 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSingle Image Deraining
Single image deraining is the process of removing rain or rain streaks from a single image to improve its visibility.
Papers and Code
Edit2Restore:Few-Shot Image Restoration via Parameter-Efficient Adaptation of Pre-trained Editing Models
Jan 06, 2026Image restoration has traditionally required training specialized models on thousands of paired examples per degradation type. We challenge this paradigm by demonstrating that powerful pre-trained text-conditioned image editing models can be efficiently adapted for multiple restoration tasks through parameter-efficient fine-tuning with remarkably few examples. Our approach fine-tunes LoRA adapters on FLUX.1 Kontext, a state-of-the-art 12B parameter flow matching model for image-to-image translation, using only 16-128 paired images per task, guided by simple text prompts that specify the restoration operation. Unlike existing methods that train specialized restoration networks from scratch with thousands of samples, we leverage the rich visual priors already encoded in large-scale pre-trained editing models, dramatically reducing data requirements while maintaining high perceptual quality. A single unified LoRA adapter, conditioned on task-specific text prompts, effectively handles multiple degradations including denoising, deraining, and dehazing. Through comprehensive ablation studies, we analyze: (i) the impact of training set size on restoration quality, (ii) trade-offs between task-specific versus unified multi-task adapters, (iii) the role of text encoder fine-tuning, and (iv) zero-shot baseline performance. While our method prioritizes perceptual quality over pixel-perfect reconstruction metrics like PSNR/SSIM, our results demonstrate that pre-trained image editing models, when properly adapted, offer a compelling and data-efficient alternative to traditional image restoration approaches, opening new avenues for few-shot, prompt-guided image enhancement. The code to reproduce our results are available at: https://github.com/makinyilmaz/Edit2Restore
Learning Dual-Domain Multi-Scale Representations for Single Image Deraining
Mar 15, 2025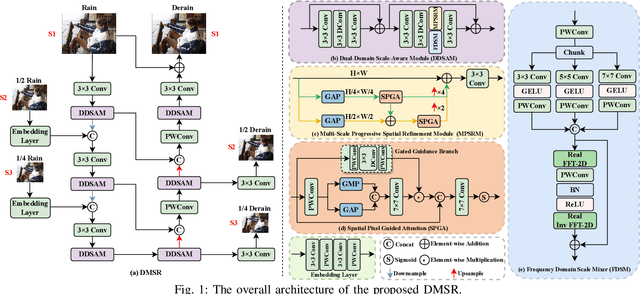
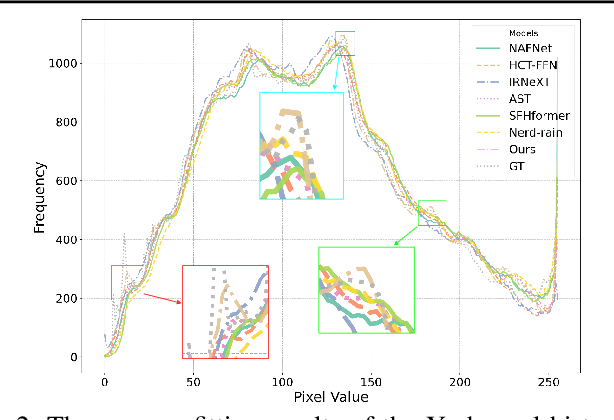

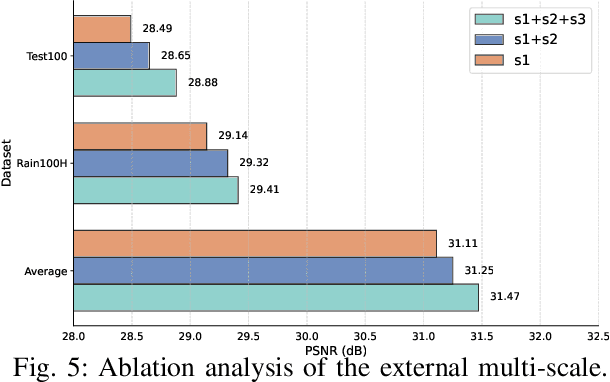
Existing image deraining methods typically rely on single-input, single-output, and single-scale architectures, which overlook the joint multi-scale information between external and internal features. Furthermore, single-domain representations are often too restrictive, limiting their ability to handle the complexities of real-world rain scenarios. To address these challenges, we propose a novel Dual-Domain Multi-Scale Representation Network (DMSR). The key idea is to exploit joint multi-scale representations from both external and internal domains in parallel while leveraging the strengths of both spatial and frequency domains to capture more comprehensive properties. Specifically, our method consists of two main components: the Multi-Scale Progressive Spatial Refinement Module (MPSRM) and the Frequency Domain Scale Mixer (FDSM). The MPSRM enables the interaction and coupling of multi-scale expert information within the internal domain using a hierarchical modulation and fusion strategy. The FDSM extracts multi-scale local information in the spatial domain, while also modeling global dependencies in the frequency domain. Extensive experiments show that our model achieves state-of-the-art performance across six benchmark datasets.
Iterative Optimal Attention and Local Model for Single Image Rain Streak Removal
Mar 20, 2025High-fidelity imaging is crucial for the successful safety supervision and intelligent deployment of vision-based measurement systems (VBMS). It ensures high-quality imaging in VBMS, which is fundamental for reliable visual measurement and analysis. However, imaging quality can be significantly impaired by adverse weather conditions, particularly rain, leading to blurred images and reduced contrast. Such impairments increase the risk of inaccurate evaluations and misinterpretations in VBMS. To address these limitations, we propose an Expectation Maximization Reconstruction Transformer (EMResformer) for single image rain streak removal. The EMResformer retains the key self-attention values for feature aggregation, enhancing local features to produce superior image reconstruction. Specifically, we propose an Expectation Maximization Block seamlessly integrated into the single image rain streak removal network, enhancing its ability to eliminate superfluous information and restore a cleaner background image. Additionally, to further enhance local information for improved detail rendition, we introduce a Local Model Residual Block, which integrates two local model blocks along with a sequence of convolutions and activation functions. This integration synergistically facilitates the extraction of more pertinent features for enhanced single image rain streak removal. Extensive experiments validate that our proposed EMResformer surpasses current state-of-the-art single image rain streak removal methods on both synthetic and real-world datasets, achieving an improved balance between model complexity and single image deraining performance. Furthermore, we evaluate the effectiveness of our method in VBMS scenarios, demonstrating that high-quality imaging significantly improves the accuracy and reliability of VBMS tasks.
Cross Paradigm Representation and Alignment Transformer for Image Deraining
Apr 23, 2025
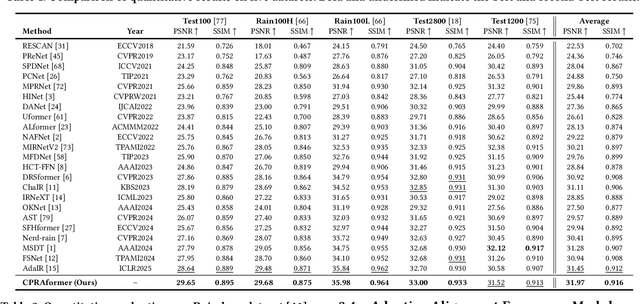
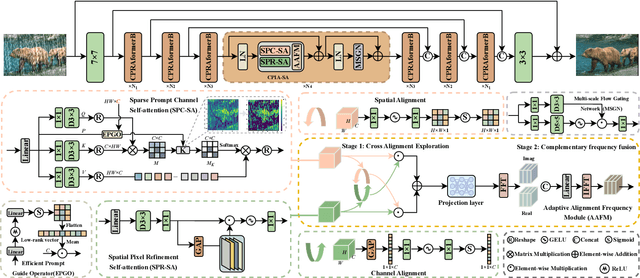
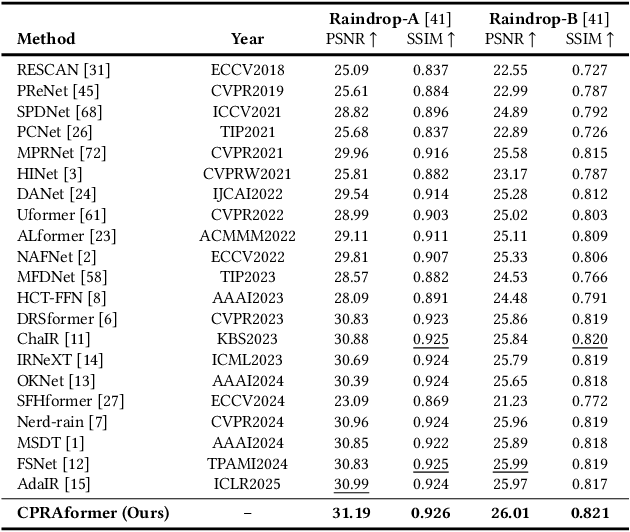
Transformer-based networks have achieved strong performance in low-level vision tasks like image deraining by utilizing spatial or channel-wise self-attention. However, irregular rain patterns and complex geometric overlaps challenge single-paradigm architectures, necessitating a unified framework to integrate complementary global-local and spatial-channel representations. To address this, we propose a novel Cross Paradigm Representation and Alignment Transformer (CPRAformer). Its core idea is the hierarchical representation and alignment, leveraging the strengths of both paradigms (spatial-channel and global-local) to aid image reconstruction. It bridges the gap within and between paradigms, aligning and coordinating them to enable deep interaction and fusion of features. Specifically, we use two types of self-attention in the Transformer blocks: sparse prompt channel self-attention (SPC-SA) and spatial pixel refinement self-attention (SPR-SA). SPC-SA enhances global channel dependencies through dynamic sparsity, while SPR-SA focuses on spatial rain distribution and fine-grained texture recovery. To address the feature misalignment and knowledge differences between them, we introduce the Adaptive Alignment Frequency Module (AAFM), which aligns and interacts with features in a two-stage progressive manner, enabling adaptive guidance and complementarity. This reduces the information gap within and between paradigms. Through this unified cross-paradigm dynamic interaction framework, we achieve the extraction of the most valuable interactive fusion information from the two paradigms. Extensive experiments demonstrate that our model achieves state-of-the-art performance on eight benchmark datasets and further validates CPRAformer's robustness in other image restoration tasks and downstream applications.
Leveraging Scene Geometry and Depth Information for Robust Image Deraining
Dec 27, 2024Image deraining holds great potential for enhancing the vision of autonomous vehicles in rainy conditions, contributing to safer driving. Previous works have primarily focused on employing a single network architecture to generate derained images. However, they often fail to fully exploit the rich prior knowledge embedded in the scenes. Particularly, most methods overlook the depth information that can provide valuable context about scene geometry and guide more robust deraining. In this work, we introduce a novel learning framework that integrates multiple networks: an AutoEncoder for deraining, an auxiliary network to incorporate depth information, and two supervision networks to enforce feature consistency between rainy and clear scenes. This multi-network design enables our model to effectively capture the underlying scene structure, producing clearer and more accurately derained images, leading to improved object detection for autonomous vehicles. Extensive experiments on three widely-used datasets demonstrated the effectiveness of our proposed method.
A Hybrid Transformer-Mamba Network for Single Image Deraining
Aug 31, 2024



Existing deraining Transformers employ self-attention mechanisms with fixed-range windows or along channel dimensions, limiting the exploitation of non-local receptive fields. In response to this issue, we introduce a novel dual-branch hybrid Transformer-Mamba network, denoted as TransMamba, aimed at effectively capturing long-range rain-related dependencies. Based on the prior of distinct spectral-domain features of rain degradation and background, we design a spectral-banded Transformer blocks on the first branch. Self-attention is executed within the combination of the spectral-domain channel dimension to improve the ability of modeling long-range dependencies. To enhance frequency-specific information, we present a spectral enhanced feed-forward module that aggregates features in the spectral domain. In the second branch, Mamba layers are equipped with cascaded bidirectional state space model modules to additionally capture the modeling of both local and global information. At each stage of both the encoder and decoder, we perform channel-wise concatenation of dual-branch features and achieve feature fusion through channel reduction, enabling more effective integration of the multi-scale information from the Transformer and Mamba branches. To better reconstruct innate signal-level relations within clean images, we also develop a spectral coherence loss. Extensive experiments on diverse datasets and real-world images demonstrate the superiority of our method compared against the state-of-the-art approaches.
High-resolution Rainy Image Synthesis: Learning from Rendering
Feb 23, 2025



Currently, there are few effective methods for synthesizing a mass of high-resolution rainy images in complex illumination conditions. However, these methods are essential for synthesizing large-scale high-quality paired rainy-clean image datasets, which can train deep learning-based single image rain removal models capable of generalizing to various illumination conditions. Therefore, we propose a practical two-stage learning-from-rendering pipeline for high-resolution rainy image synthesis. The pipeline combines the benefits of the realism of rendering-based methods and the high-efficiency of learning-based methods, providing the possibility of creating large-scale high-quality paired rainy-clean image datasets. In the rendering stage, we use a rendering-based method to create a High-resolution Rainy Image (HRI) dataset, which contains realistic high-resolution paired rainy-clean images of multiple scenes and various illumination conditions. In the learning stage, to learn illumination information from background images for high-resolution rainy image generation, we propose a High-resolution Rainy Image Generation Network (HRIGNet). HRIGNet is designed to introduce a guiding diffusion model in the Latent Diffusion Model, which provides additional guidance information for high-resolution image synthesis. In our experiments, HRIGNet is able to synthesize high-resolution rainy images up to 2048x1024 resolution. Rain removal experiments on real dataset validate that our method can help improve the robustness of deep derainers to real rainy images. To make our work reproducible, source codes and the dataset have been released at https://kb824999404.github.io/HRIG/.
Adaptive Frequency Enhancement Network for Single Image Deraining
Jul 19, 2024Image deraining aims to improve the visibility of images damaged by rainy conditions, targeting the removal of degradation elements such as rain streaks, raindrops, and rain accumulation. While numerous single image deraining methods have shown promising results in image enhancement within the spatial domain, real-world rain degradation often causes uneven damage across an image's entire frequency spectrum, posing challenges for these methods in enhancing different frequency components. In this paper, we introduce a novel end-to-end Adaptive Frequency Enhancement Network (AFENet) specifically for single image deraining that adaptively enhances images across various frequencies. We employ convolutions of different scales to adaptively decompose image frequency bands, introduce a feature enhancement module to boost the features of different frequency components and present a novel interaction module for interchanging and merging information from various frequency branches. Simultaneously, we propose a feature aggregation module that efficiently and adaptively fuses features from different frequency bands, facilitating enhancements across the entire frequency spectrum. This approach empowers the deraining network to eliminate diverse and complex rainy patterns and to reconstruct image details accurately. Extensive experiments on both real and synthetic scenes demonstrate that our method not only achieves visually appealing enhancement results but also surpasses existing methods in performance.
Cycle Contrastive Adversarial Learning for Unsupervised image Deraining
Jul 16, 2024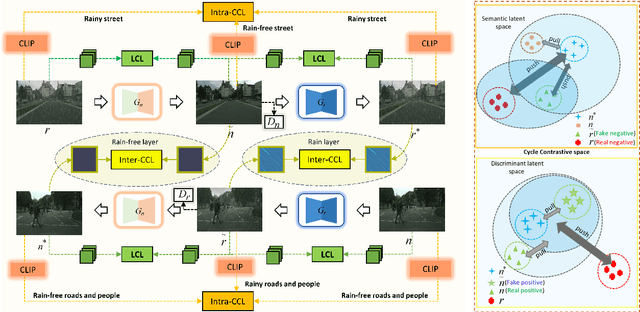


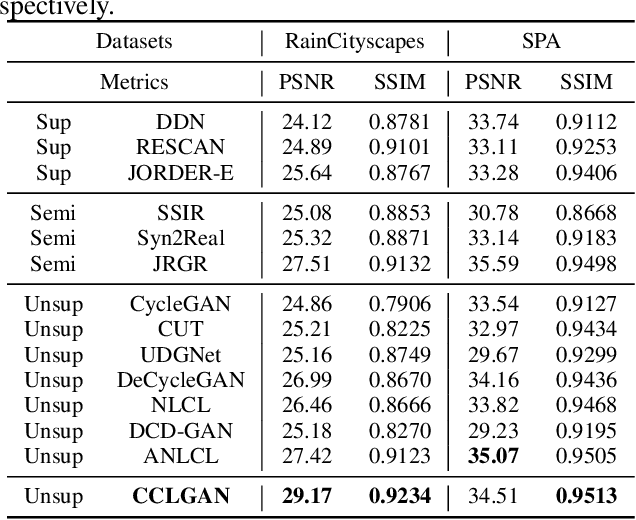
To tackle the difficulties in fitting paired real-world data for single image deraining (SID), recent unsupervised methods have achieved notable success. However, these methods often struggle to generate high-quality, rain-free images due to a lack of attention to semantic representation and image content, resulting in ineffective separation of content from the rain layer. In this paper, we propose a novel cycle contrastive generative adversarial network for unsupervised SID, called CCLGAN. This framework combines cycle contrastive learning (CCL) and location contrastive learning (LCL). CCL improves image reconstruction and rain-layer removal by bringing similar features closer and pushing dissimilar features apart in both semantic and discriminative spaces. At the same time, LCL preserves content information by constraining mutual information at the same location across different exemplars. CCLGAN shows superior performance, as extensive experiments demonstrate the benefits of CCLGAN and the effectiveness of its components.
End-to-end Inception-Unet based Generative Adversarial Networks for Snow and Rain Removals
Nov 07, 2024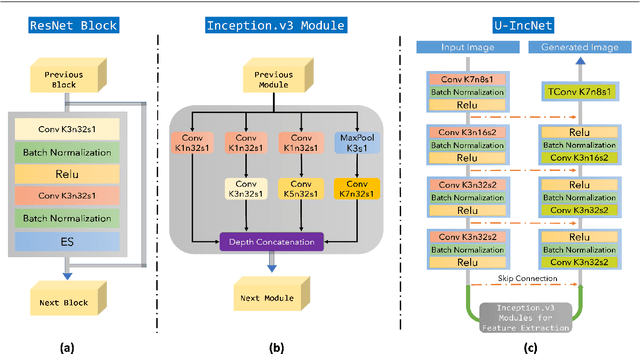

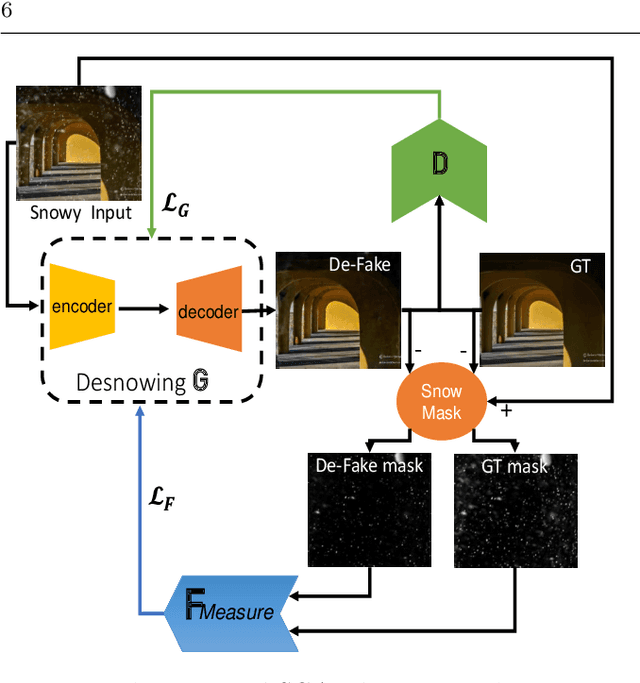

The superior performance introduced by deep learning approaches in removing atmospheric particles such as snow and rain from a single image; favors their usage over classical ones. However, deep learning-based approaches still suffer from challenges related to the particle appearance characteristics such as size, type, and transparency. Furthermore, due to the unique characteristics of rain and snow particles, single network based deep learning approaches struggle in handling both degradation scenarios simultaneously. In this paper, a global framework that consists of two Generative Adversarial Networks (GANs) is proposed where each handles the removal of each particle individually. The architectures of both desnowing and deraining GANs introduce the integration of a feature extraction phase with the classical U-net generator network which in turn enhances the removal performance in the presence of severe variations in size and appearance. Furthermore, a realistic dataset that contains pairs of snowy images next to their groundtruth images estimated using a low-rank approximation approach; is presented. The experiments show that the proposed desnowing and deraining approaches achieve significant improvements in comparison to the state-of-the-art approaches when tested on both synthetic and realistic datasets.