 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVeri
Papers and Code
Veri-Sure: A Contract-Aware Multi-Agent Framework with Temporal Tracing and Formal Verification for Correct RTL Code Generation
Jan 27, 2026In the rapidly evolving field of Electronic Design Automation (EDA), the deployment of Large Language Models (LLMs) for Register-Transfer Level (RTL) design has emerged as a promising direction. However, silicon-grade correctness remains bottlenecked by: (i) limited test coverage and reliability of simulation-centric evaluation, (ii) regressions and repair hallucinations introduced by iterative debugging, and (iii) semantic drift as intent is reinterpreted across agent handoffs. In this work, we propose Veri-Sure, a multi-agent framework that establishes a design contract to align agents' intent and uses a patching mechanism guided by static dependency slicing to perform precise, localized repairs. By integrating a multi-branch verification pipeline that combines trace-driven temporal analysis with formal verification consisting of assertion-based checking and boolean equivalence proofs, Veri-Sure enables functional correctness beyond pure simulations. We also introduce VerilogEval-v2-EXT, extending the original benchmark with 53 more industrial-grade design tasks and stratified difficulty levels, and show that Veri-Sure achieves state-of-the-art verified-correct RTL code generation performance, surpassing standalone LLMs and prior agentic systems.
CRAFT: Continuous Reasoning and Agentic Feedback Tuning for Multimodal Text-to-Image Generation
Dec 23, 2025Recent work has shown that inference-time reasoning and reflection can improve text-to-image generation without retraining. However, existing approaches often rely on implicit, holistic critiques or unconstrained prompt rewrites, making their behavior difficult to interpret, control, or stop reliably. In contrast, large language models have benefited from explicit, structured forms of **thinking** based on verification, targeted correction, and early stopping. We introduce CRAFT (Continuous Reasoning and Agentic Feedback Tuning), a training-free, model-agnostic framework that brings this structured reasoning paradigm to multimodal image generation. CRAFT decomposes a prompt into dependency-structured visual questions, veries generated images using a vision-language model, and applies targeted prompt edits through an LLM agent only where constraints fail. The process iterates with an explicit stopping criterion once all constraints are satised, yielding an interpretable and controllable inference-time renement loop. Across multiple model families and challenging benchmarks, CRAFT consistently improves compositional accuracy, text rendering, and preference-based evaluations, with particularly strong gains for lightweight generators. Importantly, these improvements incur only a negligible inference-time overhead, allowing smaller or cheaper models to approach the quality of substantially more expensive systems. Our results suggest that explicitly structured, constraint-driven inference-time reasoning is a key ingredient for improving the reliability of multimodal generative models.
Veri-R1: Toward Precise and Faithful Claim Verification via Online Reinforcement Learning
Oct 02, 2025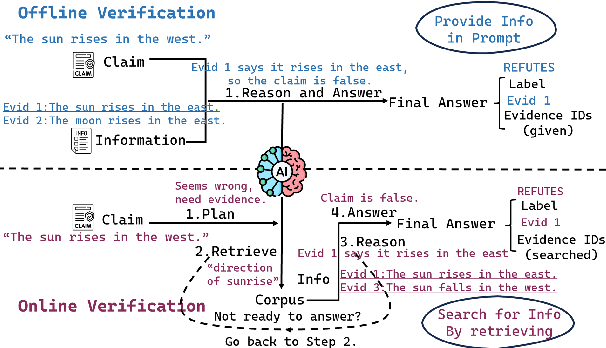
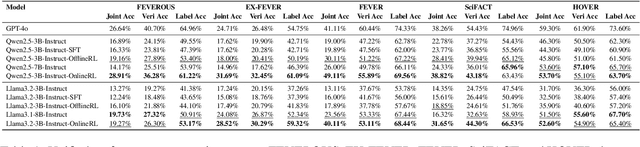
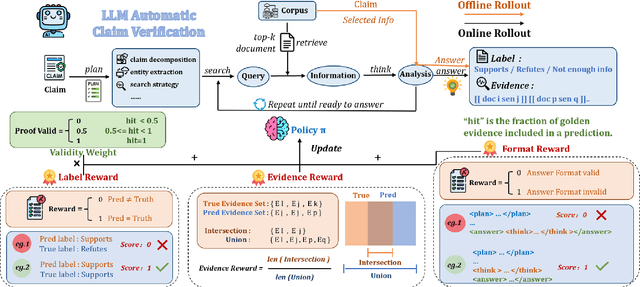

Claim verification with large language models (LLMs) has recently attracted considerable attention, owing to their superior reasoning capabilities and transparent verification pathways compared to traditional answer-only judgments. Online claim verification requires iterative evidence retrieval and reasoning, yet existing approaches mainly rely on prompt engineering or predesigned reasoning workflows without offering a unified training paradigm to improve necessary skills. Therefore, we introduce Veri-R1, an online reinforcement learning (RL) framework that enables an LLM to interact with a search engine and to receive reward signals that explicitly shape its planning, retrieval, and reasoning behaviors. The dynamic interaction between models and retrieval systems more accurately reflects real-world verification scenarios and fosters comprehensive verification skills. Empirical results show that Veri-R1 improves joint accuracy by up to 30% and doubles evidence score, often surpassing larger-scale counterparts. Ablation studies further reveal the impact of reward components and the link between output logits and label accuracy. Our results highlight the effectiveness of online RL for precise and faithful claim verification and provide a foundation for future research. We release our code to support community progress in LLM empowered claim verification.
Towards Verifiable Federated Unlearning: Framework, Challenges, and The Road Ahead
Oct 01, 2025Federated unlearning (FUL) enables removing the data influence from the model trained across distributed clients, upholding the right to be forgotten as mandated by privacy regulations. FUL facilitates a value exchange where clients gain privacy-preserving control over their data contributions, while service providers leverage decentralized computing and data freshness. However, this entire proposition is undermined because clients have no reliable way to verify that their data influence has been provably removed, as current metrics and simple notifications offer insufficient assurance. We envision unlearning verification becoming a pivotal and trust-by-design part of the FUL life-cycle development, essential for highly regulated and data-sensitive services and applications like healthcare. This article introduces veriFUL, a reference framework for verifiable FUL that formalizes verification entities, goals, approaches, and metrics. Specifically, we consolidate existing efforts and contribute new insights, concepts, and metrics to this domain. Finally, we highlight research challenges and identify potential applications and developments for verifiable FUL and veriFUL.
Similarity-based Outlier Detection for Noisy Object Re-Identification Using Beta Mixtures
Sep 10, 2025Object re-identification (Re-ID) methods are highly sensitive to label noise, which typically leads to significant performance degradation. We address this challenge by reframing Re-ID as a supervised image similarity task and adopting a Siamese network architecture trained to capture discriminative pairwise relationships. Central to our approach is a novel statistical outlier detection (OD) framework, termed Beta-SOD (Beta mixture Similarity-based Outlier Detection), which models the distribution of cosine similarities between embedding pairs using a two-component Beta distribution mixture model. We establish a novel identifiability result for mixtures of two Beta distributions, ensuring that our learning task is well-posed.The proposed OD step complements the Re-ID architecture combining binary cross-entropy, contrastive, and cosine embedding losses that jointly optimize feature-level similarity learning.We demonstrate the effectiveness of Beta-SOD in de-noising and Re-ID tasks for person Re-ID, on CUHK03 and Market-1501 datasets, and vehicle Re-ID, on VeRi-776 dataset. Our method shows superior performance compared to the state-of-the-art methods across various noise levels (10-30\%), demonstrating both robustness and broad applicability in noisy Re-ID scenarios. The implementation of Beta-SOD is available at: https://github.com/waqar3411/Beta-SOD
Better Safe Than Sorry? Overreaction Problem of Vision Language Models in Visual Emergency Recognition
May 21, 2025Vision-Language Models (VLMs) have demonstrated impressive capabilities in understanding visual content, but their reliability in safety-critical contexts remains under-explored. We introduce VERI (Visual Emergency Recognition Dataset), a carefully designed diagnostic benchmark of 200 images (100 contrastive pairs). Each emergency scene is matched with a visually similar but safe counterpart through multi-stage human verification and iterative refinement. Using a two-stage protocol - risk identification and emergency response - we evaluate 14 VLMs (2B-124B parameters) across medical emergencies, accidents, and natural disasters. Our analysis reveals a systematic overreaction problem: models excel at identifying real emergencies (70-100 percent success rate) but suffer from an alarming rate of false alarms, misidentifying 31-96 percent of safe situations as dangerous, with 10 scenarios failed by all models regardless of scale. This "better-safe-than-sorry" bias manifests primarily through contextual overinterpretation (88-93 percent of errors), challenging VLMs' reliability for safety applications. These findings highlight persistent limitations that are not resolved by increasing model scale, motivating targeted approaches for improving contextual safety assessment in visually misleading scenarios.
Zero-Knowledge Federated Learning: A New Trustworthy and Privacy-Preserving Distributed Learning Paradigm
Mar 18, 2025


Federated Learning (FL) has emerged as a promising paradigm in distributed machine learning, enabling collaborative model training while preserving data privacy. However, despite its many advantages, FL still contends with significant challenges -- most notably regarding security and trust. Zero-Knowledge Proofs (ZKPs) offer a potential solution by establishing trust and enhancing system integrity throughout the FL process. Although several studies have explored ZKP-based FL (ZK-FL), a systematic framework and comprehensive analysis are still lacking. This article makes two key contributions. First, we propose a structured ZK-FL framework that categorizes and analyzes the technical roles of ZKPs across various FL stages and tasks. Second, we introduce a novel algorithm, Verifiable Client Selection FL (Veri-CS-FL), which employs ZKPs to refine the client selection process. In Veri-CS-FL, participating clients generate verifiable proofs for the performance metrics of their local models and submit these concise proofs to the server for efficient verification. The server then selects clients with high-quality local models for uploading, subsequently aggregating the contributions from these selected clients. By integrating ZKPs, Veri-CS-FL not only ensures the accuracy of performance metrics but also fortifies trust among participants while enhancing the overall efficiency and security of FL systems.
CLIP-SENet: CLIP-based Semantic Enhancement Network for Vehicle Re-identification
Feb 24, 2025Vehicle re-identification (Re-ID) is a crucial task in intelligent transportation systems (ITS), aimed at retrieving and matching the same vehicle across different surveillance cameras. Numerous studies have explored methods to enhance vehicle Re-ID by focusing on semantic enhancement. However, these methods often rely on additional annotated information to enable models to extract effective semantic features, which brings many limitations. In this work, we propose a CLIP-based Semantic Enhancement Network (CLIP-SENet), an end-to-end framework designed to autonomously extract and refine vehicle semantic attributes, facilitating the generation of more robust semantic feature representations. Inspired by zero-shot solutions for downstream tasks presented by large-scale vision-language models, we leverage the powerful cross-modal descriptive capabilities of the CLIP image encoder to initially extract general semantic information. Instead of using a text encoder for semantic alignment, we design an adaptive fine-grained enhancement module (AFEM) to adaptively enhance this general semantic information at a fine-grained level to obtain robust semantic feature representations. These features are then fused with common Re-ID appearance features to further refine the distinctions between vehicles. Our comprehensive evaluation on three benchmark datasets demonstrates the effectiveness of CLIP-SENet. Our approach achieves new state-of-the-art performance, with 92.9% mAP and 98.7% Rank-1 on VeRi-776 dataset, 90.4% Rank-1 and 98.7% Rank-5 on VehicleID dataset, and 89.1% mAP and 97.9% Rank-1 on the more challenging VeRi-Wild dataset.
Data Pruning Can Do More: A Comprehensive Data Pruning Approach for Object Re-identification
Dec 13, 2024



Previous studies have demonstrated that not each sample in a dataset is of equal importance during training. Data pruning aims to remove less important or informative samples while still achieving comparable results as training on the original (untruncated) dataset, thereby reducing storage and training costs. However, the majority of data pruning methods are applied to image classification tasks. To our knowledge, this work is the first to explore the feasibility of these pruning methods applied to object re-identification (ReID) tasks, while also presenting a more comprehensive data pruning approach. By fully leveraging the logit history during training, our approach offers a more accurate and comprehensive metric for quantifying sample importance, as well as correcting mislabeled samples and recognizing outliers. Furthermore, our approach is highly efficient, reducing the cost of importance score estimation by 10 times compared to existing methods. Our approach is a plug-and-play, architecture-agnostic framework that can eliminate/reduce 35%, 30%, and 5% of samples/training time on the VeRi, MSMT17 and Market1501 datasets, respectively, with negligible loss in accuracy (< 0.1%). The lists of important, mislabeled, and outlier samples from these ReID datasets are available at https://github.com/Zi-Y/data-pruning-reid.
Cosmos-LLaVA: Chatting with the Visual Cosmos-LLaVA: Görselle Sohbet Etmek
Dec 03, 2024In this study, a Turkish visual instruction model was developed and various model architectures and dataset combinations were analysed to improve the performance of this model. The Cosmos-LLaVA model, which is built by combining different large language models and image coders, is designed to overcome the deficiencies in the Turkish language. In the experiments, the effects of fine-tuning with various datasets on the model performance are analysed in detail. The results show that model architecture and dataset selection have a significant impact on performance. Bu \c{c}al{\i}\c{s}mada bir T\"urk\c{c}e g\"orsel talimat modeli geli\c{s}tirilerek bu modelin performans{\i}n{\i} art{\i}rmaya y\"onelik \c{c}e\c{s}itli model mimarileri ve veri k\"umesi kombinasyonlar{\i} derinlemesine incelenmi\c{s}tir. Farkl{\i} b\"uy\"uk dil modelleri ve g\"or\"unt\"u kodlay{\i}c{\i}lar{\i}n{\i}n bir araya getirilmesiyle olu\c{s}turulan Cosmos-LLaVA modeli, T\"urk\c{c}e dilindeki eksiklikleri gidermeye y\"onelik olarak tasarlanm{\i}\c{s}t{\i}r. Yap{\i}lan deneylerde, \c{c}e\c{s}itli veri k\"umeleri ile yap{\i}lan ince ayarlar{\i}n model performans{\i}n{\i} nas{\i}l etkiledi\u{g}i detayl{\i} olarak ele al{\i}nm{\i}\c{s}t{\i}r. Sonu\c{c}lar, model mimarisi ve veri k\"umesi se\c{c}iminin performans \"uzerinde \"onemli bir etkiye sahip oldu\u{g}unu g\"ostermektedir.