 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoE: a Panel of Experts for Generalized Automatic Dialogue Assessment
Dec 18, 2022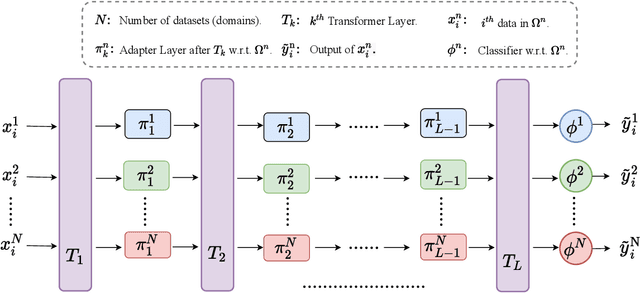


Chatbots are expected to be knowledgeable across multiple domains, e.g. for daily chit-chat, exchange of information, and grounding in emotional situations. To effectively measure the quality of such conversational agents, a model-based automatic dialogue evaluation metric (ADEM) is expected to perform well across multiple domains. Despite significant progress, an ADEM that works well in one domain does not necessarily generalize to another. This calls for a dedicated network architecture for domain generalization. To tackle the multi-domain dialogue evaluation task, we propose a Panel of Experts (PoE), a multitask network that consists of a shared transformer encoder and a collection of lightweight adapters. The shared encoder captures the general knowledge of dialogues across domains, while each adapter specializes in one specific domain and serves as a domain expert. To validate the idea, we construct a high-quality multi-domain dialogue dataset leveraging data augmentation and pseudo-labeling. The PoE network is comprehensively assessed on 16 dialogue evaluation datasets spanning a wide range of dialogue domains. It achieves state-of-the-art performance in terms of mean Spearman correlation over all the evaluation datasets. It exhibits better zero-shot generalization than existing state-of-the-art ADEMs and the ability to easily adapt to new domains with few-shot transfer learning.
FineD-Eval: Fine-grained Automatic Dialogue-Level Evaluation
Oct 29, 2022



Recent model-based reference-free metrics for open-domain dialogue evaluation exhibit promising correlations with human judgment. However, they either perform turn-level evaluation or look at a single dialogue quality dimension. One would expect a good evaluation metric to assess multiple quality dimensions at the dialogue level. To this end, we are motivated to propose a multi-dimensional dialogue-level metric, which consists of three sub-metrics with each targeting a specific dimension. The sub-metrics are trained with novel self-supervised objectives and exhibit strong correlations with human judgment for their respective dimensions. Moreover, we explore two approaches to combine the sub-metrics: metric ensemble and multitask learning. Both approaches yield a holistic metric that significantly outperforms individual sub-metrics. Compared to the existing state-of-the-art metric, the combined metrics achieve around 16% relative improvement on average across three high-quality dialogue-level evaluation benchmarks.
MDD-Eval: Self-Training on Augmented Data for Multi-Domain Dialogue Evaluation
Dec 14, 2021
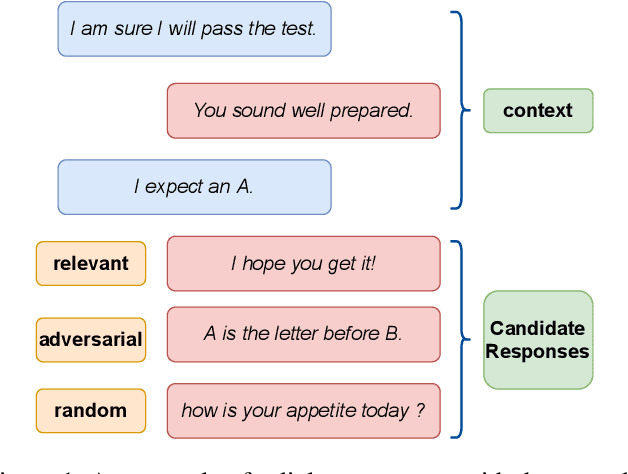
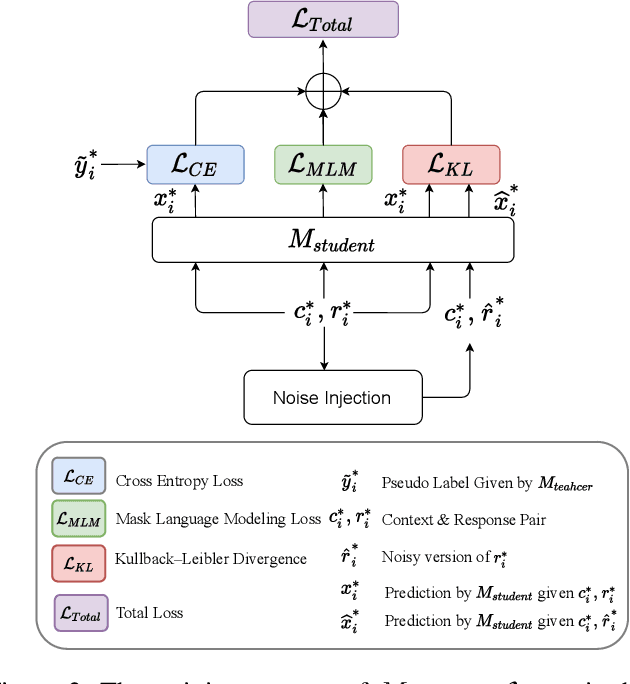
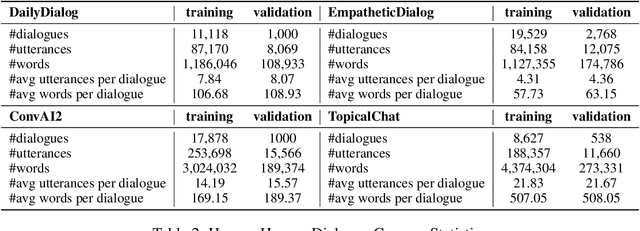
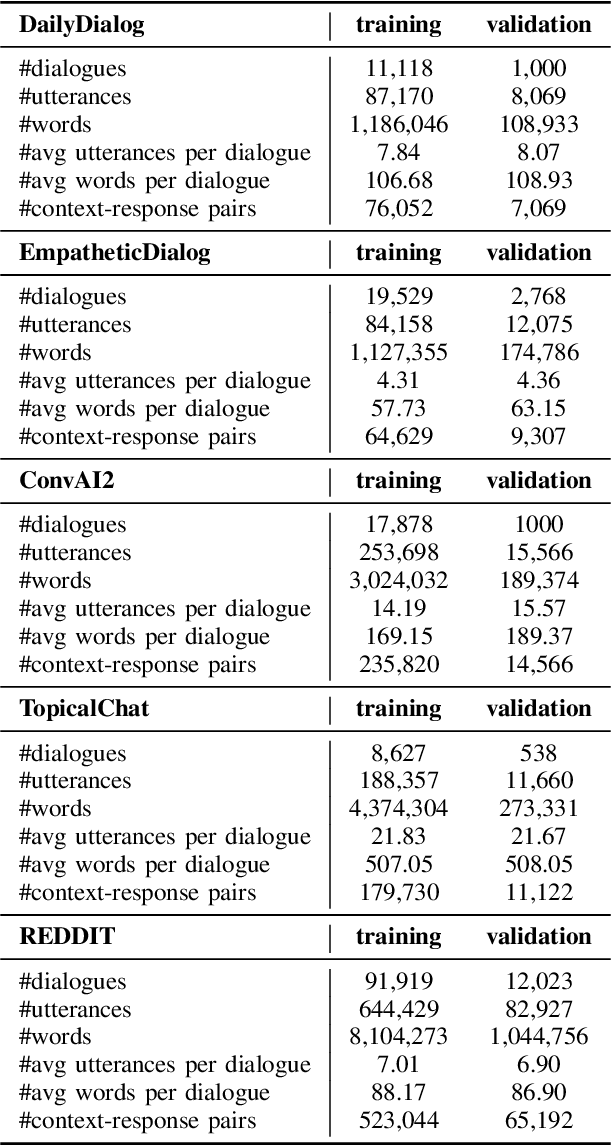
Chatbots are designed to carry out human-like conversations across different domains, such as general chit-chat, knowledge exchange, and persona-grounded conversations. To measure the quality of such conversational agents, a dialogue evaluator is expected to conduct assessment across domains as well. However, most of the state-of-the-art automatic dialogue evaluation metrics (ADMs) are not designed for multi-domain evaluation. We are motivated to design a general and robust framework, MDD-Eval, to address the problem. Specifically, we first train a teacher evaluator with human-annotated data to acquire a rating skill to tell good dialogue responses from bad ones in a particular domain and then, adopt a self-training strategy to train a new evaluator with teacher-annotated multi-domain data, that helps the new evaluator to generalize across multiple domains. MDD-Eval is extensively assessed on six dialogue evaluation benchmarks. Empirical results show that the MDD-Eval framework achieves a strong performance with an absolute improvement of 7% over the state-of-the-art ADMs in terms of mean Spearman correlation scores across all the evaluation benchmarks.
Investigating the Impact of Pre-trained Language Models on Dialog Evaluation
Oct 05, 2021

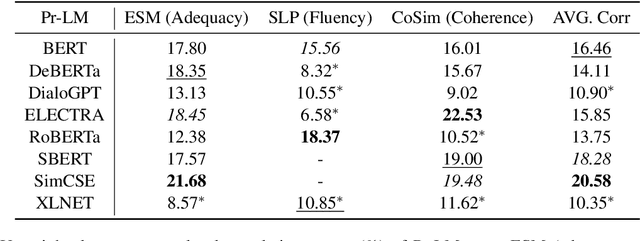
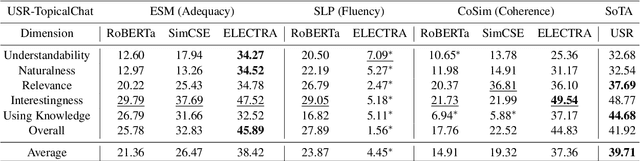
Recently, there is a surge of interest in applying pre-trained language models (Pr-LM) in automatic open-domain dialog evaluation. Pr-LMs offer a promising direction for addressing the multi-domain evaluation challenge. Yet, the impact of different Pr-LMs on the performance of automatic metrics is not well-understood. This paper examines 8 different Pr-LMs and studies their impact on three typical automatic dialog evaluation metrics across three different dialog evaluation benchmarks. Specifically, we analyze how the choice of Pr-LMs affects the performance of automatic metrics. Extensive correlation analyses on each of the metrics are performed to assess the effects of different Pr-LMs along various axes, including pre-training objectives, dialog evaluation criteria, model size, and cross-dataset robustness. This study serves as the first comprehensive assessment of the effects of different Pr-LMs on automatic dialog evaluation.
DynaEval: Unifying Turn and Dialogue Level Evaluation
Jun 06, 2021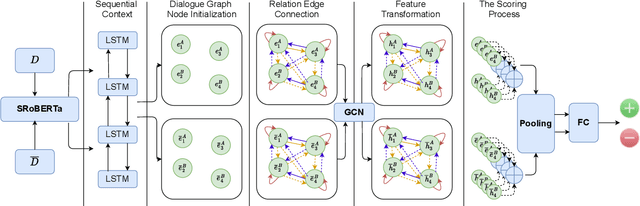
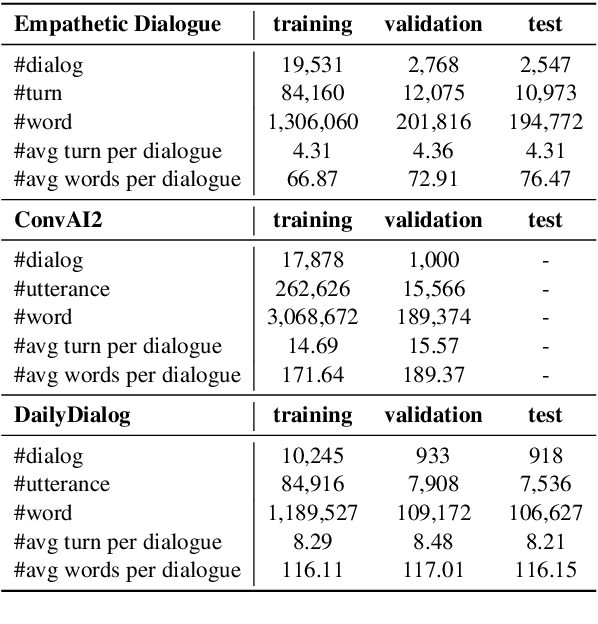
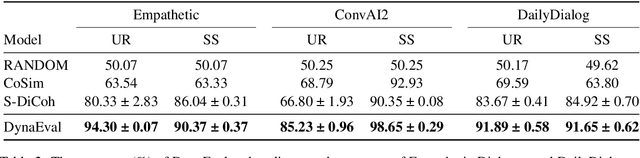
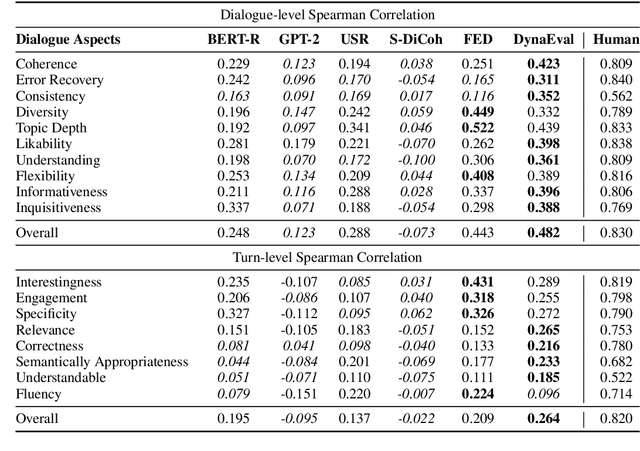
A dialogue is essentially a multi-turn interaction among interlocutors. Effective evaluation metrics should reflect the dynamics of such interaction. Existing automatic metrics are focused very much on the turn-level quality, while ignoring such dynamics. To this end, we propose DynaEval, a unified automatic evaluation framework which is not only capable of performing turn-level evaluation, but also holistically considers the quality of the entire dialogue. In DynaEval, the graph convolutional network (GCN) is adopted to model a dialogue in totality, where the graph nodes denote each individual utterance and the edges represent the dependency between pairs of utterances. A contrastive loss is then applied to distinguish well-formed dialogues from carefully constructed negative samples. Experiments show that DynaEval significantly outperforms the state-of-the-art dialogue coherence model, and correlates strongly with human judgements across multiple dialogue evaluation aspects at both turn and dialogue level.