 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUrdu Speech and Text Based Sentiment Analyzer
Jul 19, 2022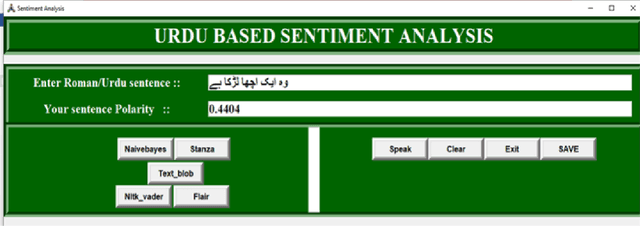
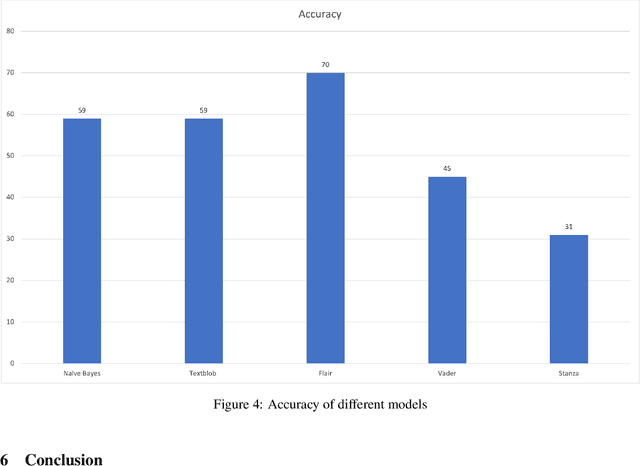
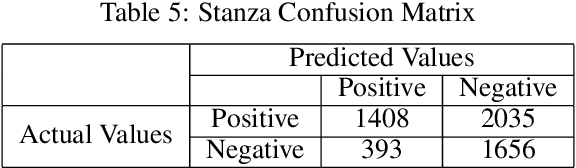
Discovering what other people think has always been a key aspect of our information-gathering strategy. People can now actively utilize information technology to seek out and comprehend the ideas of others, thanks to the increased availability and popularity of opinion-rich resources such as online review sites and personal blogs. Because of its crucial function in understanding people's opinions, sentiment analysis (SA) is a crucial task. Existing research, on the other hand, is primarily focused on the English language, with just a small amount of study devoted to low-resource languages. For sentiment analysis, this work presented a new multi-class Urdu dataset based on user evaluations. The tweeter website was used to get Urdu dataset. Our proposed dataset includes 10,000 reviews that have been carefully classified into two categories by human experts: positive, negative. The primary purpose of this research is to construct a manually annotated dataset for Urdu sentiment analysis and to establish the baseline result. Five different lexicon- and rule-based algorithms including Naivebayes, Stanza, Textblob, Vader, and Flair are employed and the experimental results show that Flair with an accuracy of 70% outperforms other tested algorithms.
Implementing a Chatbot Solution for Learning Management System
Jun 30, 2022
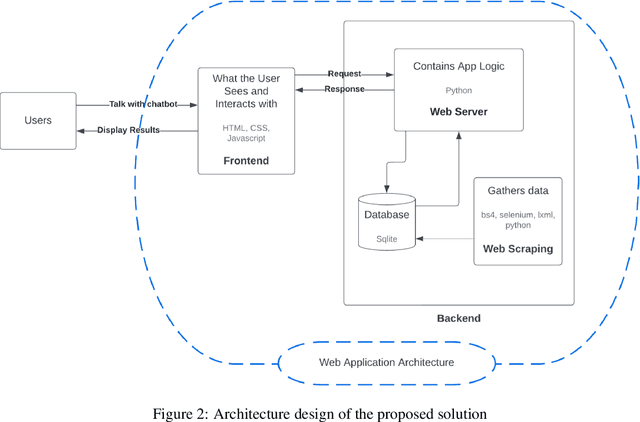
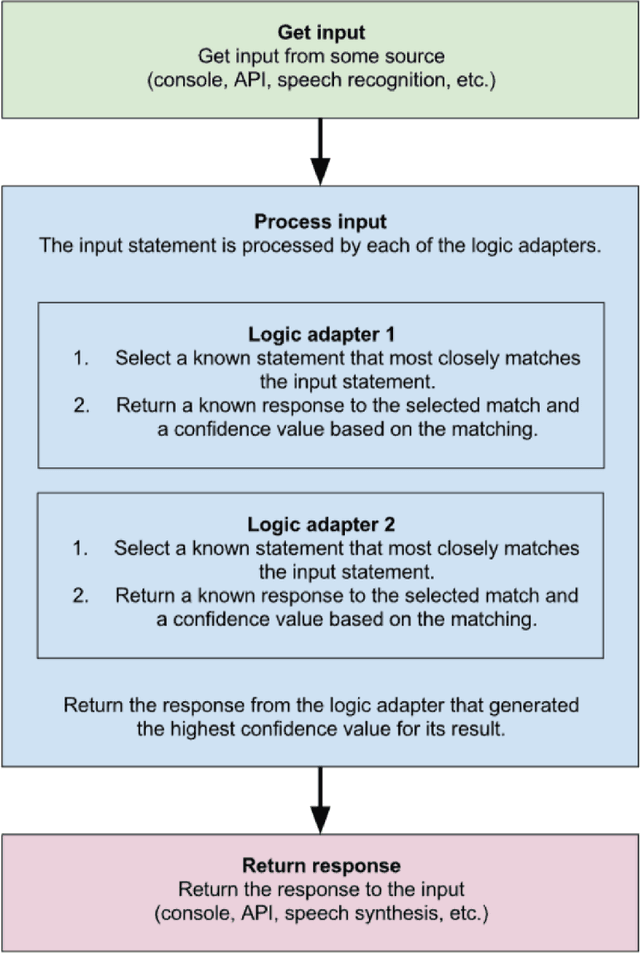
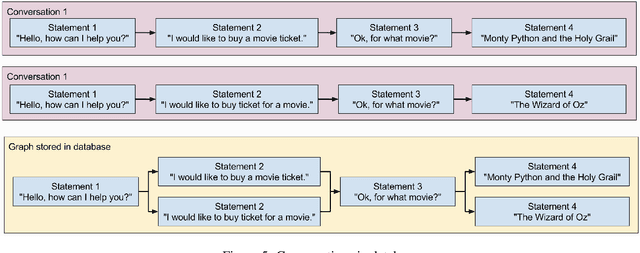
Innovation is a key component in trying new solutions for the students to learn efficiently and in ways that correspond to their own experience, where chatbots are one of these new solutions. One of the main problem that chatbots face today is to mimic human language, where they try to find the best answer to an input, which is not how a human conversation usually works, rather taking into account the previous messages and building onto them. Extreme programming methodology was chosen to use integrate ChatterBot, Pyside2, web scraping and Tampermonkey into Blackboard as a test case. Problems occurred with the bot and more training was needed for the bot to work perfectly, but the integration and web scraping worked, giving us a chatbot that was able to talk with. We showed the plausibility of integrating an AI bot in an educational setting.
OSN Dashboard Tool For Sentiment Analysis
Jun 14, 2022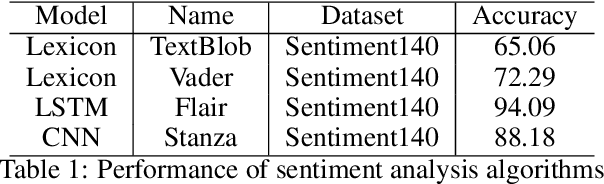


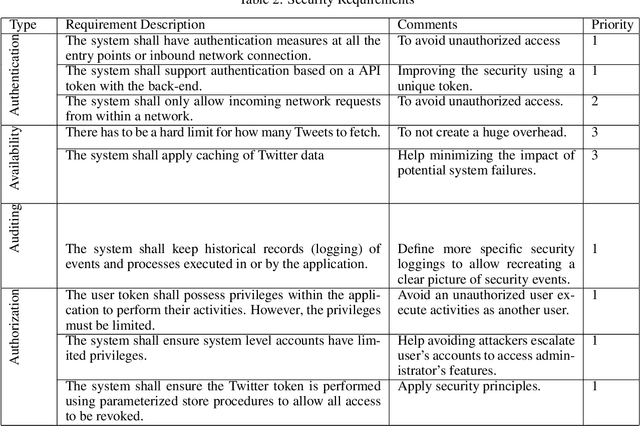
The amount of opinionated data on the internet is rapidly increasing. More and more people are sharing their ideas and opinions in reviews, discussion forums, microblogs and general social media. As opinions are central in all human activities, sentiment analysis has been applied to gain insights in this type of data. There are proposed several approaches for sentiment classification. The major drawback is the lack of standardized solutions for classification and high-level visualization. In this study, a sentiment analyzer dashboard for online social networking analysis is proposed. This, to enable people gaining insights in topics interesting to them. The tool allows users to run the desired sentiment analysis algorithm in the dashboard. In addition to providing several visualization types, the dashboard facilitates raw data results from the sentiment classification which can be downloaded for further analysis.
Sentiment analysis on electricity twitter posts
Jun 10, 2022
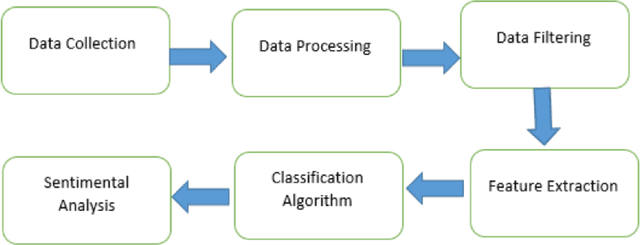
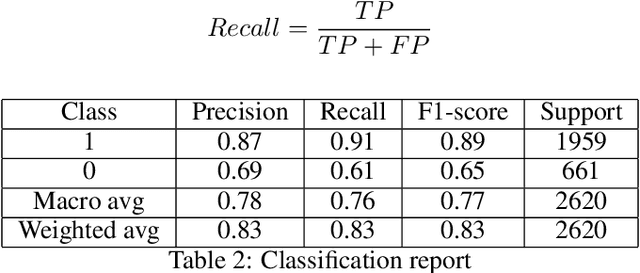
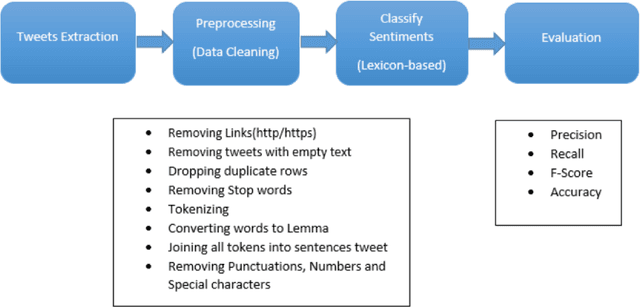
In today's world, everyone is expressive in some way, and the focus of this project is on people's opinions about rising electricity prices in United Kingdom and India using data from Twitter, a micro-blogging platform on which people post messages, known as tweets. Because many people's incomes are not good and they have to pay so many taxes and bills, maintaining a home has become a disputed issue these days. Despite the fact that Government offered subsidy schemes to compensate people electricity bills but it is not welcomed by people. In this project, the aim is to perform sentiment analysis on people's expressions and opinions expressed on Twitter. In order to grasp the electricity prices opinion, it is necessary to carry out sentiment analysis for the government and consumers in energy market. Furthermore, text present on these medias are unstructured in nature, so to process them we firstly need to pre-process the data. There are so many feature extraction techniques such as Bag of Words, TF-IDF (Term Frequency-Inverse Document Frequency), word embedding, NLP based features like word count. In this project, we analysed the impact of feature TF-IDF word level on electricity bills dataset of sentiment analysis. We found that by using TF-IDF word level performance of sentiment analysis is 3-4 higher than using N-gram features. Analysis is done using four classification algorithms including Naive Bayes, Decision Tree, Random Forest, and Logistic Regression and considering F-Score, Accuracy, Precision, and Recall performance parameters.
Using GAN-based models to sentimental analysis on imbalanced datasets in education domain
Aug 26, 2021
While the whole world is still struggling with the COVID-19 pandemic, online learning and home office become more common. Many schools transfer their courses teaching to the online classroom. Therefore, it is significant to mine the students' feedback and opinions from their reviews towards studies so that both schools and teachers can know where they need to improve. This paper trains machine learning and deep learning models using both balanced and imbalanced datasets for sentiment classification. Two SOTA category-aware text generation GAN models: CatGAN and SentiGAN, are utilized to synthesize text used to balance the highly imbalanced dataset. Results on three datasets with different imbalance degree from distinct domains show that when using generated text to balance the dataset, the F1-score of machine learning and deep learning model on sentiment classification increases 2.79% ~ 9.28%. Also, the results indicate that the average growth degree for CR100k is higher than CR23k, the average growth degree for deep learning is more increased than machine learning algorithms, and the average growth degree for more complex deep learning models is more increased than simpler deep learning models in experiments.
The Potential of Machine Learning and NLP for Handling Students' Feedback
Nov 07, 2020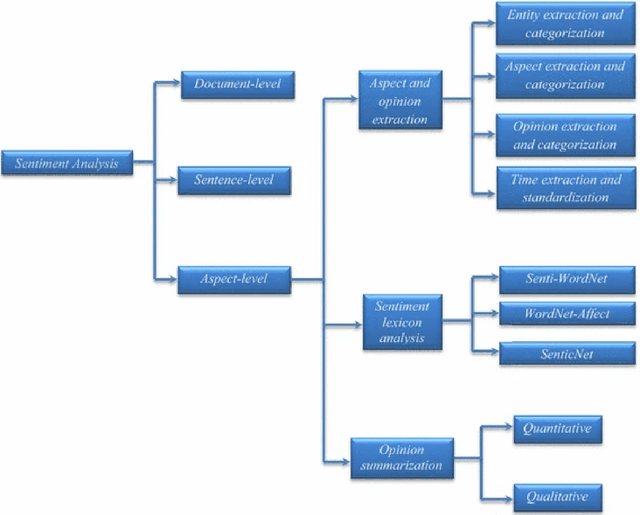
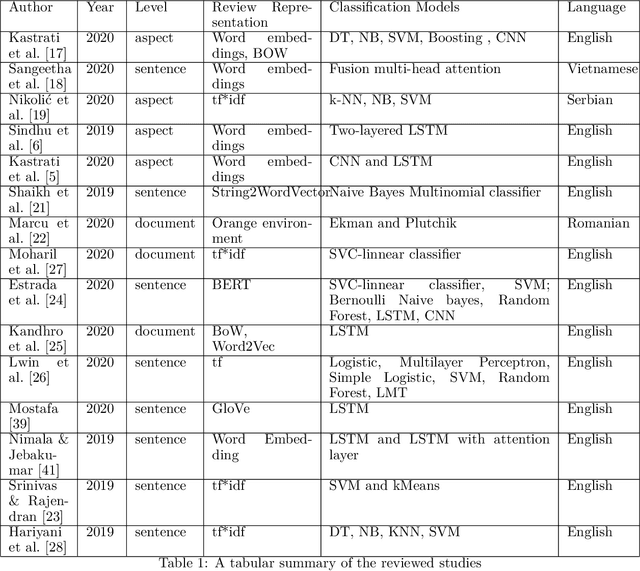
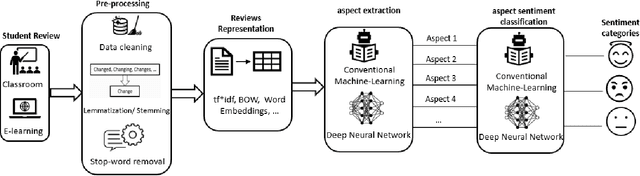
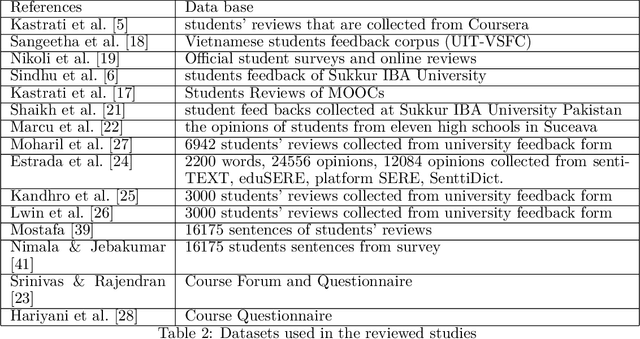
This article provides a review of the literature of students' feedback papers published in recent years employing data mining techniques. In particular, the focus is to highlight those papers which are using either machine learning or deep learning approaches. Student feedback assessment is a hot topic which has attracted a lot of attention in recent times. The importance has increased manyfold due to the recent pandemic outbreak which pushed many colleges and universities to shift teaching from on-campus physical classes to online via eLearning platforms and tools including massive open online courses (MOOCs). Assessing student feedback is even more important now. This short survey paper, therefore, highlights recent trends in the natural language processing domain on the topic of automatic student feedback assessment. It presents techniques commonly utilized in this domain and discusses some future research directions.