 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimilarity-based Outlier Detection for Noisy Object Re-Identification Using Beta Mixtures
Sep 10, 2025Object re-identification (Re-ID) methods are highly sensitive to label noise, which typically leads to significant performance degradation. We address this challenge by reframing Re-ID as a supervised image similarity task and adopting a Siamese network architecture trained to capture discriminative pairwise relationships. Central to our approach is a novel statistical outlier detection (OD) framework, termed Beta-SOD (Beta mixture Similarity-based Outlier Detection), which models the distribution of cosine similarities between embedding pairs using a two-component Beta distribution mixture model. We establish a novel identifiability result for mixtures of two Beta distributions, ensuring that our learning task is well-posed.The proposed OD step complements the Re-ID architecture combining binary cross-entropy, contrastive, and cosine embedding losses that jointly optimize feature-level similarity learning.We demonstrate the effectiveness of Beta-SOD in de-noising and Re-ID tasks for person Re-ID, on CUHK03 and Market-1501 datasets, and vehicle Re-ID, on VeRi-776 dataset. Our method shows superior performance compared to the state-of-the-art methods across various noise levels (10-30\%), demonstrating both robustness and broad applicability in noisy Re-ID scenarios. The implementation of Beta-SOD is available at: https://github.com/waqar3411/Beta-SOD
Trajectory Data Mining and Trip Travel Time Prediction on Specific Roads
Jul 09, 2024



Predicting a trip's travel time is essential for route planning and navigation applications. The majority of research is based on international data that does not apply to Pakistan's road conditions. We designed a complete pipeline for mining trajectories from sensors data. On this data, we employed state-of-the-art approaches, including a shallow artificial neural network, a deep multi-layered perceptron, and a long-short-term memory, to explore the issue of travel time prediction on frequent routes. The experimental results demonstrate an average prediction error ranging from 30 seconds to 1.2 minutes on trips lasting 10 minutes to 60 minutes on six most frequent routes in regions of Islamabad, Pakistan.
Urdu Speech and Text Based Sentiment Analyzer
Jul 19, 2022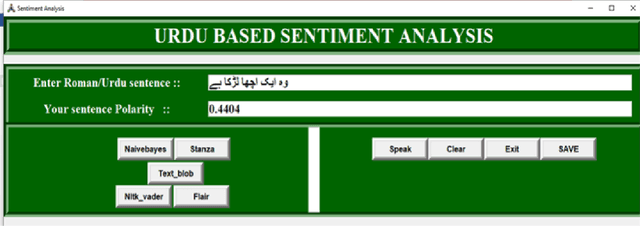
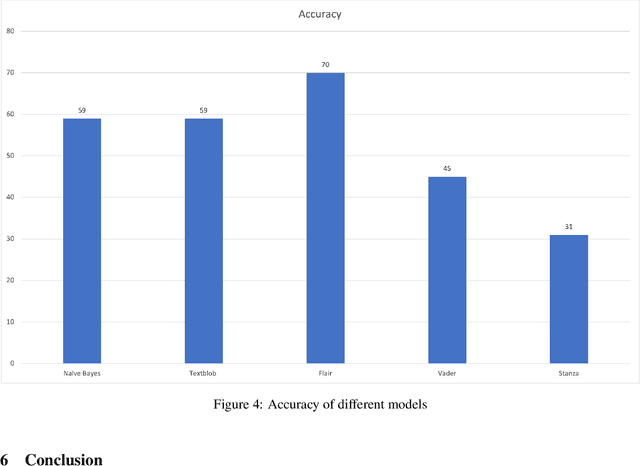
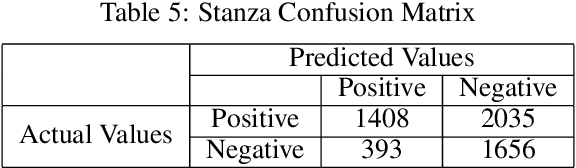
Discovering what other people think has always been a key aspect of our information-gathering strategy. People can now actively utilize information technology to seek out and comprehend the ideas of others, thanks to the increased availability and popularity of opinion-rich resources such as online review sites and personal blogs. Because of its crucial function in understanding people's opinions, sentiment analysis (SA) is a crucial task. Existing research, on the other hand, is primarily focused on the English language, with just a small amount of study devoted to low-resource languages. For sentiment analysis, this work presented a new multi-class Urdu dataset based on user evaluations. The tweeter website was used to get Urdu dataset. Our proposed dataset includes 10,000 reviews that have been carefully classified into two categories by human experts: positive, negative. The primary purpose of this research is to construct a manually annotated dataset for Urdu sentiment analysis and to establish the baseline result. Five different lexicon- and rule-based algorithms including Naivebayes, Stanza, Textblob, Vader, and Flair are employed and the experimental results show that Flair with an accuracy of 70% outperforms other tested algorithms.
Human Activity Recognition using Multi-Head CNN followed by LSTM
Feb 21, 2020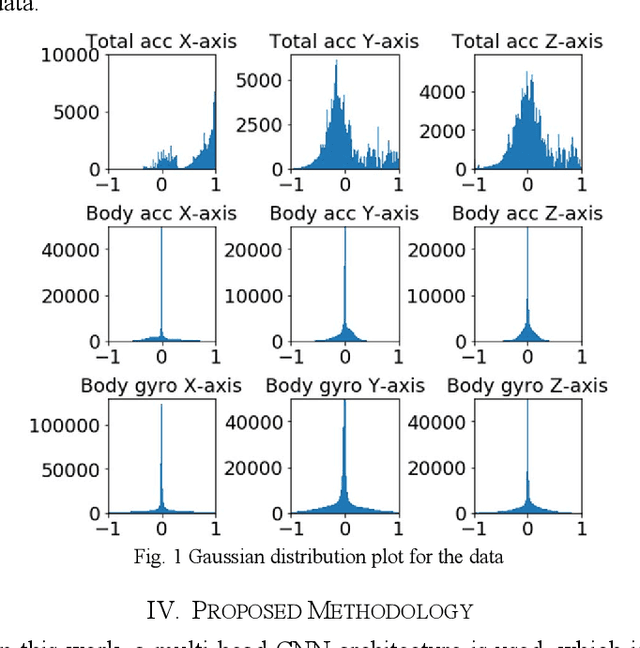

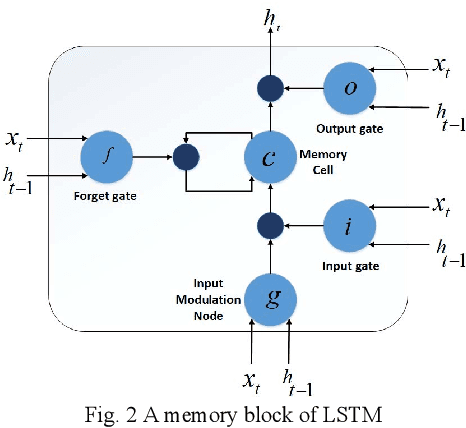

This study presents a novel method to recognize human physical activities using CNN followed by LSTM. Achieving high accuracy by traditional machine learning algorithms, (such as SVM, KNN and random forest method) is a challenging task because the data acquired from the wearable sensors like accelerometer and gyroscope is a time-series data. So, to achieve high accuracy, we propose a multi-head CNN model comprising of three CNNs to extract features for the data acquired from different sensors and all three CNNs are then merged, which are followed by an LSTM layer and a dense layer. The configuration of all three CNNs is kept the same so that the same number of features are obtained for every input to CNN. By using the proposed method, we achieve state-of-the-art accuracy, which is comparable to traditional machine learning algorithms and other deep neural network algorithms.