 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti Person Pose Estimation And Tracking
Multi-person pose estimation and tracking is the process of detecting and tracking the poses of multiple people in images or videos.
Papers and Code
JRDB-Pose3D: A Multi-person 3D Human Pose and Shape Estimation Dataset for Robotics
Feb 03, 2026Real-world scenes are inherently crowded. Hence, estimating 3D poses of all nearby humans, tracking their movements over time, and understanding their activities within social and environmental contexts are essential for many applications, such as autonomous driving, robot perception, robot navigation, and human-robot interaction. However, most existing 3D human pose estimation datasets primarily focus on single-person scenes or are collected in controlled laboratory environments, which restricts their relevance to real-world applications. To bridge this gap, we introduce JRDB-Pose3D, which captures multi-human indoor and outdoor environments from a mobile robotic platform. JRDB-Pose3D provides rich 3D human pose annotations for such complex and dynamic scenes, including SMPL-based pose annotations with consistent body-shape parameters and track IDs for each individual over time. JRDB-Pose3D contains, on average, 5-10 human poses per frame, with some scenes featuring up to 35 individuals simultaneously. The proposed dataset presents unique challenges, including frequent occlusions, truncated bodies, and out-of-frame body parts, which closely reflect real-world environments. Moreover, JRDB-Pose3D inherits all available annotations from the JRDB dataset, such as 2D pose, information about social grouping, activities, and interactions, full-scene semantic masks with consistent human- and object-level tracking, and detailed annotations for each individual, such as age, gender, and race, making it a holistic dataset for a wide range of downstream perception and human-centric understanding tasks.
Self-Supervised Uncalibrated Multi-View Video Anonymization in the Operating Room
Feb 02, 2026Privacy preservation is a prerequisite for using video data in Operating Room (OR) research. Effective anonymization relies on the exhaustive localization of every individual; even a single missed detection necessitates extensive manual correction. However, existing approaches face two critical scalability bottlenecks: (1) they usually require manual annotations of each new clinical site for high accuracy; (2) while multi-camera setups have been widely adopted to address single-view ambiguity, camera calibration is typically required whenever cameras are repositioned. To address these problems, we propose a novel self-supervised multi-view video anonymization framework consisting of whole-body person detection and whole-body pose estimation, without annotation or camera calibration. Our core strategy is to enhance the single-view detector by "retrieving" false negatives using temporal and multi-view context, and conducting self-supervised domain adaptation. We first run an off-the-shelf whole-body person detector in each view with a low-score threshold to gather candidate detections. Then, we retrieve the low-score false negatives that exhibit consistency with the high-score detections via tracking and self-supervised uncalibrated multi-view association. These recovered detections serve as pseudo labels to iteratively fine-tune the whole-body detector. Finally, we apply whole-body pose estimation on each detected person, and fine-tune the pose model using its own high-score predictions. Experiments on the 4D-OR dataset of simulated surgeries and our dataset of real surgeries show the effectiveness of our approach achieving over 97% recall. Moreover, we train a real-time whole-body detector using our pseudo labels, achieving comparable performance and highlighting our method's practical applicability. Code is available at https://github.com/CAMMA-public/OR_anonymization.
A Multi-View Pipeline and Benchmark Dataset for 3D Hand Pose Estimation in Surgery
Jan 22, 2026Purpose: Accurate 3D hand pose estimation supports surgical applications such as skill assessment, robot-assisted interventions, and geometry-aware workflow analysis. However, surgical environments pose severe challenges, including intense and localized lighting, frequent occlusions by instruments or staff, and uniform hand appearance due to gloves, combined with a scarcity of annotated datasets for reliable model training. Method: We propose a robust multi-view pipeline for 3D hand pose estimation in surgical contexts that requires no domain-specific fine-tuning and relies solely on off-the-shelf pretrained models. The pipeline integrates reliable person detection, whole-body pose estimation, and state-of-the-art 2D hand keypoint prediction on tracked hand crops, followed by a constrained 3D optimization. In addition, we introduce a novel surgical benchmark dataset comprising over 68,000 frames and 3,000 manually annotated 2D hand poses with triangulated 3D ground truth, recorded in a replica operating room under varying levels of scene complexity. Results: Quantitative experiments demonstrate that our method consistently outperforms baselines, achieving a 31% reduction in 2D mean joint error and a 76% reduction in 3D mean per-joint position error. Conclusion: Our work establishes a strong baseline for 3D hand pose estimation in surgery, providing both a training-free pipeline and a comprehensive annotated dataset to facilitate future research in surgical computer vision.
PressTrack-HMR: Pressure-Based Top-Down Multi-Person Global Human Mesh Recovery
Nov 13, 2025Multi-person global human mesh recovery (HMR) is crucial for understanding crowd dynamics and interactions. Traditional vision-based HMR methods sometimes face limitations in real-world scenarios due to mutual occlusions, insufficient lighting, and privacy concerns. Human-floor tactile interactions offer an occlusion-free and privacy-friendly alternative for capturing human motion. Existing research indicates that pressure signals acquired from tactile mats can effectively estimate human pose in single-person scenarios. However, when multiple individuals walk randomly on the mat simultaneously, how to distinguish intermingled pressure signals generated by different persons and subsequently acquire individual temporal pressure data remains a pending challenge for extending pressure-based HMR to the multi-person situation. In this paper, we present \textbf{PressTrack-HMR}, a top-down pipeline that recovers multi-person global human meshes solely from pressure signals. This pipeline leverages a tracking-by-detection strategy to first identify and segment each individual's pressure signal from the raw pressure data, and subsequently performs HMR for each extracted individual signal. Furthermore, we build a multi-person interaction pressure dataset \textbf{MIP}, which facilitates further research into pressure-based human motion analysis in multi-person scenarios. Experimental results demonstrate that our method excels in multi-person HMR using pressure data, with 89.2 $mm$ MPJPE and 112.6 $mm$ WA-MPJPE$_{100}$, and these showcase the potential of tactile mats for ubiquitous, privacy-preserving multi-person action recognition. Our dataset & code are available at https://github.com/Jiayue-Yuan/PressTrack-HMR.
Group Inertial Poser: Multi-Person Pose and Global Translation from Sparse Inertial Sensors and Ultra-Wideband Ranging
Oct 24, 2025Tracking human full-body motion using sparse wearable inertial measurement units (IMUs) overcomes the limitations of occlusion and instrumentation of the environment inherent in vision-based approaches. However, purely IMU-based tracking compromises translation estimates and accurate relative positioning between individuals, as inertial cues are inherently self-referential and provide no direct spatial reference for others. In this paper, we present a novel approach for robustly estimating body poses and global translation for multiple individuals by leveraging the distances between sparse wearable sensors - both on each individual and across multiple individuals. Our method Group Inertial Poser estimates these absolute distances between pairs of sensors from ultra-wideband ranging (UWB) and fuses them with inertial observations as input into structured state-space models to integrate temporal motion patterns for precise 3D pose estimation. Our novel two-step optimization further leverages the estimated distances for accurately tracking people's global trajectories through the world. We also introduce GIP-DB, the first IMU+UWB dataset for two-person tracking, which comprises 200 minutes of motion recordings from 14 participants. In our evaluation, Group Inertial Poser outperforms previous state-of-the-art methods in accuracy and robustness across synthetic and real-world data, showing the promise of IMU+UWB-based multi-human motion capture in the wild. Code, models, dataset: https://github.com/eth-siplab/GroupInertialPoser
Multi-person Physics-based Pose Estimation for Combat Sports
Apr 11, 2025We propose a novel framework for accurate 3D human pose estimation in combat sports using sparse multi-camera setups. Our method integrates robust multi-view 2D pose tracking via a transformer-based top-down approach, employing epipolar geometry constraints and long-term video object segmentation for consistent identity tracking across views. Initial 3D poses are obtained through weighted triangulation and spline smoothing, followed by kinematic optimization to refine pose accuracy. We further enhance pose realism and robustness by introducing a multi-person physics-based trajectory optimization step, effectively addressing challenges such as rapid motions, occlusions, and close interactions. Experimental results on diverse datasets, including a new benchmark of elite boxing footage, demonstrate state-of-the-art performance. Additionally, we release comprehensive annotated video datasets to advance future research in multi-person pose estimation for combat sports.
CoMotion: Concurrent Multi-person 3D Motion
Apr 16, 2025We introduce an approach for detecting and tracking detailed 3D poses of multiple people from a single monocular camera stream. Our system maintains temporally coherent predictions in crowded scenes filled with difficult poses and occlusions. Our model performs both strong per-frame detection and a learned pose update to track people from frame to frame. Rather than match detections across time, poses are updated directly from a new input image, which enables online tracking through occlusion. We train on numerous image and video datasets leveraging pseudo-labeled annotations to produce a model that matches state-of-the-art systems in 3D pose estimation accuracy while being faster and more accurate in tracking multiple people through time. Code and weights are provided at https://github.com/apple/ml-comotion
Progressive Inertial Poser: Progressive Real-Time Kinematic Chain Estimation for 3D Full-Body Pose from Three IMU Sensors
May 08, 2025The motion capture system that supports full-body virtual representation is of key significance for virtual reality. Compared to vision-based systems, full-body pose estimation from sparse tracking signals is not limited by environmental conditions or recording range. However, previous works either face the challenge of wearing additional sensors on the pelvis and lower-body or rely on external visual sensors to obtain global positions of key joints. To improve the practicality of the technology for virtual reality applications, we estimate full-body poses using only inertial data obtained from three Inertial Measurement Unit (IMU) sensors worn on the head and wrists, thereby reducing the complexity of the hardware system. In this work, we propose a method called Progressive Inertial Poser (ProgIP) for human pose estimation, which combines neural network estimation with a human dynamics model, considers the hierarchical structure of the kinematic chain, and employs a multi-stage progressive network estimation with increased depth to reconstruct full-body motion in real time. The encoder combines Transformer Encoder and bidirectional LSTM (TE-biLSTM) to flexibly capture the temporal dependencies of the inertial sequence, while the decoder based on multi-layer perceptrons (MLPs) transforms high-dimensional features and accurately projects them onto Skinned Multi-Person Linear (SMPL) model parameters. Quantitative and qualitative experimental results on multiple public datasets show that our method outperforms state-of-the-art methods with the same inputs, and is comparable to recent works using six IMU sensors.
SpecTrack: Learned Multi-Rotation Tracking via Speckle Imaging
Oct 08, 2024
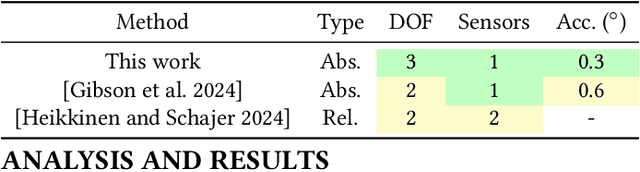
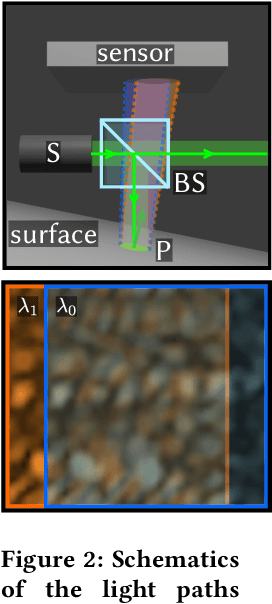
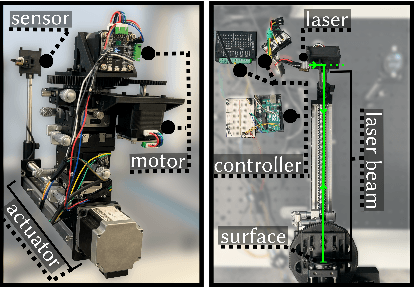
Precision pose detection is increasingly demanded in fields such as personal fabrication, Virtual Reality (VR), and robotics due to its critical role in ensuring accurate positioning information. However, conventional vision-based systems used in these systems often struggle with achieving high precision and accuracy, particularly when dealing with complex environments or fast-moving objects. To address these limitations, we investigate Laser Speckle Imaging (LSI), an emerging optical tracking method that offers promising potential for improving pose estimation accuracy. Specifically, our proposed LSI-Based Tracking (SpecTrack) leverages the captures from a lensless camera and a retro-reflector marker with a coded aperture to achieve multi-axis rotational pose estimation with high precision. Our extensive trials using our in-house built testbed have shown that SpecTrack achieves an accuracy of 0.31{\deg} (std=0.43{\deg}), significantly outperforming state-of-the-art approaches and improving accuracy up to 200%.
Skeleton-based Group Activity Recognition via Spatial-Temporal Panoramic Graph
Jul 28, 2024



Group Activity Recognition aims to understand collective activities from videos. Existing solutions primarily rely on the RGB modality, which encounters challenges such as background variations, occlusions, motion blurs, and significant computational overhead. Meanwhile, current keypoint-based methods offer a lightweight and informative representation of human motions but necessitate accurate individual annotations and specialized interaction reasoning modules. To address these limitations, we design a panoramic graph that incorporates multi-person skeletons and objects to encapsulate group activity, offering an effective alternative to RGB video. This panoramic graph enables Graph Convolutional Network (GCN) to unify intra-person, inter-person, and person-object interactive modeling through spatial-temporal graph convolutions. In practice, we develop a novel pipeline that extracts skeleton coordinates using pose estimation and tracking algorithms and employ Multi-person Panoramic GCN (MP-GCN) to predict group activities. Extensive experiments on Volleyball and NBA datasets demonstrate that the MP-GCN achieves state-of-the-art performance in both accuracy and efficiency. Notably, our method outperforms RGB-based approaches by using only estimated 2D keypoints as input. Code is available at https://github.com/mgiant/MP-GCN