 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Paradigm Evaluation of Gaze-Based Semantic Object Identification for Intelligent Vehicles
Feb 01, 2026Understanding where drivers direct their visual attention during driving, as characterized by gaze behavior, is critical for developing next-generation advanced driver-assistance systems and improving road safety. This paper tackles this challenge as a semantic identification task from the road scenes captured by a vehicle's front-view camera. Specifically, the collocation of gaze points with object semantics is investigated using three distinct vision-based approaches: direct object detection (YOLOv13), segmentation-assisted classification (SAM2 paired with EfficientNetV2 versus YOLOv13), and query-based Vision-Language Models, VLMs (Qwen2.5-VL-7b versus Qwen2.5-VL-32b). The results demonstrate that the direct object detection (YOLOv13) and Qwen2.5-VL-32b significantly outperform other approaches, achieving Macro F1-Scores over 0.84. The large VLM (Qwen2.5-VL-32b), in particular, exhibited superior robustness and performance for identifying small, safety-critical objects such as traffic lights, especially in adverse nighttime conditions. Conversely, the segmentation-assisted paradigm suffers from a "part-versus-whole" semantic gap that led to large failure in recall. The results reveal a fundamental trade-off between the real-time efficiency of traditional detectors and the richer contextual understanding and robustness offered by large VLMs. These findings provide critical insights and practical guidance for the design of future human-aware intelligent driver monitoring systems.
Multi-view Phase-aware Pedestrian-Vehicle Incident Reasoning Framework with Vision-Language Models
Nov 18, 2025Pedestrian-vehicle incidents remain a critical urban safety challenge, with pedestrians accounting for over 20% of global traffic fatalities. Although existing video-based systems can detect when incidents occur, they provide little insight into how these events unfold across the distinct cognitive phases of pedestrian behavior. Recent vision-language models (VLMs) have shown strong potential for video understanding, but they remain limited in that they typically process videos in isolation, without explicit temporal structuring or multi-view integration. This paper introduces Multi-view Phase-aware Pedestrian-Vehicle Incident Reasoning (MP-PVIR), a unified framework that systematically processes multi-view video streams into structured diagnostic reports through four stages: (1) event-triggered multi-view video acquisition, (2) pedestrian behavior phase segmentation, (3) phase-specific multi-view reasoning, and (4) hierarchical synthesis and diagnostic reasoning. The framework operationalizes behavioral theory by automatically segmenting incidents into cognitive phases, performing synchronized multi-view analysis within each phase, and synthesizing results into causal chains with targeted prevention strategies. Particularly, two specialized VLMs underpin the MP-PVIR pipeline: TG-VLM for behavioral phase segmentation (mIoU = 0.4881) and PhaVR-VLM for phase-aware multi-view analysis, achieving a captioning score of 33.063 and up to 64.70% accuracy on question answering. Finally, a designated large language model is used to generate comprehensive reports detailing scene understanding, behavior interpretation, causal reasoning, and prevention recommendations. Evaluation on the Woven Traffic Safety dataset shows that MP-PVIR effectively translates multi-view video data into actionable insights, advancing AI-driven traffic safety analytics for vehicle-infrastructure cooperative systems.
Multi-Agent Visual-Language Reasoning for Comprehensive Highway Scene Understanding
Aug 24, 2025This paper introduces a multi-agent framework for comprehensive highway scene understanding, designed around a mixture-of-experts strategy. In this framework, a large generic vision-language model (VLM), such as GPT-4o, is contextualized with domain knowledge to generates task-specific chain-of-thought (CoT) prompts. These fine-grained prompts are then used to guide a smaller, efficient VLM (e.g., Qwen2.5-VL-7B) in reasoning over short videos, along with complementary modalities as applicable. The framework simultaneously addresses multiple critical perception tasks, including weather classification, pavement wetness assessment, and traffic congestion detection, achieving robust multi-task reasoning while balancing accuracy and computational efficiency. To support empirical validation, we curated three specialized datasets aligned with these tasks. Notably, the pavement wetness dataset is multimodal, combining video streams with road weather sensor data, highlighting the benefits of multimodal reasoning. Experimental results demonstrate consistently strong performance across diverse traffic and environmental conditions. From a deployment perspective, the framework can be readily integrated with existing traffic camera systems and strategically applied to high-risk rural locations, such as sharp curves, flood-prone lowlands, or icy bridges. By continuously monitoring the targeted sites, the system enhances situational awareness and delivers timely alerts, even in resource-constrained environments.
CrashSage: A Large Language Model-Centered Framework for Contextual and Interpretable Traffic Crash Analysis
May 08, 2025Road crashes claim over 1.3 million lives annually worldwide and incur global economic losses exceeding \$1.8 trillion. Such profound societal and financial impacts underscore the urgent need for road safety research that uncovers crash mechanisms and delivers actionable insights. Conventional statistical models and tree ensemble approaches typically rely on structured crash data, overlooking contextual nuances and struggling to capture complex relationships and underlying semantics. Moreover, these approaches tend to incur significant information loss, particularly in narrative elements related to multi-vehicle interactions, crash progression, and rare event characteristics. This study presents CrashSage, a novel Large Language Model (LLM)-centered framework designed to advance crash analysis and modeling through four key innovations. First, we introduce a tabular-to-text transformation strategy paired with relational data integration schema, enabling the conversion of raw, heterogeneous crash data into enriched, structured textual narratives that retain essential structural and relational context. Second, we apply context-aware data augmentation using a base LLM model to improve narrative coherence while preserving factual integrity. Third, we fine-tune the LLaMA3-8B model for crash severity inference, demonstrating superior performance over baseline approaches, including zero-shot, zero-shot with chain-of-thought prompting, and few-shot learning, with multiple models (GPT-4o, GPT-4o-mini, LLaMA3-70B). Finally, we employ a gradient-based explainability technique to elucidate model decisions at both the individual crash level and across broader risk factor dimensions. This interpretability mechanism enhances transparency and enables targeted road safety interventions by providing deeper insights into the most influential factors.
Enhancing autonomous vehicle safety in rain: a data-centric approach for clear vision
Dec 29, 2024
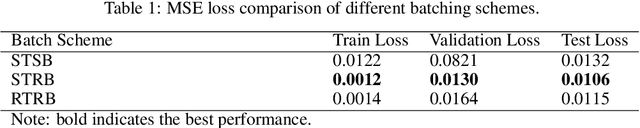


Autonomous vehicles face significant challenges in navigating adverse weather, particularly rain, due to the visual impairment of camera-based systems. In this study, we leveraged contemporary deep learning techniques to mitigate these challenges, aiming to develop a vision model that processes live vehicle camera feeds to eliminate rain-induced visual hindrances, yielding visuals closely resembling clear, rain-free scenes. Using the Car Learning to Act (CARLA) simulation environment, we generated a comprehensive dataset of clear and rainy images for model training and testing. In our model, we employed a classic encoder-decoder architecture with skip connections and concatenation operations. It was trained using novel batching schemes designed to effectively distinguish high-frequency rain patterns from low-frequency scene features across successive image frames. To evaluate the model performance, we integrated it with a steering module that processes front-view images as input. The results demonstrated notable improvements in steering accuracy, underscoring the model's potential to enhance navigation safety and reliability in rainy weather conditions.
Leveraging Scene Geometry and Depth Information for Robust Image Deraining
Dec 27, 2024Image deraining holds great potential for enhancing the vision of autonomous vehicles in rainy conditions, contributing to safer driving. Previous works have primarily focused on employing a single network architecture to generate derained images. However, they often fail to fully exploit the rich prior knowledge embedded in the scenes. Particularly, most methods overlook the depth information that can provide valuable context about scene geometry and guide more robust deraining. In this work, we introduce a novel learning framework that integrates multiple networks: an AutoEncoder for deraining, an auxiliary network to incorporate depth information, and two supervision networks to enforce feature consistency between rainy and clear scenes. This multi-network design enables our model to effectively capture the underlying scene structure, producing clearer and more accurately derained images, leading to improved object detection for autonomous vehicles. Extensive experiments on three widely-used datasets demonstrated the effectiveness of our proposed method.
Enhancing Nighttime Vehicle Detection with Day-to-Night Style Transfer and Labeling-Free Augmentation
Dec 21, 2024



Existing deep learning-based object detection models perform well under daytime conditions but face significant challenges at night, primarily because they are predominantly trained on daytime images. Additionally, training with nighttime images presents another challenge: even human annotators struggle to accurately label objects in low-light conditions. This issue is particularly pronounced in transportation applications, such as detecting vehicles and other objects of interest on rural roads at night, where street lighting is often absent, and headlights may introduce undesirable glare. This study addresses these challenges by introducing a novel framework for labeling-free data augmentation, leveraging CARLA-generated synthetic data for day-to-night image style transfer. Specifically, the framework incorporates the Efficient Attention Generative Adversarial Network for realistic day-to-night style transfer and uses CARLA-generated synthetic nighttime images to help the model learn vehicle headlight effects. To evaluate the efficacy of the proposed framework, we fine-tuned the YOLO11 model with an augmented dataset specifically curated for rural nighttime environments, achieving significant improvements in nighttime vehicle detection. This novel approach is simple yet effective, offering a scalable solution to enhance AI-based detection systems in low-visibility environments and extend the applicability of object detection models to broader real-world contexts.
Feature Group Tabular Transformer: A Novel Approach to Traffic Crash Modeling and Causality Analysis
Dec 06, 2024



Reliable and interpretable traffic crash modeling is essential for understanding causality and improving road safety. This study introduces a novel approach to predicting collision types by utilizing a comprehensive dataset fused from multiple sources, including weather data, crash reports, high-resolution traffic information, pavement geometry, and facility characteristics. Central to our approach is the development of a Feature Group Tabular Transformer (FGTT) model, which organizes disparate data into meaningful feature groups, represented as tokens. These group-based tokens serve as rich semantic components, enabling effective identification of collision patterns and interpretation of causal mechanisms. The FGTT model is benchmarked against widely used tree ensemble models, including Random Forest, XGBoost, and CatBoost, demonstrating superior predictive performance. Furthermore, model interpretation reveals key influential factors, providing fresh insights into the underlying causality of distinct crash types.
Leveraging Large Language Models with Chain-of-Thought and Prompt Engineering for Traffic Crash Severity Analysis and Inference
Aug 04, 2024Harnessing the power of Large Language Models (LLMs), this study explores the use of three state-of-the-art LLMs, specifically GPT-3.5-turbo, LLaMA3-8B, and LLaMA3-70B, for crash severity inference, framing it as a classification task. We generate textual narratives from original traffic crash tabular data using a pre-built template infused with domain knowledge. Additionally, we incorporated Chain-of-Thought (CoT) reasoning to guide the LLMs in analyzing the crash causes and then inferring the severity. This study also examine the impact of prompt engineering specifically designed for crash severity inference. The LLMs were tasked with crash severity inference to: (1) evaluate the models' capabilities in crash severity analysis, (2) assess the effectiveness of CoT and domain-informed prompt engineering, and (3) examine the reasoning abilities with the CoT framework. Our results showed that LLaMA3-70B consistently outperformed the other models, particularly in zero-shot settings. The CoT and Prompt Engineering techniques significantly enhanced performance, improving logical reasoning and addressing alignment issues. Notably, the CoT offers valuable insights into LLMs' reasoning processes, unleashing their capacity to consider diverse factors such as environmental conditions, driver behavior, and vehicle characteristics in severity analysis and inference.
Image-Based Vehicle Classification by Synergizing Features from Supervised and Self-Supervised Learning Paradigms
Feb 01, 2023
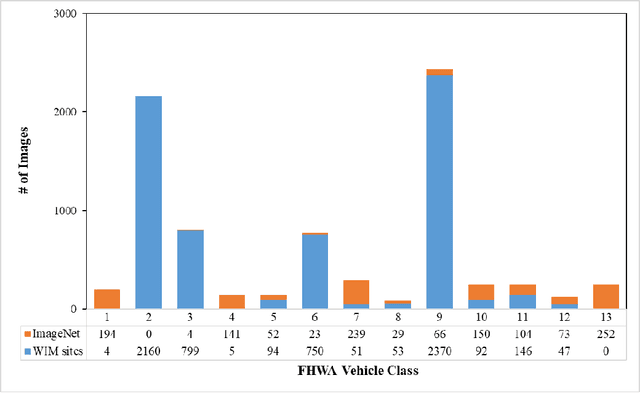


This paper introduces a novel approach to leverage features learned from both supervised and self-supervised paradigms, to improve image classification tasks, specifically for vehicle classification. Two state-of-the-art self-supervised learning methods, DINO and data2vec, were evaluated and compared for their representation learning of vehicle images. The former contrasts local and global views while the latter uses masked prediction on multi-layered representations. In the latter case, supervised learning is employed to finetune a pretrained YOLOR object detector for detecting vehicle wheels, from which definitive wheel positional features are retrieved. The representations learned from these self-supervised learning methods were combined with the wheel positional features for the vehicle classification task. Particularly, a random wheel masking strategy was utilized to finetune the previously learned representations in harmony with the wheel positional features during the training of the classifier. Our experiments show that the data2vec-distilled representations, which are consistent with our wheel masking strategy, outperformed the DINO counterpart, resulting in a celebrated Top-1 classification accuracy of 97.2% for classifying the 13 vehicle classes defined by the Federal Highway Administration.
* 15 pages, 7 figures, 7 tables