 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentiment analysis on electricity twitter posts
Jun 10, 2022
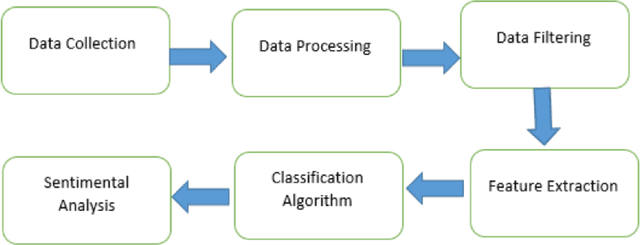
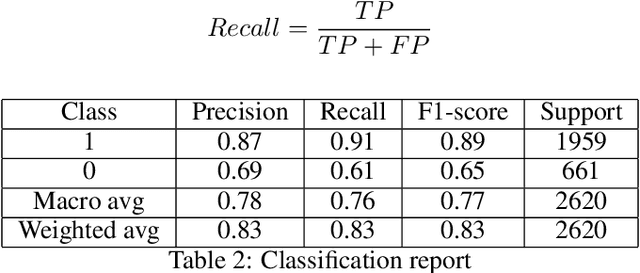
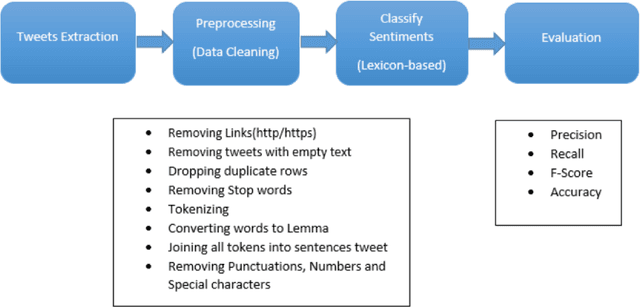
In today's world, everyone is expressive in some way, and the focus of this project is on people's opinions about rising electricity prices in United Kingdom and India using data from Twitter, a micro-blogging platform on which people post messages, known as tweets. Because many people's incomes are not good and they have to pay so many taxes and bills, maintaining a home has become a disputed issue these days. Despite the fact that Government offered subsidy schemes to compensate people electricity bills but it is not welcomed by people. In this project, the aim is to perform sentiment analysis on people's expressions and opinions expressed on Twitter. In order to grasp the electricity prices opinion, it is necessary to carry out sentiment analysis for the government and consumers in energy market. Furthermore, text present on these medias are unstructured in nature, so to process them we firstly need to pre-process the data. There are so many feature extraction techniques such as Bag of Words, TF-IDF (Term Frequency-Inverse Document Frequency), word embedding, NLP based features like word count. In this project, we analysed the impact of feature TF-IDF word level on electricity bills dataset of sentiment analysis. We found that by using TF-IDF word level performance of sentiment analysis is 3-4 higher than using N-gram features. Analysis is done using four classification algorithms including Naive Bayes, Decision Tree, Random Forest, and Logistic Regression and considering F-Score, Accuracy, Precision, and Recall performance parameters.