 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
IrokoBench: A New Benchmark for African Languages in the Age of Large Language Models
Jun 05, 2024

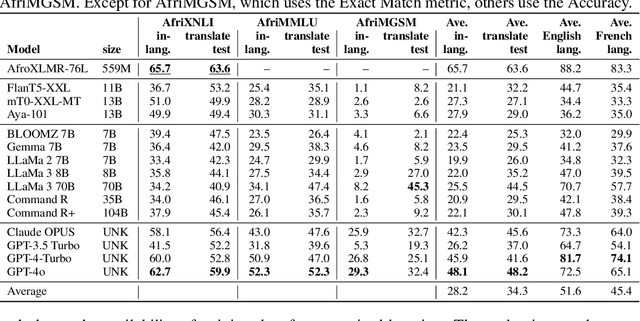
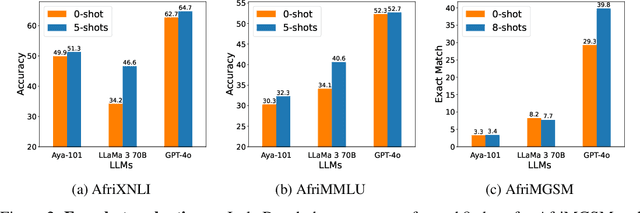
Despite the widespread adoption of Large language models (LLMs), their remarkable capabilities remain limited to a few high-resource languages. Additionally, many low-resource languages (e.g. African languages) are often evaluated only on basic text classification tasks due to the lack of appropriate or comprehensive benchmarks outside of high-resource languages. In this paper, we introduce IrokoBench -- a human-translated benchmark dataset for 16 typologically-diverse low-resource African languages covering three tasks: natural language inference~(AfriXNLI), mathematical reasoning~(AfriMGSM), and multi-choice knowledge-based QA~(AfriMMLU). We use IrokoBench to evaluate zero-shot, few-shot, and translate-test settings~(where test sets are translated into English) across 10 open and four proprietary LLMs. Our evaluation reveals a significant performance gap between high-resource languages~(such as English and French) and low-resource African languages. We observe a significant performance gap between open and proprietary models, with the highest performing open model, Aya-101 only at 58\% of the best-performing proprietary model GPT-4o performance. Machine translating the test set to English before evaluation helped to close the gap for larger models that are English-centric, like LLaMa 3 70B. These findings suggest that more efforts are needed to develop and adapt LLMs for African languages.
MasakhaPOS: Part-of-Speech Tagging for Typologically Diverse African Languages
May 23, 2023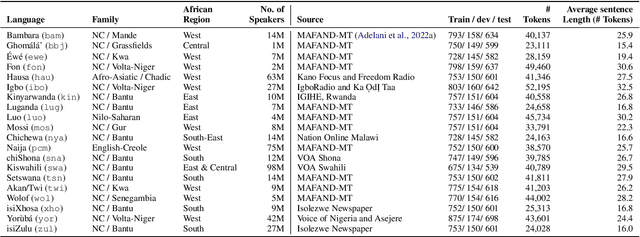
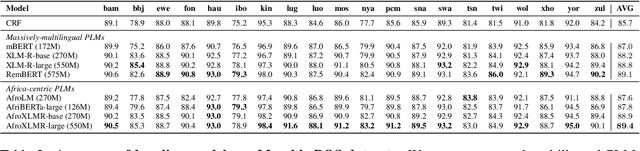
In this paper, we present MasakhaPOS, the largest part-of-speech (POS) dataset for 20 typologically diverse African languages. We discuss the challenges in annotating POS for these languages using the UD (universal dependencies) guidelines. We conducted extensive POS baseline experiments using conditional random field and several multilingual pre-trained language models. We applied various cross-lingual transfer models trained with data available in UD. Evaluating on the MasakhaPOS dataset, we show that choosing the best transfer language(s) in both single-source and multi-source setups greatly improves the POS tagging performance of the target languages, in particular when combined with cross-lingual parameter-efficient fine-tuning methods. Crucially, transferring knowledge from a language that matches the language family and morphosyntactic properties seems more effective for POS tagging in unseen languages.
MasakhaNEWS: News Topic Classification for African languages
Apr 19, 2023
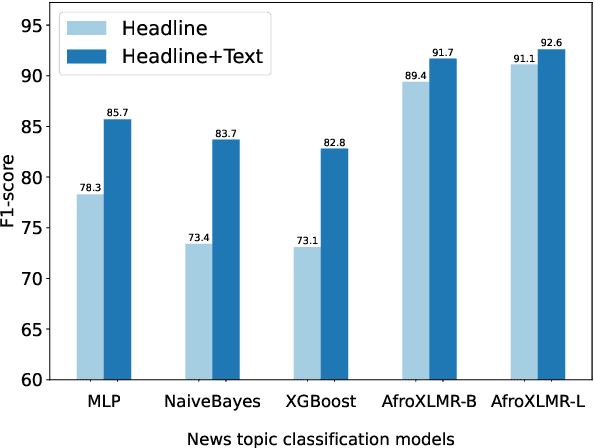
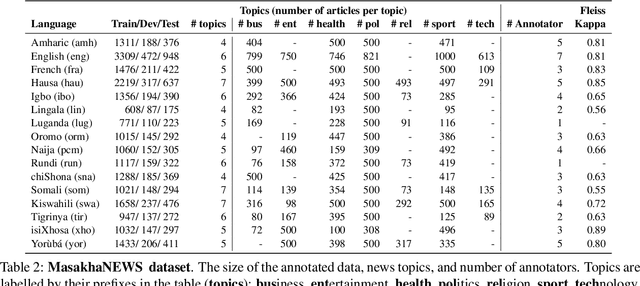
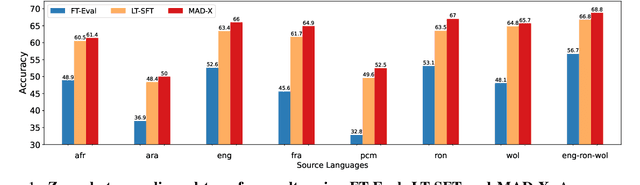
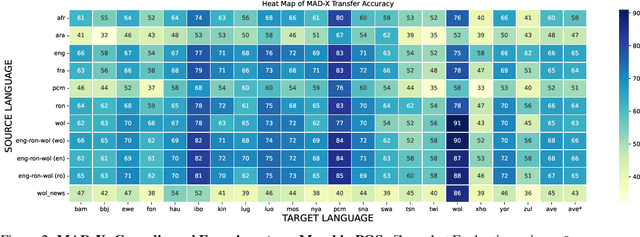
African languages are severely under-represented in NLP research due to lack of datasets covering several NLP tasks. While there are individual language specific datasets that are being expanded to different tasks, only a handful of NLP tasks (e.g. named entity recognition and machine translation) have standardized benchmark datasets covering several geographical and typologically-diverse African languages. In this paper, we develop MasakhaNEWS -- a new benchmark dataset for news topic classification covering 16 languages widely spoken in Africa. We provide an evaluation of baseline models by training classical machine learning models and fine-tuning several language models. Furthermore, we explore several alternatives to full fine-tuning of language models that are better suited for zero-shot and few-shot learning such as cross-lingual parameter-efficient fine-tuning (like MAD-X), pattern exploiting training (PET), prompting language models (like ChatGPT), and prompt-free sentence transformer fine-tuning (SetFit and Cohere Embedding API). Our evaluation in zero-shot setting shows the potential of prompting ChatGPT for news topic classification in low-resource African languages, achieving an average performance of 70 F1 points without leveraging additional supervision like MAD-X. In few-shot setting, we show that with as little as 10 examples per label, we achieved more than 90\% (i.e. 86.0 F1 points) of the performance of full supervised training (92.6 F1 points) leveraging the PET approach.
BibleTTS: a large, high-fidelity, multilingual, and uniquely African speech corpus
Jul 07, 2022
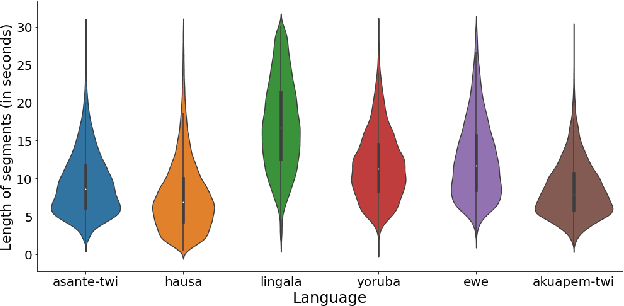

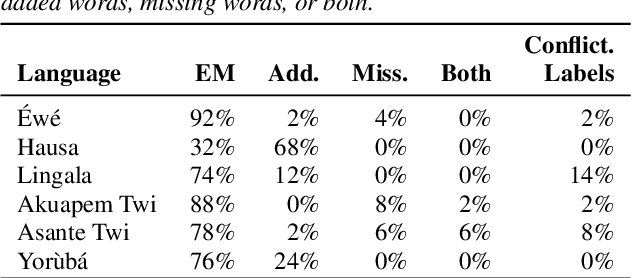
BibleTTS is a large, high-quality, open speech dataset for ten languages spoken in Sub-Saharan Africa. The corpus contains up to 86 hours of aligned, studio quality 48kHz single speaker recordings per language, enabling the development of high-quality text-to-speech models. The ten languages represented are: Akuapem Twi, Asante Twi, Chichewa, Ewe, Hausa, Kikuyu, Lingala, Luganda, Luo, and Yoruba. This corpus is a derivative work of Bible recordings made and released by the Open.Bible project from Biblica. We have aligned, cleaned, and filtered the original recordings, and additionally hand-checked a subset of the alignments for each language. We present results for text-to-speech models with Coqui TTS. The data is released under a commercial-friendly CC-BY-SA license.
The Makerere Radio Speech Corpus: A Luganda Radio Corpus for Automatic Speech Recognition
Jun 20, 2022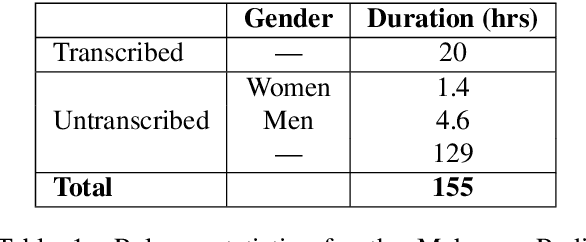
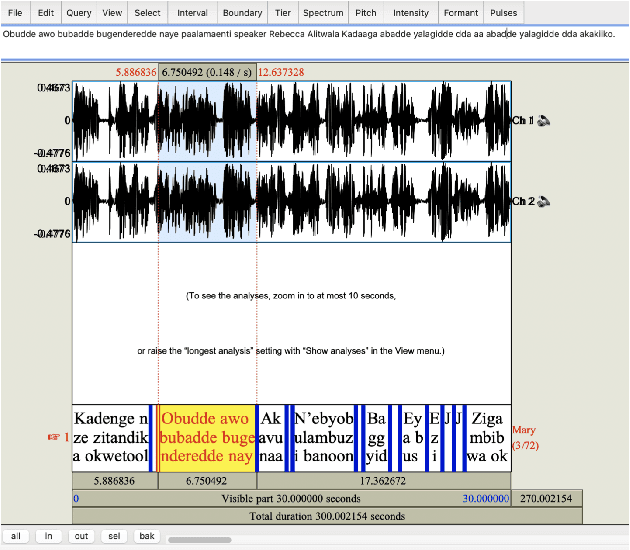

Building a usable radio monitoring automatic speech recognition (ASR) system is a challenging task for under-resourced languages and yet this is paramount in societies where radio is the main medium of public communication and discussions. Initial efforts by the United Nations in Uganda have proved how understanding the perceptions of rural people who are excluded from social media is important in national planning. However, these efforts are being challenged by the absence of transcribed speech datasets. In this paper, The Makerere Artificial Intelligence research lab releases a Luganda radio speech corpus of 155 hours. To our knowledge, this is the first publicly available radio dataset in sub-Saharan Africa. The paper describes the development of the voice corpus and presents baseline Luganda ASR performance results using Coqui STT toolkit, an open source speech recognition toolkit.
A Few Thousand Translations Go a Long Way! Leveraging Pre-trained Models for African News Translation
May 04, 2022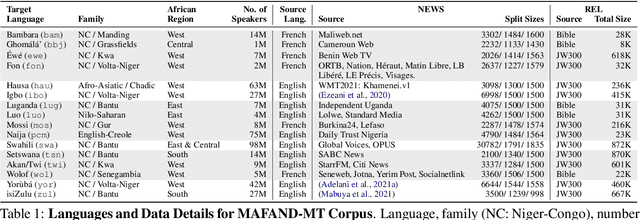
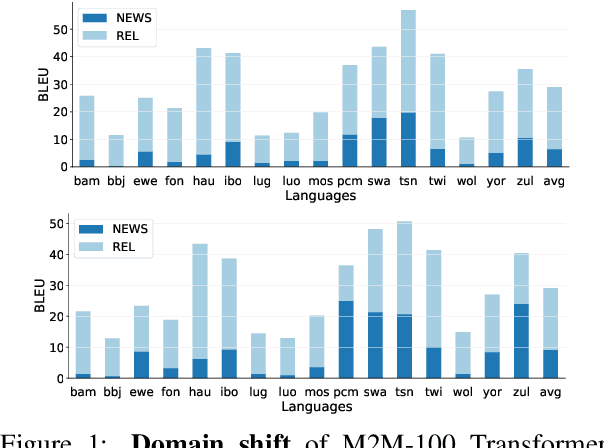

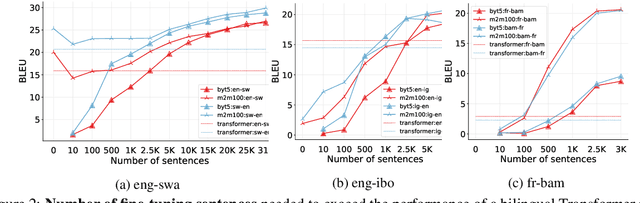
Recent advances in the pre-training of language models leverage large-scale datasets to create multilingual models. However, low-resource languages are mostly left out in these datasets. This is primarily because many widely spoken languages are not well represented on the web and therefore excluded from the large-scale crawls used to create datasets. Furthermore, downstream users of these models are restricted to the selection of languages originally chosen for pre-training. This work investigates how to optimally leverage existing pre-trained models to create low-resource translation systems for 16 African languages. We focus on two questions: 1) How can pre-trained models be used for languages not included in the initial pre-training? and 2) How can the resulting translation models effectively transfer to new domains? To answer these questions, we create a new African news corpus covering 16 languages, of which eight languages are not part of any existing evaluation dataset. We demonstrate that the most effective strategy for transferring both to additional languages and to additional domains is to fine-tune large pre-trained models on small quantities of high-quality translation data.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021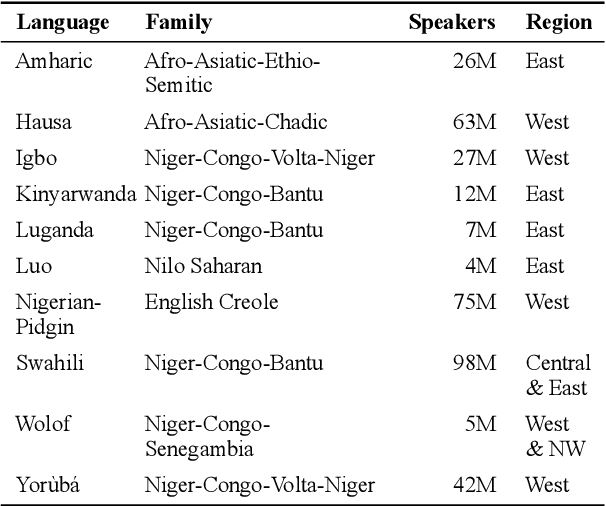

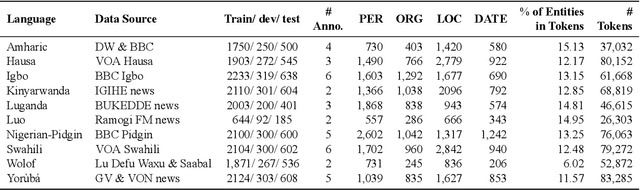
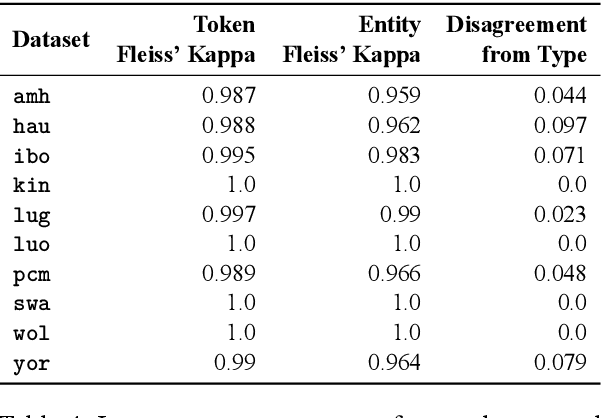
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Keyword Spotter Model for Crop Pest and Disease Monitoring from Community Radio Data
Oct 05, 2019

In societies with well developed internet infrastructure, social media is the leading medium of communication for various social issues especially for breaking news situations. In rural Uganda however, public community radio is still a dominant means for news dissemination. Community radio gives audience to the general public especially to individuals living in rural areas, and thus plays an important role in giving a voice to those living in the broadcast area. It is an avenue for participatory communication and a tool relevant in both economic and social development.This is supported by the rise to ubiquity of mobile phones providing access to phone-in or text-in talk shows. In this paper, we describe an approach to analysing the readily available community radio data with machine learning-based speech keyword spotting techniques. We identify the keywords of interest related to agriculture and build models to automatically identify these keywords from audio streams. Our contribution through these techniques is a cost-efficient and effective way to monitor food security concerns particularly in rural areas. Through keyword spotting and radio talk show analysis, issues such as crop diseases, pests, drought and famine can be captured and fed into an early warning system for stakeholders and policy makers.