 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMDD-Eval: Self-Training on Augmented Data for Multi-Domain Dialogue Evaluation
Paper and Code

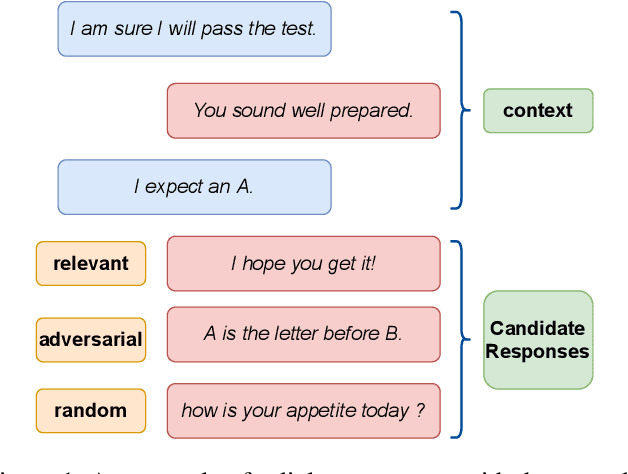
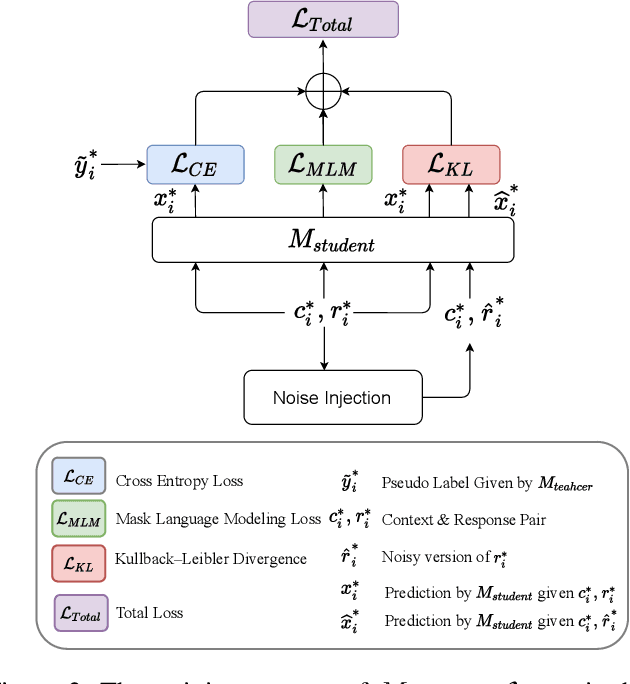
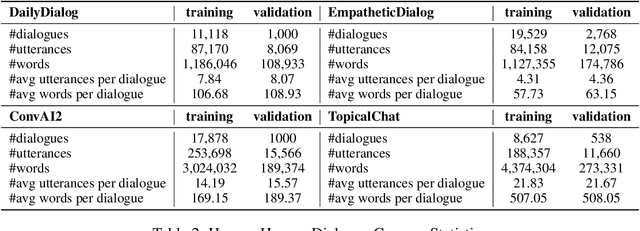
Chatbots are designed to carry out human-like conversations across different domains, such as general chit-chat, knowledge exchange, and persona-grounded conversations. To measure the quality of such conversational agents, a dialogue evaluator is expected to conduct assessment across domains as well. However, most of the state-of-the-art automatic dialogue evaluation metrics (ADMs) are not designed for multi-domain evaluation. We are motivated to design a general and robust framework, MDD-Eval, to address the problem. Specifically, we first train a teacher evaluator with human-annotated data to acquire a rating skill to tell good dialogue responses from bad ones in a particular domain and then, adopt a self-training strategy to train a new evaluator with teacher-annotated multi-domain data, that helps the new evaluator to generalize across multiple domains. MDD-Eval is extensively assessed on six dialogue evaluation benchmarks. Empirical results show that the MDD-Eval framework achieves a strong performance with an absolute improvement of 7% over the state-of-the-art ADMs in terms of mean Spearman correlation scores across all the evaluation benchmarks.