 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommonsense Generation and Evaluation for Dialogue Systems using Large Language Models
Jun 24, 2025This paper provides preliminary results on exploring the task of performing turn-level data augmentation for dialogue system based on different types of commonsense relationships, and the automatic evaluation of the generated synthetic turns. The proposed methodology takes advantage of the extended knowledge and zero-shot capabilities of pretrained Large Language Models (LLMs) to follow instructions, understand contextual information, and their commonsense reasoning capabilities. The approach draws inspiration from methodologies like Chain-of-Thought (CoT), applied more explicitly to the task of prompt-based generation for dialogue-based data augmentation conditioned on commonsense attributes, and the automatic evaluation of the generated dialogues. To assess the effectiveness of the proposed approach, first we extracted 200 randomly selected partial dialogues, from 5 different well-known dialogue datasets, and generate alternative responses conditioned on different event commonsense attributes. This novel dataset allows us to measure the proficiency of LLMs in generating contextually relevant commonsense knowledge, particularly up to 12 different specific ATOMIC [10] database relations. Secondly, we propose an evaluation framework to automatically detect the quality of the generated dataset inspired by the ACCENT [26] metric, which offers a nuanced approach to assess event commonsense. However, our method does not follow ACCENT's complex eventrelation tuple extraction process. Instead, we propose an instruction-based prompt for each commonsense attribute and use state-of-the-art LLMs to automatically detect the original attributes used when creating each augmented turn in the previous step. Preliminary results suggest that our approach effectively harnesses LLMs capabilities for commonsense reasoning and evaluation in dialogue systems.
Beyond Single-Audio: Advancing Multi-Audio Processing in Audio Large Language Models
Sep 27, 2024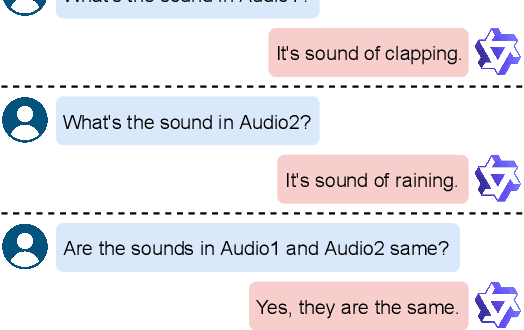
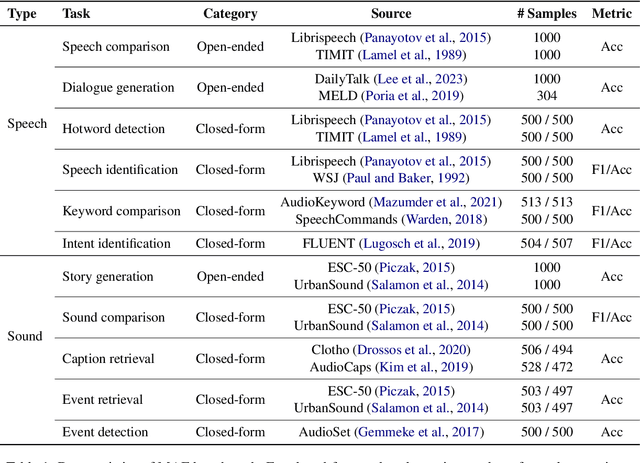
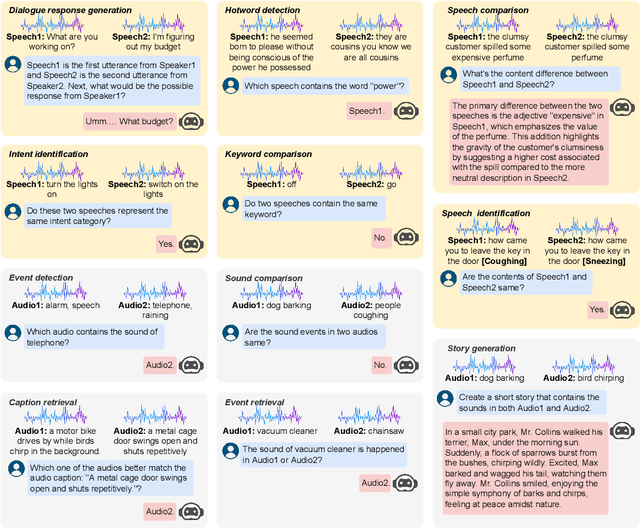
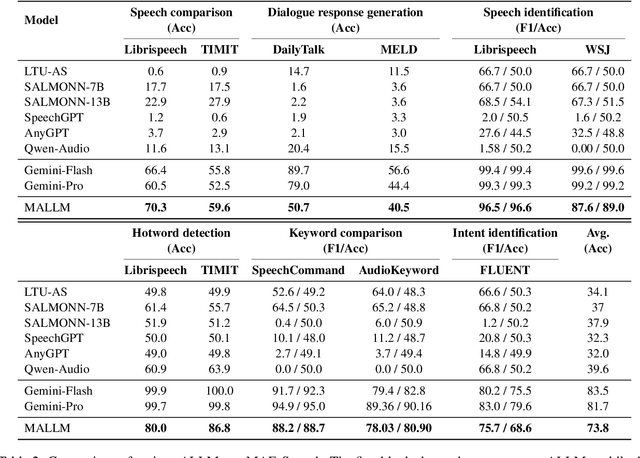
Various audio-LLMs (ALLMs) have been explored recently for tackling different audio tasks simultaneously using a single, unified model. While existing evaluations of ALLMs primarily focus on single-audio tasks, real-world applications often involve processing multiple audio streams simultaneously. To bridge this gap, we propose the first multi-audio evaluation (MAE) benchmark that consists of 20 datasets from 11 multi-audio tasks encompassing both speech and sound scenarios. Comprehensive experiments on MAE demonstrate that the existing ALLMs, while being powerful in comprehending primary audio elements in individual audio inputs, struggling to handle multi-audio scenarios. To this end, we propose a novel multi-audio-LLM (MALLM) to capture audio context among multiple similar audios using discriminative learning on our proposed synthetic data. The results demonstrate that the proposed MALLM outperforms all baselines and achieves high data efficiency using synthetic data without requiring human annotations. The proposed MALLM opens the door for ALLMs towards multi-audio processing era and brings us closer to replicating human auditory capabilities in machines.
CVQA: Culturally-diverse Multilingual Visual Question Answering Benchmark
Jun 10, 2024



Visual Question Answering (VQA) is an important task in multimodal AI, and it is often used to test the ability of vision-language models to understand and reason on knowledge present in both visual and textual data. However, most of the current VQA models use datasets that are primarily focused on English and a few major world languages, with images that are typically Western-centric. While recent efforts have tried to increase the number of languages covered on VQA datasets, they still lack diversity in low-resource languages. More importantly, although these datasets often extend their linguistic range via translation or some other approaches, they usually keep images the same, resulting in narrow cultural representation. To address these limitations, we construct CVQA, a new Culturally-diverse multilingual Visual Question Answering benchmark, designed to cover a rich set of languages and cultures, where we engage native speakers and cultural experts in the data collection process. As a result, CVQA includes culturally-driven images and questions from across 28 countries on four continents, covering 26 languages with 11 scripts, providing a total of 9k questions. We then benchmark several Multimodal Large Language Models (MLLMs) on CVQA, and show that the dataset is challenging for the current state-of-the-art models. This benchmark can serve as a probing evaluation suite for assessing the cultural capability and bias of multimodal models and hopefully encourage more research efforts toward increasing cultural awareness and linguistic diversity in this field.
Unveiling the Achilles' Heel of NLG Evaluators: A Unified Adversarial Framework Driven by Large Language Models
May 23, 2024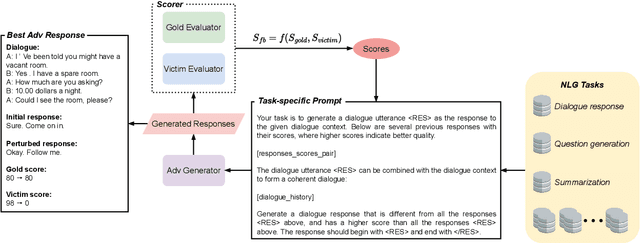
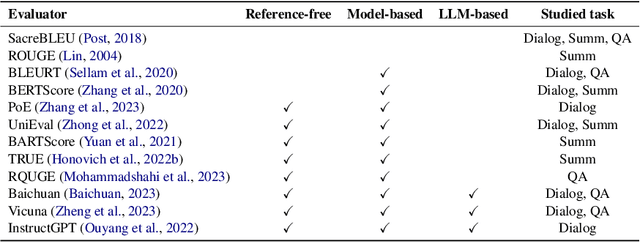
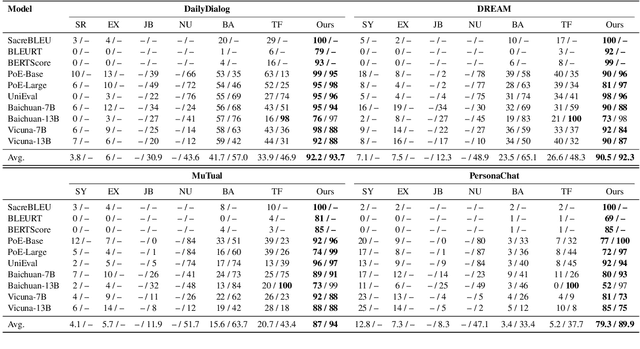

The automatic evaluation of natural language generation (NLG) systems presents a long-lasting challenge. Recent studies have highlighted various neural metrics that align well with human evaluations. Yet, the robustness of these evaluators against adversarial perturbations remains largely under-explored due to the unique challenges in obtaining adversarial data for different NLG evaluation tasks. To address the problem, we introduce AdvEval, a novel black-box adversarial framework against NLG evaluators. AdvEval is specially tailored to generate data that yield strong disagreements between human and victim evaluators. Specifically, inspired by the recent success of large language models (LLMs) in text generation and evaluation, we adopt strong LLMs as both the data generator and gold evaluator. Adversarial data are automatically optimized with feedback from the gold and victim evaluator. We conduct experiments on 12 victim evaluators and 11 NLG datasets, spanning tasks including dialogue, summarization, and question evaluation. The results show that AdvEval can lead to significant performance degradation of various victim metrics, thereby validating its efficacy.
Awareness in robotics: An early perspective from the viewpoint of the EIC Pathfinder Challenge "Awareness Inside''
Feb 14, 2024Consciousness has been historically a heavily debated topic in engineering, science, and philosophy. On the contrary, awareness had less success in raising the interest of scholars in the past. However, things are changing as more and more researchers are getting interested in answering questions concerning what awareness is and how it can be artificially generated. The landscape is rapidly evolving, with multiple voices and interpretations of the concept being conceived and techniques being developed. The goal of this paper is to summarize and discuss the ones among these voices connected with projects funded by the EIC Pathfinder Challenge called ``Awareness Inside'', a nonrecurring call for proposals within Horizon Europe designed specifically for fostering research on natural and synthetic awareness. In this perspective, we dedicate special attention to challenges and promises of applying synthetic awareness in robotics, as the development of mature techniques in this new field is expected to have a special impact on generating more capable and trustworthy embodied systems.
A Comprehensive Analysis of the Effectiveness of Large Language Models as Automatic Dialogue Evaluators
Dec 24, 2023Automatic evaluation is an integral aspect of dialogue system research. The traditional reference-based NLG metrics are generally found to be unsuitable for dialogue assessment. Consequently, recent studies have suggested various unique, reference-free neural metrics that better align with human evaluations. Notably among them, large language models (LLMs), particularly the instruction-tuned variants like ChatGPT, are shown to be promising substitutes for human judges. Yet, existing works on utilizing LLMs for automatic dialogue evaluation are limited in their scope in terms of the number of meta-evaluation datasets, mode of evaluation, coverage of LLMs, etc. Hence, it remains inconclusive how effective these LLMs are. To this end, we conduct a comprehensive study on the application of LLMs for automatic dialogue evaluation. Specifically, we analyze the multi-dimensional evaluation capability of 30 recently emerged LLMs at both turn and dialogue levels, using a comprehensive set of 12 meta-evaluation datasets. Additionally, we probe the robustness of the LLMs in handling various adversarial perturbations at both turn and dialogue levels. Finally, we explore how model-level and dimension-level ensembles impact the evaluation performance. All resources are available at https://github.com/e0397123/comp-analysis.
xDial-Eval: A Multilingual Open-Domain Dialogue Evaluation Benchmark
Oct 13, 2023



Recent advancements in reference-free learned metrics for open-domain dialogue evaluation have been driven by the progress in pre-trained language models and the availability of dialogue data with high-quality human annotations. However, current studies predominantly concentrate on English dialogues, and the generalization of these metrics to other languages has not been fully examined. This is largely due to the absence of a multilingual dialogue evaluation benchmark. To address the issue, we introduce xDial-Eval, built on top of open-source English dialogue evaluation datasets. xDial-Eval includes 12 turn-level and 6 dialogue-level English datasets, comprising 14930 annotated turns and 8691 annotated dialogues respectively. The English dialogue data are extended to nine other languages with commercial machine translation systems. On xDial-Eval, we conduct comprehensive analyses of previous BERT-based metrics and the recently-emerged large language models. Lastly, we establish strong self-supervised and multilingual baselines. In terms of average Pearson correlations over all datasets and languages, the best baseline outperforms OpenAI's ChatGPT by absolute improvements of 6.5% and 4.6% at the turn and dialogue levels respectively, albeit with much fewer parameters. The data and code are publicly available at https://github.com/e0397123/xDial-Eval.
Overview of Robust and Multilingual Automatic Evaluation Metrics for Open-Domain Dialogue Systems at DSTC 11 Track 4
Jun 22, 2023



The advent and fast development of neural networks have revolutionized the research on dialogue systems and subsequently have triggered various challenges regarding their automatic evaluation. Automatic evaluation of open-domain dialogue systems as an open challenge has been the center of the attention of many researchers. Despite the consistent efforts to improve automatic metrics' correlations with human evaluation, there have been very few attempts to assess their robustness over multiple domains and dimensions. Also, their focus is mainly on the English language. All of these challenges prompt the development of automatic evaluation metrics that are reliable in various domains, dimensions, and languages. This track in the 11th Dialogue System Technology Challenge (DSTC11) is part of the ongoing effort to promote robust and multilingual automatic evaluation metrics. This article describes the datasets and baselines provided to participants and discusses the submission and result details of the two proposed subtasks.
PoE: a Panel of Experts for Generalized Automatic Dialogue Assessment
Dec 18, 2022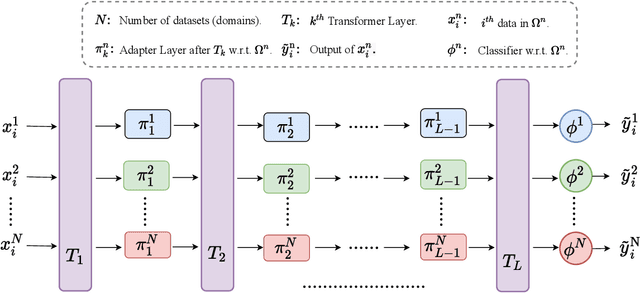
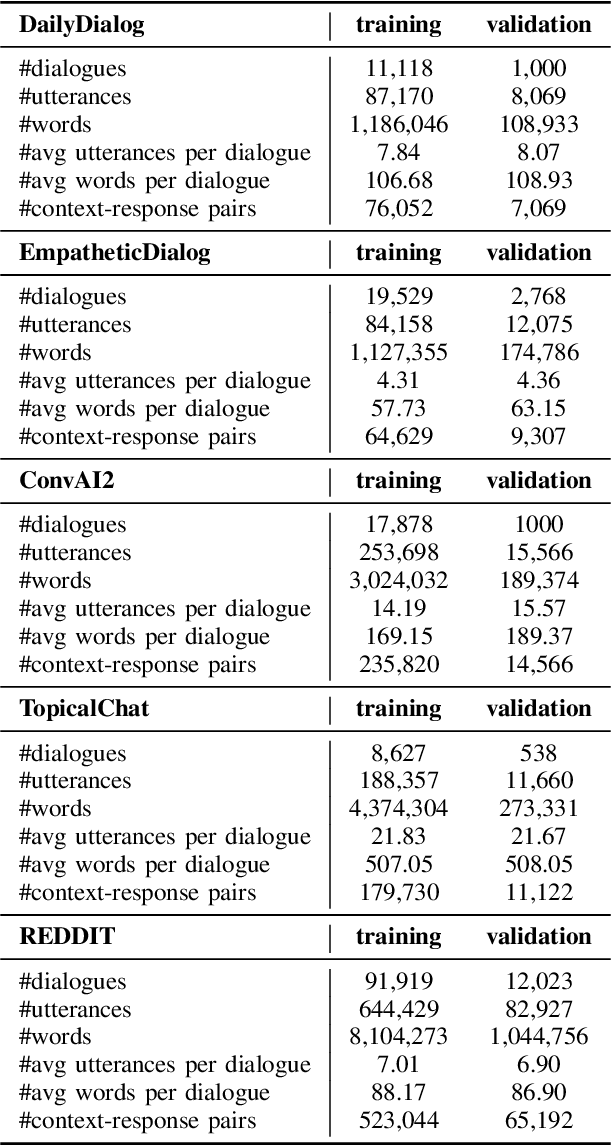


Chatbots are expected to be knowledgeable across multiple domains, e.g. for daily chit-chat, exchange of information, and grounding in emotional situations. To effectively measure the quality of such conversational agents, a model-based automatic dialogue evaluation metric (ADEM) is expected to perform well across multiple domains. Despite significant progress, an ADEM that works well in one domain does not necessarily generalize to another. This calls for a dedicated network architecture for domain generalization. To tackle the multi-domain dialogue evaluation task, we propose a Panel of Experts (PoE), a multitask network that consists of a shared transformer encoder and a collection of lightweight adapters. The shared encoder captures the general knowledge of dialogues across domains, while each adapter specializes in one specific domain and serves as a domain expert. To validate the idea, we construct a high-quality multi-domain dialogue dataset leveraging data augmentation and pseudo-labeling. The PoE network is comprehensively assessed on 16 dialogue evaluation datasets spanning a wide range of dialogue domains. It achieves state-of-the-art performance in terms of mean Spearman correlation over all the evaluation datasets. It exhibits better zero-shot generalization than existing state-of-the-art ADEMs and the ability to easily adapt to new domains with few-shot transfer learning.
FineD-Eval: Fine-grained Automatic Dialogue-Level Evaluation
Oct 29, 2022



Recent model-based reference-free metrics for open-domain dialogue evaluation exhibit promising correlations with human judgment. However, they either perform turn-level evaluation or look at a single dialogue quality dimension. One would expect a good evaluation metric to assess multiple quality dimensions at the dialogue level. To this end, we are motivated to propose a multi-dimensional dialogue-level metric, which consists of three sub-metrics with each targeting a specific dimension. The sub-metrics are trained with novel self-supervised objectives and exhibit strong correlations with human judgment for their respective dimensions. Moreover, we explore two approaches to combine the sub-metrics: metric ensemble and multitask learning. Both approaches yield a holistic metric that significantly outperforms individual sub-metrics. Compared to the existing state-of-the-art metric, the combined metrics achieve around 16% relative improvement on average across three high-quality dialogue-level evaluation benchmarks.