 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Registration
Papers and Code
Beyond the Vehicle: Cooperative Localization by Fusing Point Clouds for GPS-Challenged Urban Scenarios
Feb 03, 2026Accurate vehicle localization is a critical challenge in urban environments where GPS signals are often unreliable. This paper presents a cooperative multi-sensor and multi-modal localization approach to address this issue by fusing data from vehicle-to-vehicle (V2V) and vehicle-to-infrastructure (V2I) systems. Our approach integrates cooperative data with a point cloud registration-based simultaneous localization and mapping (SLAM) algorithm. The system processes point clouds generated from diverse sensor modalities, including vehicle-mounted LiDAR and stereo cameras, as well as sensors deployed at intersections. By leveraging shared data from infrastructure, our method significantly improves localization accuracy and robustness in complex, GPS-noisy urban scenarios.
Iterative Differential Entropy Minimization (IDEM) method for fine rigid pairwise 3D Point Cloud Registration: A Focus on the Metric
Jan 14, 2026Point cloud registration is a central theme in computer vision, with alignment algorithms continuously improving for greater robustness. Commonly used methods evaluate Euclidean distances between point clouds and minimize an objective function, such as Root Mean Square Error (RMSE). However, these approaches are most effective when the point clouds are well-prealigned and issues such as differences in density, noise, holes, and limited overlap can compromise the results. Traditional methods, such as Iterative Closest Point (ICP), require choosing one point cloud as fixed, since Euclidean distances lack commutativity. When only one point cloud has issues, adjustments can be made, but in real scenarios, both point clouds may be affected, often necessitating preprocessing. The authors introduce a novel differential entropy-based metric, designed to serve as the objective function within an optimization framework for fine rigid pairwise 3D point cloud registration, denoted as Iterative Differential Entropy Minimization (IDEM). This metric does not depend on the choice of a fixed point cloud and, during transformations, reveals a clear minimum corresponding to the best alignment. Multiple case studies are conducted, and the results are compared with those obtained using RMSE, Chamfer distance, and Hausdorff distance. The proposed metric proves effective even with density differences, noise, holes, and partial overlap, where RMSE does not always yield optimal alignment.
SyncTwin: Fast Digital Twin Construction and Synchronization for Safe Robotic Grasping
Jan 14, 2026Accurate and safe grasping under dynamic and visually occluded conditions remains a core challenge in real-world robotic manipulation. We present SyncTwin, a digital twin framework that unifies fast 3D scene reconstruction and real-to-sim synchronization for robust and safety-aware grasping in such environments. In the offline stage, we employ VGGT to rapidly reconstruct object-level 3D assets from RGB images, forming a reusable geometry library for simulation. During execution, SyncTwin continuously synchronizes the digital twin by tracking real-world object states via point cloud segmentation updates and aligning them through colored-ICP registration. The updated twin enables motion planners to compute collision-free and dynamically feasible trajectories in simulation, which are safely executed on the real robot through a closed real-to-sim-to-real loop. Experiments in dynamic and occluded scenes show that SyncTwin improves grasp accuracy and motion safety, demonstrating the effectiveness of digital-twin synchronization for real-world robotic execution.
Towards Zero-Shot Point Cloud Registration Across Diverse Scales, Scenes, and Sensor Setups
Jan 06, 2026Some deep learning-based point cloud registration methods struggle with zero-shot generalization, often requiring dataset-specific hyperparameter tuning or retraining for new environments. We identify three critical limitations: (a) fixed user-defined parameters (e.g., voxel size, search radius) that fail to generalize across varying scales, (b) learned keypoint detectors exhibit poor cross-domain transferability, and (c) absolute coordinates amplify scale mismatches between datasets. To address these three issues, we present BUFFER-X, a training-free registration framework that achieves zero-shot generalization through: (a) geometric bootstrapping for automatic hyperparameter estimation, (b) distribution-aware farthest point sampling to replace learned detectors, and (c) patch-level coordinate normalization to ensure scale consistency. Our approach employs hierarchical multi-scale matching to extract correspondences across local, middle, and global receptive fields, enabling robust registration in diverse environments. For efficiency-critical applications, we introduce BUFFER-X-Lite, which reduces total computation time by 43% (relative to BUFFER-X) through early exit strategies and fast pose solvers while preserving accuracy. We evaluate on a comprehensive benchmark comprising 12 datasets spanning object-scale, indoor, and outdoor scenes, including cross-sensor registration between heterogeneous LiDAR configurations. Results demonstrate that our approach generalizes effectively without manual tuning or prior knowledge of test domains. Code: https://github.com/MIT-SPARK/BUFFER-X.
MCI-Net: A Robust Multi-Domain Context Integration Network for Point Cloud Registration
Dec 29, 2025Robust and discriminative feature learning is critical for high-quality point cloud registration. However, existing deep learning-based methods typically rely on Euclidean neighborhood-based strategies for feature extraction, which struggle to effectively capture the implicit semantics and structural consistency in point clouds. To address these issues, we propose a multi-domain context integration network (MCI-Net) that improves feature representation and registration performance by aggregating contextual cues from diverse domains. Specifically, we propose a graph neighborhood aggregation module, which constructs a global graph to capture the overall structural relationships within point clouds. We then propose a progressive context interaction module to enhance feature discriminability by performing intra-domain feature decoupling and inter-domain context interaction. Finally, we design a dynamic inlier selection method that optimizes inlier weights using residual information from multiple iterations of pose estimation, thereby improving the accuracy and robustness of registration. Extensive experiments on indoor RGB-D and outdoor LiDAR datasets show that the proposed MCI-Net significantly outperforms existing state-of-the-art methods, achieving the highest registration recall of 96.4\% on 3DMatch. Source code is available at http://www.linshuyuan.com.
Motion Compensation for Real Time Ultrasound Scanning in Robotically Assisted Prostate Biopsy Procedures
Jan 09, 2026Prostate cancer is one of the most common types of cancer in men. Its diagnosis by biopsy requires a high level of expertise and precision from the surgeon, so the results are highly operator-dependent. The aim of this work is to develop a robotic system for assisted ultrasound (US) examination of the prostate, a prebiopsy step that could reduce the dexterity requirements and enable faster, more accurate and more available prostate biopsy. We developed and validated a laboratory setup with a collaborative robotic arm that can autonomously scan a prostate phantom and attached the phantom to a medical robotic arm that mimics the patient's movements. The scanning robot keeps the relative position of the US probe and the prostate constant, ensuring a consistent and robust approach to reconstructing the prostate. To reconstruct the prostate, each slice is segmented to generate a series of prostate contours converted into a 3D point cloud used for biopsy planning. The average scan time of the prostate was 30 s, and the average 3D reconstruction of the prostate took 3 s. We performed four motion scenarios: the phantom was scanned in a stationary state (S), with horizontal motion (H), with vertical motion (V), and with a combination of the two (C). System validation is performed by registering the prostate point cloud reconstructions acquired during different motions (H, V, C) with those obtained in the stationary state. ICP registration with a threshold of 0.8 mm yields mean 83.2\% fitness and 0.35 mm RMSE for S-H registration, 84.1\% fitness and 0.37 mm RMSE for S-V registration and 79.4\% fitness and 0.37 mm RMSE for S-C registration. Due to the elastic and soft material properties of the prostate phantom, the maximum robot tracking error was 3 mm, which can be sufficient for prostate biopsy according to medical literature. The maximum delay in motion compensation was 0.5 s.
Subsecond 3D Mesh Generation for Robot Manipulation
Dec 30, 20253D meshes are a fundamental representation widely used in computer science and engineering. In robotics, they are particularly valuable because they capture objects in a form that aligns directly with how robots interact with the physical world, enabling core capabilities such as predicting stable grasps, detecting collisions, and simulating dynamics. Although automatic 3D mesh generation methods have shown promising progress in recent years, potentially offering a path toward real-time robot perception, two critical challenges remain. First, generating high-fidelity meshes is prohibitively slow for real-time use, often requiring tens of seconds per object. Second, mesh generation by itself is insufficient. In robotics, a mesh must be contextually grounded, i.e., correctly segmented from the scene and registered with the proper scale and pose. Additionally, unless these contextual grounding steps remain efficient, they simply introduce new bottlenecks. In this work, we introduce an end-to-end system that addresses these challenges, producing a high-quality, contextually grounded 3D mesh from a single RGB-D image in under one second. Our pipeline integrates open-vocabulary object segmentation, accelerated diffusion-based mesh generation, and robust point cloud registration, each optimized for both speed and accuracy. We demonstrate its effectiveness in a real-world manipulation task, showing that it enables meshes to be used as a practical, on-demand representation for robotics perception and planning.
Generative Point Cloud Registration
Dec 10, 2025In this paper, we propose a novel 3D registration paradigm, Generative Point Cloud Registration, which bridges advanced 2D generative models with 3D matching tasks to enhance registration performance. Our key idea is to generate cross-view consistent image pairs that are well-aligned with the source and target point clouds, enabling geometry-color feature fusion to facilitate robust matching. To ensure high-quality matching, the generated image pair should feature both 2D-3D geometric consistency and cross-view texture consistency. To achieve this, we introduce Match-ControlNet, a matching-specific, controllable 2D generative model. Specifically, it leverages the depth-conditioned generation capability of ControlNet to produce images that are geometrically aligned with depth maps derived from point clouds, ensuring 2D-3D geometric consistency. Additionally, by incorporating a coupled conditional denoising scheme and coupled prompt guidance, Match-ControlNet further promotes cross-view feature interaction, guiding texture consistency generation. Our generative 3D registration paradigm is general and could be seamlessly integrated into various registration methods to enhance their performance. Extensive experiments on 3DMatch and ScanNet datasets verify the effectiveness of our approach.
A Multi-Mode Structured Light 3D Imaging System with Multi-Source Information Fusion for Underwater Pipeline Detection
Dec 12, 2025

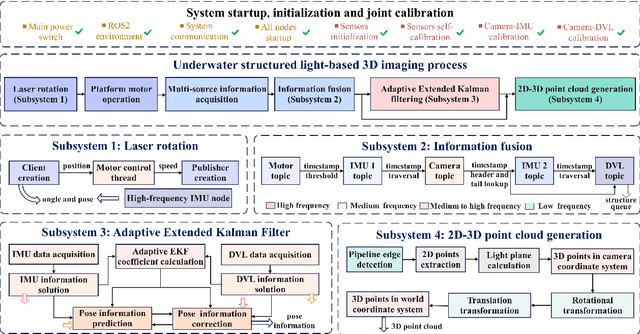

Underwater pipelines are highly susceptible to corrosion, which not only shorten their service life but also pose significant safety risks. Compared with manual inspection, the intelligent real-time imaging system for underwater pipeline detection has become a more reliable and practical solution. Among various underwater imaging techniques, structured light 3D imaging can restore the sufficient spatial detail for precise defect characterization. Therefore, this paper develops a multi-mode underwater structured light 3D imaging system for pipeline detection (UW-SLD system) based on multi-source information fusion. First, a rapid distortion correction (FDC) method is employed for efficient underwater image rectification. To overcome the challenges of extrinsic calibration among underwater sensors, a factor graph-based parameter optimization method is proposed to estimate the transformation matrix between the structured light and acoustic sensors. Furthermore, a multi-mode 3D imaging strategy is introduced to adapt to the geometric variability of underwater pipelines. Given the presence of numerous disturbances in underwater environments, a multi-source information fusion strategy and an adaptive extended Kalman filter (AEKF) are designed to ensure stable pose estimation and high-accuracy measurements. In particular, an edge detection-based ICP (ED-ICP) algorithm is proposed. This algorithm integrates pipeline edge detection network with enhanced point cloud registration to achieve robust and high-fidelity reconstruction of defect structures even under variable motion conditions. Extensive experiments are conducted under different operation modes, velocities, and depths. The results demonstrate that the developed system achieves superior accuracy, adaptability and robustness, providing a solid foundation for autonomous underwater pipeline detection.
FUSER: Feed-Forward MUltiview 3D Registration Transformer and SE(3)$^N$ Diffusion Refinement
Dec 10, 2025Registration of multiview point clouds conventionally relies on extensive pairwise matching to build a pose graph for global synchronization, which is computationally expensive and inherently ill-posed without holistic geometric constraints. This paper proposes FUSER, the first feed-forward multiview registration transformer that jointly processes all scans in a unified, compact latent space to directly predict global poses without any pairwise estimation. To maintain tractability, FUSER encodes each scan into low-resolution superpoint features via a sparse 3D CNN that preserves absolute translation cues, and performs efficient intra- and inter-scan reasoning through a Geometric Alternating Attention module. Particularly, we transfer 2D attention priors from off-the-shelf foundation models to enhance 3D feature interaction and geometric consistency. Building upon FUSER, we further introduce FUSER-DF, an SE(3)$^N$ diffusion refinement framework to correct FUSER's estimates via denoising in the joint SE(3)$^N$ space. FUSER acts as a surrogate multiview registration model to construct the denoiser, and a prior-conditioned SE(3)$^N$ variational lower bound is derived for denoising supervision. Extensive experiments on 3DMatch, ScanNet and ArkitScenes demonstrate that our approach achieves the superior registration accuracy and outstanding computational efficiency.