 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlignment Pretraining: AI Discourse Causes Self-Fulfilling (Mis)alignment
Jan 15, 2026Pretraining corpora contain extensive discourse about AI systems, yet the causal influence of this discourse on downstream alignment remains poorly understood. If prevailing descriptions of AI behaviour are predominantly negative, LLMs may internalise corresponding behavioural priors, giving rise to self-fulfilling misalignment. This paper provides the first controlled study of this hypothesis by pretraining 6.9B-parameter LLMs with varying amounts of (mis)alignment discourse. We find that discussion of AI contributes to misalignment. Upsampling synthetic training documents about AI misalignment leads to a notable increase in misaligned behaviour. Conversely, upsampling documents about aligned behaviour reduces misalignment scores from 45% to 9%. We consider this evidence of self-fulfilling alignment. These effects are dampened, but persist through post-training. Our findings establish the study of how pretraining data shapes alignment priors, or alignment pretraining, as a complement to post-training. We recommend practitioners pretrain for alignment as well as capabilities. Our models and datasets are available at alignmentpretraining.ai
DeepFleet: Multi-Agent Foundation Models for Mobile Robots
Aug 12, 2025
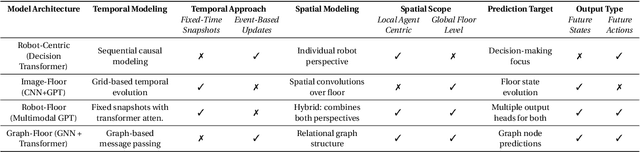
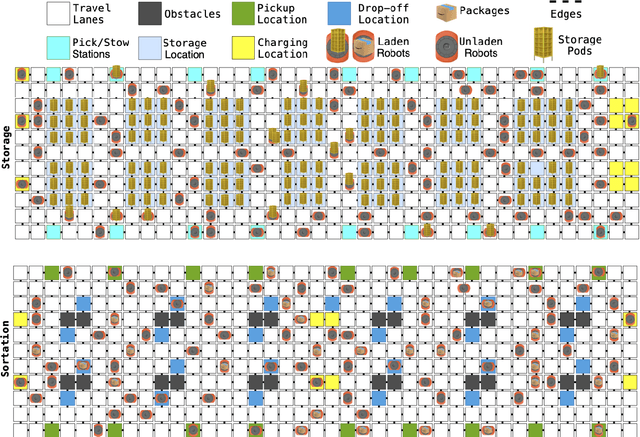
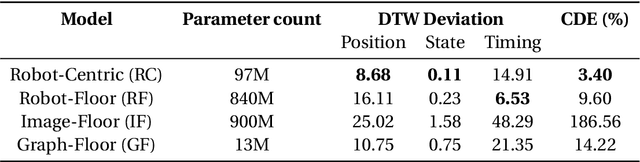
We introduce DeepFleet, a suite of foundation models designed to support coordination and planning for large-scale mobile robot fleets. These models are trained on fleet movement data, including robot positions, goals, and interactions, from hundreds of thousands of robots in Amazon warehouses worldwide. DeepFleet consists of four architectures that each embody a distinct inductive bias and collectively explore key points in the design space for multi-agent foundation models: the robot-centric (RC) model is an autoregressive decision transformer operating on neighborhoods of individual robots; the robot-floor (RF) model uses a transformer with cross-attention between robots and the warehouse floor; the image-floor (IF) model applies convolutional encoding to a multi-channel image representation of the full fleet; and the graph-floor (GF) model combines temporal attention with graph neural networks for spatial relationships. In this paper, we describe these models and present our evaluation of the impact of these design choices on prediction task performance. We find that the robot-centric and graph-floor models, which both use asynchronous robot state updates and incorporate the localized structure of robot interactions, show the most promise. We also present experiments that show that these two models can make effective use of larger warehouses operation datasets as the models are scaled up.
Accenture-NVS1: A Novel View Synthesis Dataset
Mar 24, 2025This paper introduces ACC-NVS1, a specialized dataset designed for research on Novel View Synthesis specifically for airborne and ground imagery. Data for ACC-NVS1 was collected in Austin, TX and Pittsburgh, PA in 2023 and 2024. The collection encompasses six diverse real-world scenes captured from both airborne and ground cameras, resulting in a total of 148,000 images. ACC-NVS1 addresses challenges such as varying altitudes and transient objects. This dataset is intended to supplement existing datasets, providing additional resources for comprehensive research, rather than serving as a benchmark.
Steering Language Model Refusal with Sparse Autoencoders
Nov 18, 2024



Responsible practices for deploying language models include guiding models to recognize and refuse answering prompts that are considered unsafe, while complying with safe prompts. Achieving such behavior typically requires updating model weights, which is costly and inflexible. We explore opportunities to steering model activations at inference time, which does not require updating weights. Using sparse autoencoders, we identify and steer features in Phi-3 Mini that mediate refusal behavior. We find that feature steering can improve Phi-3 Minis robustness to jailbreak attempts across various harms, including challenging multi-turn attacks. However, we discover that feature steering can adversely affect overall performance on benchmarks. These results suggest that identifying steerable mechanisms for refusal via sparse autoencoders is a promising approach for enhancing language model safety, but that more research is needed to mitigate feature steerings adverse effects on performance.
Composable Interventions for Language Models
Jul 09, 2024



Test-time interventions for language models can enhance factual accuracy, mitigate harmful outputs, and improve model efficiency without costly retraining. But despite a flood of new methods, different types of interventions are largely developing independently. In practice, multiple interventions must be applied sequentially to the same model, yet we lack standardized ways to study how interventions interact. We fill this gap by introducing composable interventions, a framework to study the effects of using multiple interventions on the same language models, featuring new metrics and a unified codebase. Using our framework, we conduct extensive experiments and compose popular methods from three emerging intervention categories -- Knowledge Editing, Model Compression, and Machine Unlearning. Our results from 310 different compositions uncover meaningful interactions: compression hinders editing and unlearning, composing interventions hinges on their order of application, and popular general-purpose metrics are inadequate for assessing composability. Taken together, our findings showcase clear gaps in composability, suggesting a need for new multi-objective interventions. All of our code is public: https://github.com/hartvigsen-group/composable-interventions.
Recite, Reconstruct, Recollect: Memorization in LMs as a Multifaceted Phenomenon
Jun 25, 2024



Memorization in language models is typically treated as a homogenous phenomenon, neglecting the specifics of the memorized data. We instead model memorization as the effect of a set of complex factors that describe each sample and relate it to the model and corpus. To build intuition around these factors, we break memorization down into a taxonomy: recitation of highly duplicated sequences, reconstruction of inherently predictable sequences, and recollection of sequences that are neither. We demonstrate the usefulness of our taxonomy by using it to construct a predictive model for memorization. By analyzing dependencies and inspecting the weights of the predictive model, we find that different factors influence the likelihood of memorization differently depending on the taxonomic category.
Improving Black-box Robustness with In-Context Rewriting
Feb 15, 2024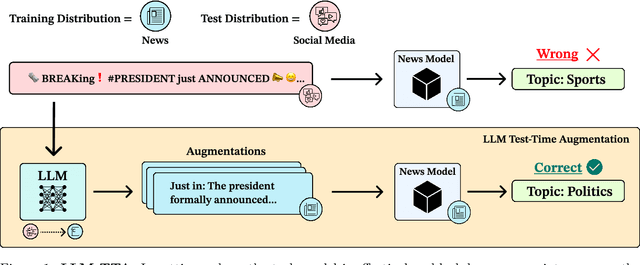
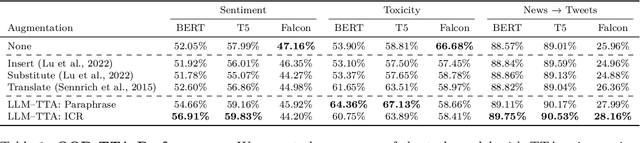
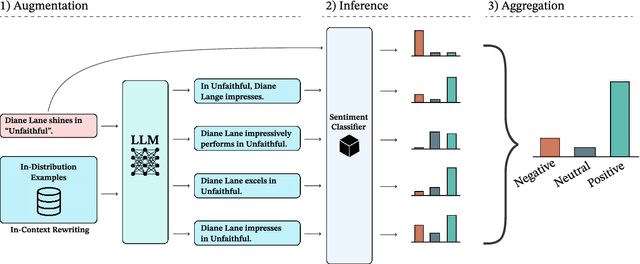
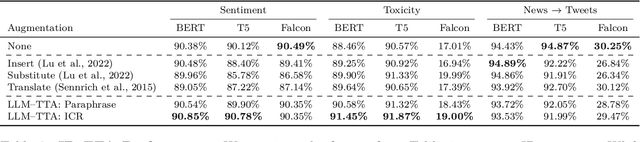
Machine learning models often excel on in-distribution (ID) data but struggle with unseen out-of-distribution (OOD) inputs. Most techniques for improving OOD robustness are not applicable to settings where the model is effectively a black box, such as when the weights are frozen, retraining is costly, or the model is leveraged via an API. Test-time augmentation (TTA) is a simple post-hoc technique for improving robustness that sidesteps black-box constraints by aggregating predictions across multiple augmentations of the test input. TTA has seen limited use in NLP due to the challenge of generating effective natural language augmentations. In this work, we propose LLM-TTA, which uses LLM-generated augmentations as TTA's augmentation function. LLM-TTA outperforms conventional augmentation functions across sentiment, toxicity, and news classification tasks for BERT and T5 models, with BERT's OOD robustness improving by an average of 4.30 percentage points without regressing average ID performance. We explore selectively augmenting inputs based on prediction entropy to reduce the rate of expensive LLM augmentations, allowing us to maintain performance gains while reducing the average number of generated augmentations by 57.76%. LLM-TTA is agnostic to the task model architecture, does not require OOD labels, and is effective across low and high-resource settings. We share our data, models, and code for reproducibility.
Pythia: A Suite for Analyzing Large Language Models Across Training and Scaling
Apr 03, 2023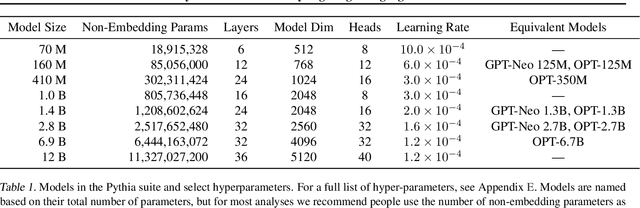
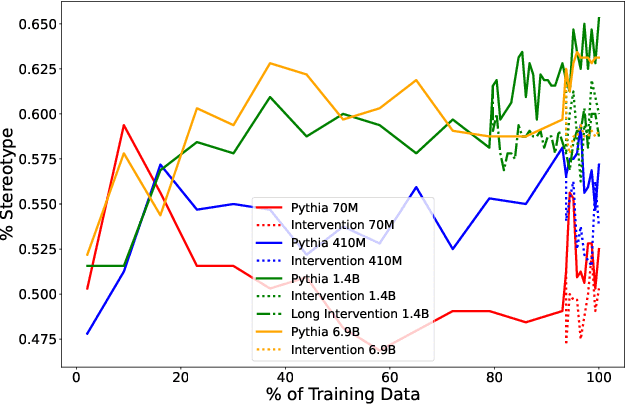

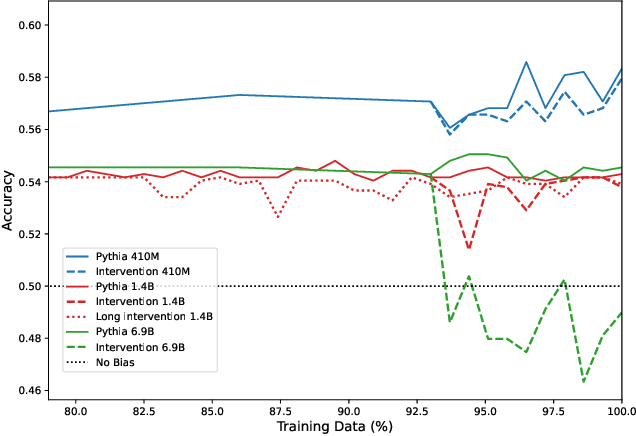
How do large language models (LLMs) develop and evolve over the course of training? How do these patterns change as models scale? To answer these questions, we introduce \textit{Pythia}, a suite of 16 LLMs all trained on public data seen in the exact same order and ranging in size from 70M to 12B parameters. We provide public access to 154 checkpoints for each one of the 16 models, alongside tools to download and reconstruct their exact training dataloaders for further study. We intend \textit{Pythia} to facilitate research in many areas, and we present several case studies including novel results in memorization, term frequency effects on few-shot performance, and reducing gender bias. We demonstrate that this highly controlled setup can be used to yield novel insights toward LLMs and their training dynamics. Trained models, analysis code, training code, and training data can be found at https://github.com/EleutherAI/pythia.