Recomposed Article, and the Question Grid -- aimed at accompanying news readers in discovering coverage diversity while they read. A first usability study with 10 journalism experts confirms the designed interfaces all reveal coverage diversity and determine each interface's potential use cases and audiences. In a second usability study, we developed and implemented a reading exercise with 95 novice news readers to measure exposure to coverage diversity. Results show that Annotated Article users are able to answer questions 34% more completely than with two existing interfaces while finding the interface equally easy to use.
GANravel: User-Driven Direction Disentanglement in Generative Adversarial Networks
Jan 31, 2023



Generative adversarial networks (GANs) have many application areas including image editing, domain translation, missing data imputation, and support for creative work. However, GANs are considered 'black boxes'. Specifically, the end-users have little control over how to improve editing directions through disentanglement. Prior work focused on new GAN architectures to disentangle editing directions. Alternatively, we propose GANravel a user-driven direction disentanglement tool that complements the existing GAN architectures and allows users to improve editing directions iteratively. In two user studies with 16 participants each, GANravel users were able to disentangle directions and outperformed the state-of-the-art direction discovery baselines in disentanglement performance. In the second user study, GANravel was used in a creative task of creating dog memes and was able to create high-quality edited images and GIFs.