 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePp Ocr
Papers and Code
NusaAksara: A Multimodal and Multilingual Benchmark for Preserving Indonesian Indigenous Scripts
Feb 25, 2025



Indonesia is rich in languages and scripts. However, most NLP progress has been made using romanized text. In this paper, we present NusaAksara, a novel public benchmark for Indonesian languages that includes their original scripts. Our benchmark covers both text and image modalities and encompasses diverse tasks such as image segmentation, OCR, transliteration, translation, and language identification. Our data is constructed by human experts through rigorous steps. NusaAksara covers 8 scripts across 7 languages, including low-resource languages not commonly seen in NLP benchmarks. Although unsupported by Unicode, the Lampung script is included in this dataset. We benchmark our data across several models, from LLMs and VLMs such as GPT-4o, Llama 3.2, and Aya 23 to task-specific systems such as PP-OCR and LangID, and show that most NLP technologies cannot handle Indonesia's local scripts, with many achieving near-zero performance.
Arrow-Guided VLM: Enhancing Flowchart Understanding via Arrow Direction Encoding
May 09, 2025Flowcharts are indispensable tools in software design and business-process analysis, yet current vision-language models (VLMs) frequently misinterpret the directional arrows and graph topology that set these diagrams apart from natural images. We introduce a seven-stage pipeline grouped into three broader processes: (1) arrow-aware detection of nodes and arrow endpoints; (2) optical character recognition (OCR) to extract node text; and (3) construction of a structured prompt that guides the VLMs. Tested on a 90-question benchmark distilled from 30 annotated flowcharts, the method raises overall accuracy from 80 % to 89 % (+9 percentage points) without any task-specific fine-tuning. The gain is most pronounced for next-step queries (25/30 -> 30/30; 100 %, +17 pp); branch-result questions improve more modestly, and before-step questions remain difficult. A parallel evaluation with an LLM-as-a-Judge protocol shows the same trends, reinforcing the advantage of explicit arrow encoding. Limitations include dependence on detector and OCR precision, the small evaluation set, and residual errors at nodes with multiple incoming edges. Future work will enlarge the benchmark with synthetic and handwritten flowcharts and assess the approach on Business Process Model and Notation (BPMN) and Unified Modeling Language (UML).
PP-DocBee: Improving Multimodal Document Understanding Through a Bag of Tricks
Mar 06, 2025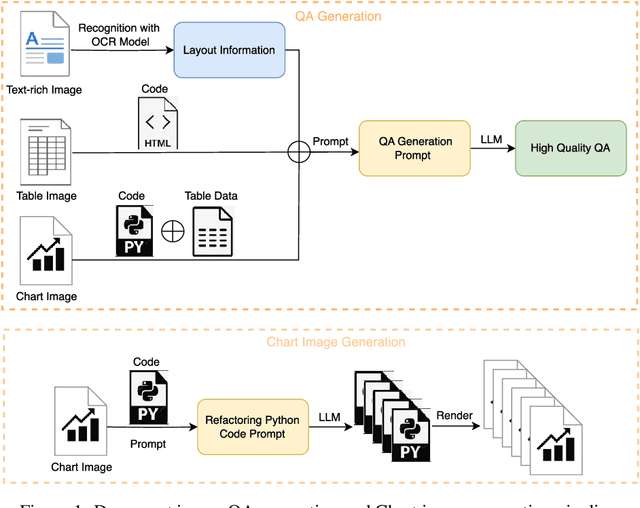

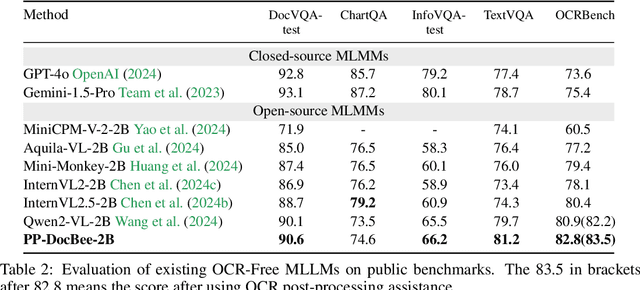
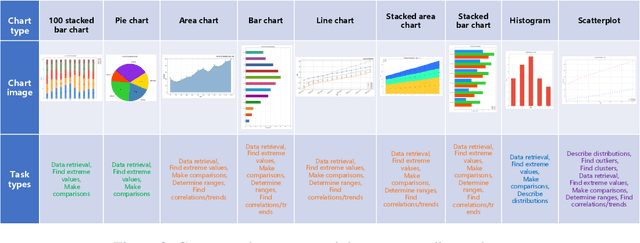
With the rapid advancement of digitalization, various document images are being applied more extensively in production and daily life, and there is an increasingly urgent need for fast and accurate parsing of the content in document images. Therefore, this report presents PP-DocBee, a novel multimodal large language model designed for end-to-end document image understanding. First, we develop a data synthesis strategy tailored to document scenarios in which we build a diverse dataset to improve the model generalization. Then, we apply a few training techniques, including dynamic proportional sampling, data preprocessing, and OCR postprocessing strategies. Extensive evaluations demonstrate the superior performance of PP-DocBee, achieving state-of-the-art results on English document understanding benchmarks and even outperforming existing open source and commercial models in Chinese document understanding. The source code and pre-trained models are publicly available at \href{https://github.com/PaddlePaddle/PaddleMIX}{https://github.com/PaddlePaddle/PaddleMIX}.
OSPC: Detecting Harmful Memes with Large Language Model as a Catalyst
Jun 14, 2024

Memes, which rapidly disseminate personal opinions and positions across the internet, also pose significant challenges in propagating social bias and prejudice. This study presents a novel approach to detecting harmful memes, particularly within the multicultural and multilingual context of Singapore. Our methodology integrates image captioning, Optical Character Recognition (OCR), and Large Language Model (LLM) analysis to comprehensively understand and classify harmful memes. Utilizing the BLIP model for image captioning, PP-OCR and TrOCR for text recognition across multiple languages, and the Qwen LLM for nuanced language understanding, our system is capable of identifying harmful content in memes created in English, Chinese, Malay, and Tamil. To enhance the system's performance, we fine-tuned our approach by leveraging additional data labeled using GPT-4V, aiming to distill the understanding capability of GPT-4V for harmful memes to our system. Our framework achieves top-1 at the public leaderboard of the Online Safety Prize Challenge hosted by AI Singapore, with the AUROC as 0.7749 and accuracy as 0.7087, significantly ahead of the other teams. Notably, our approach outperforms previous benchmarks, with FLAVA achieving an AUROC of 0.5695 and VisualBERT an AUROC of 0.5561.
TC-OCR: TableCraft OCR for Efficient Detection & Recognition of Table Structure & Content
Apr 19, 2024



The automatic recognition of tabular data in document images presents a significant challenge due to the diverse range of table styles and complex structures. Tables offer valuable content representation, enhancing the predictive capabilities of various systems such as search engines and Knowledge Graphs. Addressing the two main problems, namely table detection (TD) and table structure recognition (TSR), has traditionally been approached independently. In this research, we propose an end-to-end pipeline that integrates deep learning models, including DETR, CascadeTabNet, and PP OCR v2, to achieve comprehensive image-based table recognition. This integrated approach effectively handles diverse table styles, complex structures, and image distortions, resulting in improved accuracy and efficiency compared to existing methods like Table Transformers. Our system achieves simultaneous table detection (TD), table structure recognition (TSR), and table content recognition (TCR), preserving table structures and accurately extracting tabular data from document images. The integration of multiple models addresses the intricacies of table recognition, making our approach a promising solution for image-based table understanding, data extraction, and information retrieval applications. Our proposed approach achieves an IOU of 0.96 and an OCR Accuracy of 78%, showcasing a remarkable improvement of approximately 25% in the OCR Accuracy compared to the previous Table Transformer approach.
PdfTable: A Unified Toolkit for Deep Learning-Based Table Extraction
Sep 08, 2024



Currently, a substantial volume of document data exists in an unstructured format, encompassing Portable Document Format (PDF) files and images. Extracting information from these documents presents formidable challenges due to diverse table styles, complex forms, and the inclusion of different languages. Several open-source toolkits, such as Camelot, Plumb a PDF (pdfnumber), and Paddle Paddle Structure V2 (PP-StructureV2), have been developed to facilitate table extraction from PDFs or images. However, each toolkit has its limitations. Camelot and pdfnumber can solely extract tables from digital PDFs and cannot handle image-based PDFs and pictures. On the other hand, PP-StructureV2 can comprehensively extract image-based PDFs and tables from pictures. Nevertheless, it lacks the ability to differentiate between diverse application scenarios, such as wired tables and wireless tables, digital PDFs, and image-based PDFs. To address these issues, we have introduced the PDF table extraction (PdfTable) toolkit. This toolkit integrates numerous open-source models, including seven table recognition models, four Optical character recognition (OCR) recognition tools, and three layout analysis models. By refining the PDF table extraction process, PdfTable achieves adaptability across various application scenarios. We substantiate the efficacy of the PdfTable toolkit through verification on a self-labeled wired table dataset and the open-source wireless Publicly Table Reconition Dataset (PubTabNet). The PdfTable code will available on Github: https://github.com/CycloneBoy/pdf_table.
PP-OCRv3: More Attempts for the Improvement of Ultra Lightweight OCR System
Jun 07, 2022

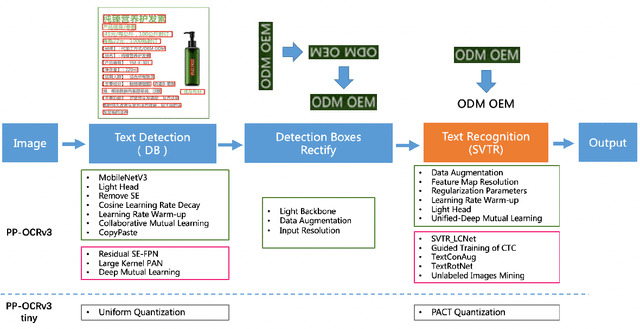
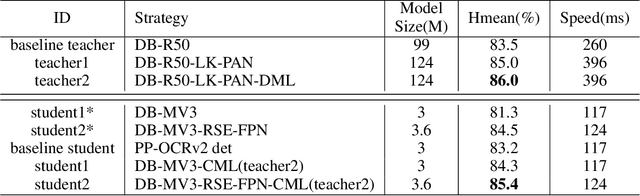
Optical character recognition (OCR) technology has been widely used in various scenes, as shown in Figure 1. Designing a practical OCR system is still a meaningful but challenging task. In previous work, considering the efficiency and accuracy, we proposed a practical ultra lightweight OCR system (PP-OCR), and an optimized version PP-OCRv2. In order to further improve the performance of PP-OCRv2, a more robust OCR system PP-OCRv3 is proposed in this paper. PP-OCRv3 upgrades the text detection model and text recognition model in 9 aspects based on PP-OCRv2. For text detector, we introduce a PAN module with large receptive field named LK-PAN, a FPN module with residual attention mechanism named RSE-FPN, and DML distillation strategy. For text recognizer, the base model is replaced from CRNN to SVTR, and we introduce lightweight text recognition network SVTR LCNet, guided training of CTC by attention, data augmentation strategy TextConAug, better pre-trained model by self-supervised TextRotNet, UDML, and UIM to accelerate the model and improve the effect. Experiments on real data show that the hmean of PP-OCRv3 is 5% higher than PP-OCRv2 under comparable inference speed. All the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
PP-OCRv2: Bag of Tricks for Ultra Lightweight OCR System
Sep 07, 2021

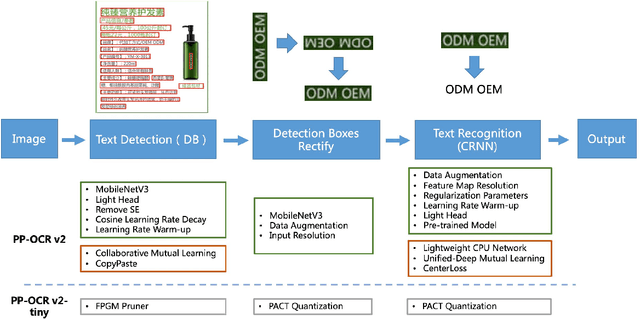
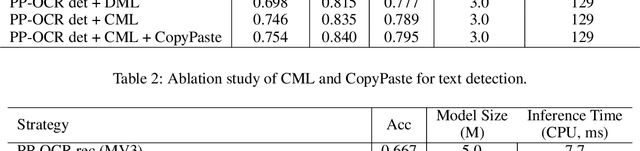
Optical Character Recognition (OCR) systems have been widely used in various of application scenarios. Designing an OCR system is still a challenging task. In previous work, we proposed a practical ultra lightweight OCR system (PP-OCR) to balance the accuracy against the efficiency. In order to improve the accuracy of PP-OCR and keep high efficiency, in this paper, we propose a more robust OCR system, i.e. PP-OCRv2. We introduce bag of tricks to train a better text detector and a better text recognizer, which include Collaborative Mutual Learning (CML), CopyPaste, Lightweight CPUNetwork (LCNet), Unified-Deep Mutual Learning (U-DML) and Enhanced CTCLoss. Experiments on real data show that the precision of PP-OCRv2 is 7% higher than PP-OCR under the same inference cost. It is also comparable to the server models of the PP-OCR which uses ResNet series as backbones. All of the above mentioned models are open-sourced and the code is available in the GitHub repository PaddleOCR which is powered by PaddlePaddle.
PP-OCR: A Practical Ultra Lightweight OCR System
Oct 15, 2020

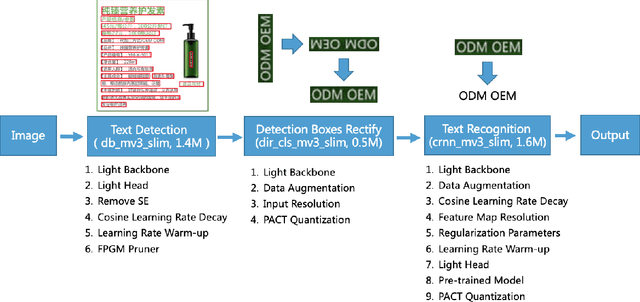
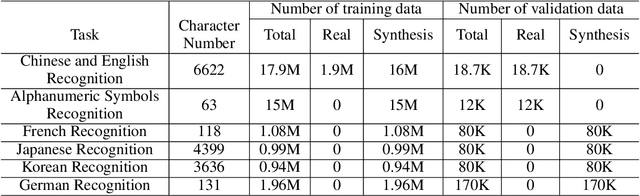
The Optical Character Recognition (OCR) systems have been widely used in various of application scenarios, such as office automation (OA) systems, factory automations, online educations, map productions etc. However, OCR is still a challenging task due to the various of text appearances and the demand of computational efficiency. In this paper, we propose a practical ultra lightweight OCR system, i.e., PP-OCR. The overall model size of the PP-OCR is only 3.5M for recognizing 6622 Chinese characters and 2.8M for recognizing 63 alphanumeric symbols, respectively. We introduce a bag of strategies to either enhance the model ability or reduce the model size. The corresponding ablation experiments with the real data are also provided. Meanwhile, several pre-trained models for the Chinese and English recognition are released, including a text detector (97K images are used), a direction classifier (600K images are used) as well as a text recognizer (17.9M images are used). Besides, the proposed PP-OCR are also verified in several other language recognition tasks, including French, Korean, Japanese and German. All of the above mentioned models are open-sourced and the codes are available in the GitHub repository, i.e., https://github.com/PaddlePaddle/PaddleOCR.