 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep DIC: Deep Learning-Based Digital Image Correlation for End-to-End Displacement and Strain Measurement
Oct 26, 2021

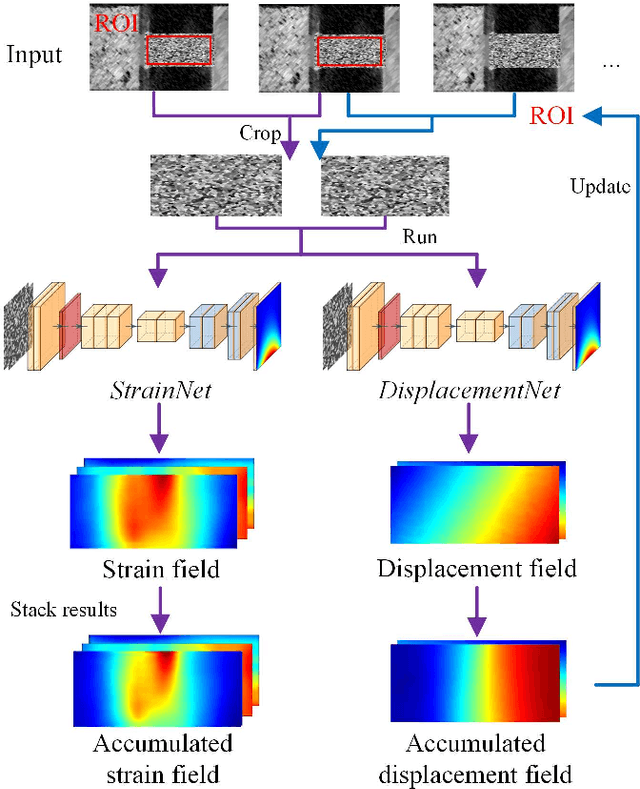
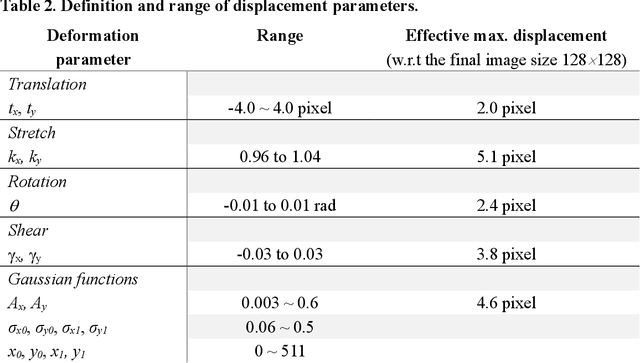
Digital image correlation (DIC) has become an industry standard to retrieve accurate displacement and strain measurement in tensile testing and other material characterization. Though traditional DIC offers a high precision estimation of deformation for general tensile testing cases, the prediction becomes unstable at large deformation or when the speckle patterns start to tear. In addition, traditional DIC requires a long computation time and often produces a low spatial resolution output affected by filtering and speckle pattern quality. To address these challenges, we propose a new deep learning-based DIC approach -- Deep DIC, in which two convolutional neural networks, DisplacementNet and StrainNet, are designed to work together for end-to-end prediction of displacements and strains. DisplacementNet predicts the displacement field and adaptively tracks the change of a region of interest. StrainNet predicts the strain field directly from the image input without relying on the displacement prediction, which significantly improves the strain prediction accuracy. A new dataset generation method is proposed to synthesize a realistic and comprehensive dataset including artificial speckle patterns, randomly generated displacement and strain fields, and deformed images based on the given deformation. Proposed Deep DIC is trained purely on a synthetic dataset, but designed to perform both on simulated and experimental data. Its performance is systematically evaluated and compared with commercial DIC software. Deep DIC gives highly consistent and comparable predictions of displacement and strain with those obtained from commercial DIC software, while it outperforms commercial software with very robust strain prediction even with large and localized deformation and varied pattern qualities.
Using GAN-based models to sentimental analysis on imbalanced datasets in education domain
Aug 26, 2021
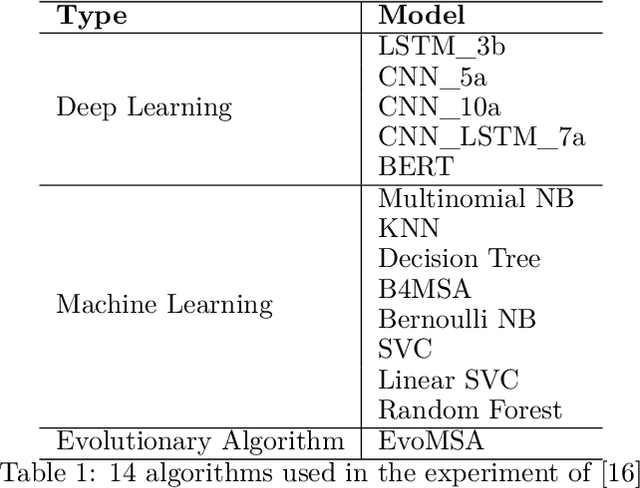
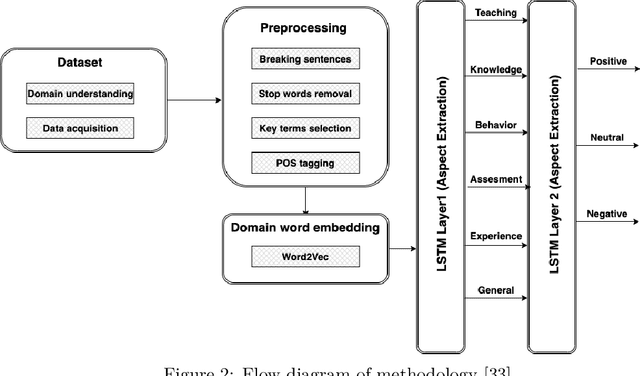
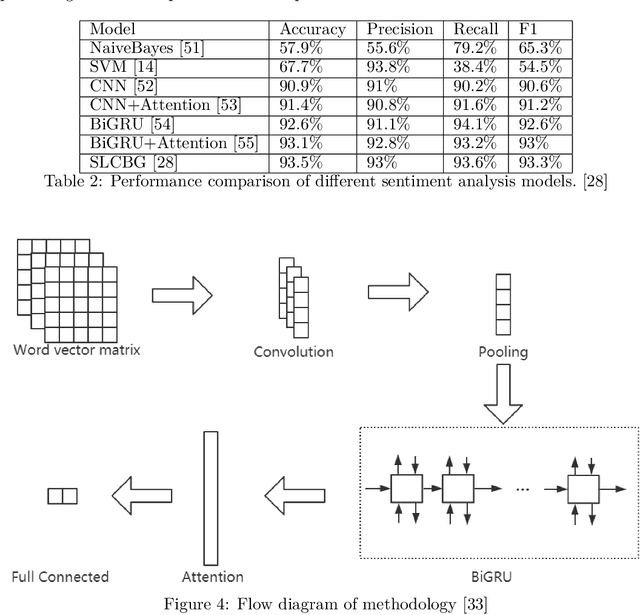
While the whole world is still struggling with the COVID-19 pandemic, online learning and home office become more common. Many schools transfer their courses teaching to the online classroom. Therefore, it is significant to mine the students' feedback and opinions from their reviews towards studies so that both schools and teachers can know where they need to improve. This paper trains machine learning and deep learning models using both balanced and imbalanced datasets for sentiment classification. Two SOTA category-aware text generation GAN models: CatGAN and SentiGAN, are utilized to synthesize text used to balance the highly imbalanced dataset. Results on three datasets with different imbalance degree from distinct domains show that when using generated text to balance the dataset, the F1-score of machine learning and deep learning model on sentiment classification increases 2.79% ~ 9.28%. Also, the results indicate that the average growth degree for CR100k is higher than CR23k, the average growth degree for deep learning is more increased than machine learning algorithms, and the average growth degree for more complex deep learning models is more increased than simpler deep learning models in experiments.