 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHumaneva I
Papers and Code
3D Human Pose Estimation via Spatial Graph Order Attention and Temporal Body Aware Transformer
May 02, 2025Nowadays, Transformers and Graph Convolutional Networks (GCNs) are the prevailing techniques for 3D human pose estimation. However, Transformer-based methods either ignore the spatial neighborhood relationships between the joints when used for skeleton representations or disregard the local temporal patterns of the local joint movements in skeleton sequence modeling, while GCN-based methods often neglect the need for pose-specific representations. To address these problems, we propose a new method that exploits the graph modeling capability of GCN to represent each skeleton with multiple graphs of different orders, incorporated with a newly introduced Graph Order Attention module that dynamically emphasizes the most representative orders for each joint. The resulting spatial features of the sequence are further processed using a proposed temporal Body Aware Transformer that models the global body feature dependencies in the sequence with awareness of the local inter-skeleton feature dependencies of joints. Given that our 3D pose output aligns with the central 2D pose in the sequence, we improve the self-attention mechanism to be aware of the central pose while diminishing its focus gradually towards the first and the last poses. Extensive experiments on Human3.6m, MPIINF-3DHP, and HumanEva-I datasets demonstrate the effectiveness of the proposed method. Code and models are made available on Github.
GTA-Net: An IoT-Integrated 3D Human Pose Estimation System for Real-Time Adolescent Sports Posture Correction
Nov 11, 2024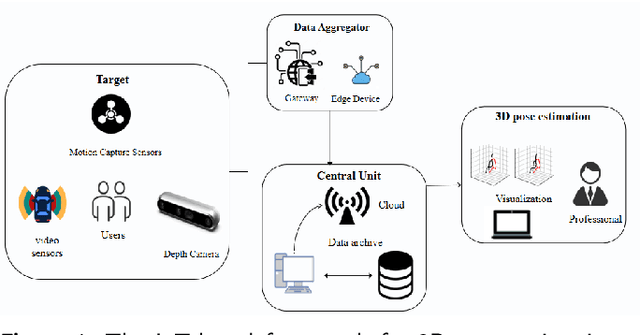
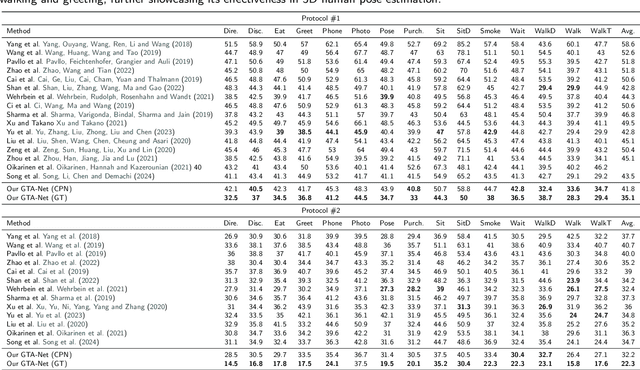


With the advancement of artificial intelligence, 3D human pose estimation-based systems for sports training and posture correction have gained significant attention in adolescent sports. However, existing methods face challenges in handling complex movements, providing real-time feedback, and accommodating diverse postures, particularly with occlusions, rapid movements, and the resource constraints of Internet of Things (IoT) devices, making it difficult to balance accuracy and real-time performance. To address these issues, we propose GTA-Net, an intelligent system for posture correction and real-time feedback in adolescent sports, integrated within an IoT-enabled environment. This model enhances pose estimation in dynamic scenes by incorporating Graph Convolutional Networks (GCN), Temporal Convolutional Networks (TCN), and Hierarchical Attention mechanisms, achieving real-time correction through IoT devices. Experimental results show GTA-Net's superior performance on Human3.6M, HumanEva-I, and MPI-INF-3DHP datasets, with Mean Per Joint Position Error (MPJPE) values of 32.2mm, 15.0mm, and 48.0mm, respectively, significantly outperforming existing methods. The model also demonstrates strong robustness in complex scenarios, maintaining high accuracy even with occlusions and rapid movements. This system enhances real-time posture correction and offers broad applications in intelligent sports and health management.
KTPFormer: Kinematics and Trajectory Prior Knowledge-Enhanced Transformer for 3D Human Pose Estimation
Apr 02, 2024This paper presents a novel Kinematics and Trajectory Prior Knowledge-Enhanced Transformer (KTPFormer), which overcomes the weakness in existing transformer-based methods for 3D human pose estimation that the derivation of Q, K, V vectors in their self-attention mechanisms are all based on simple linear mapping. We propose two prior attention modules, namely Kinematics Prior Attention (KPA) and Trajectory Prior Attention (TPA) to take advantage of the known anatomical structure of the human body and motion trajectory information, to facilitate effective learning of global dependencies and features in the multi-head self-attention. KPA models kinematic relationships in the human body by constructing a topology of kinematics, while TPA builds a trajectory topology to learn the information of joint motion trajectory across frames. Yielding Q, K, V vectors with prior knowledge, the two modules enable KTPFormer to model both spatial and temporal correlations simultaneously. Extensive experiments on three benchmarks (Human3.6M, MPI-INF-3DHP and HumanEva) show that KTPFormer achieves superior performance in comparison to state-of-the-art methods. More importantly, our KPA and TPA modules have lightweight plug-and-play designs and can be integrated into various transformer-based networks (i.e., diffusion-based) to improve the performance with only a very small increase in the computational overhead. The code is available at: https://github.com/JihuaPeng/KTPFormer.
Improving the Robustness of 3D Human Pose Estimation: A Benchmark and Learning from Noisy Input
Dec 11, 2023Despite the promising performance of current 3D human pose estimation techniques, understanding and enhancing their generalization on challenging in-the-wild videos remain an open problem. In this work, we focus on the robustness of 2D-to-3D pose lifters. To this end, we develop two benchmark datasets, namely Human3.6M-C and HumanEva-I-C, to examine the robustness of video-based 3D pose lifters to a wide range of common video corruptions including temporary occlusion, motion blur, and pixel-level noise. We observe the poor generalization of state-of-the-art 3D pose lifters in the presence of corruption and establish two techniques to tackle this issue. First, we introduce Temporal Additive Gaussian Noise (TAGN) as a simple yet effective 2D input pose data augmentation. Additionally, to incorporate the confidence scores output by the 2D pose detectors, we design a confidence-aware convolution (CA-Conv) block. Extensively tested on corrupted videos, the proposed strategies consistently boost the robustness of 3D pose lifters and serve as new baselines for future research.
Refined Temporal Pyramidal Compression-and-Amplification Transformer for 3D Human Pose Estimation
Sep 06, 2023Accurately estimating the 3D pose of humans in video sequences requires both accuracy and a well-structured architecture. With the success of transformers, we introduce the Refined Temporal Pyramidal Compression-and-Amplification (RTPCA) transformer. Exploiting the temporal dimension, RTPCA extends intra-block temporal modeling via its Temporal Pyramidal Compression-and-Amplification (TPCA) structure and refines inter-block feature interaction with a Cross-Layer Refinement (XLR) module. In particular, TPCA block exploits a temporal pyramid paradigm, reinforcing key and value representation capabilities and seamlessly extracting spatial semantics from motion sequences. We stitch these TPCA blocks with XLR that promotes rich semantic representation through continuous interaction of queries, keys, and values. This strategy embodies early-stage information with current flows, addressing typical deficits in detail and stability seen in other transformer-based methods. We demonstrate the effectiveness of RTPCA by achieving state-of-the-art results on Human3.6M, HumanEva-I, and MPI-INF-3DHP benchmarks with minimal computational overhead. The source code is available at https://github.com/hbing-l/RTPCA.
GLA-GCN: Global-local Adaptive Graph Convolutional Network for 3D Human Pose Estimation from Monocular Video
Jul 22, 2023



3D human pose estimation has been researched for decades with promising fruits. 3D human pose lifting is one of the promising research directions toward the task where both estimated pose and ground truth pose data are used for training. Existing pose lifting works mainly focus on improving the performance of estimated pose, but they usually underperform when testing on the ground truth pose data. We observe that the performance of the estimated pose can be easily improved by preparing good quality 2D pose, such as fine-tuning the 2D pose or using advanced 2D pose detectors. As such, we concentrate on improving the 3D human pose lifting via ground truth data for the future improvement of more quality estimated pose data. Towards this goal, a simple yet effective model called Global-local Adaptive Graph Convolutional Network (GLA-GCN) is proposed in this work. Our GLA-GCN globally models the spatiotemporal structure via a graph representation and backtraces local joint features for 3D human pose estimation via individually connected layers. To validate our model design, we conduct extensive experiments on three benchmark datasets: Human3.6M, HumanEva-I, and MPI-INF-3DHP. Experimental results show that our GLA-GCN implemented with ground truth 2D poses significantly outperforms state-of-the-art methods (e.g., up to around 3%, 17%, and 14% error reductions on Human3.6M, HumanEva-I, and MPI-INF-3DHP, respectively). GitHub: https://github.com/bruceyo/GLA-GCN.
ConvFormer: Parameter Reduction in Transformer Models for 3D Human Pose Estimation by Leveraging Dynamic Multi-Headed Convolutional Attention
Apr 04, 2023



Recently, fully-transformer architectures have replaced the defacto convolutional architecture for the 3D human pose estimation task. In this paper we propose \textbf{\textit{ConvFormer}}, a novel convolutional transformer that leverages a new \textbf{\textit{dynamic multi-headed convolutional self-attention}} mechanism for monocular 3D human pose estimation. We designed a spatial and temporal convolutional transformer to comprehensively model human joint relations within individual frames and globally across the motion sequence. Moreover, we introduce a novel notion of \textbf{\textit{temporal joints profile}} for our temporal ConvFormer that fuses complete temporal information immediately for a local neighborhood of joint features. We have quantitatively and qualitatively validated our method on three common benchmark datasets: Human3.6M, MPI-INF-3DHP, and HumanEva. Extensive experiments have been conducted to identify the optimal hyper-parameter set. These experiments demonstrated that we achieved a \textbf{significant parameter reduction relative to prior transformer models} while attaining State-of-the-Art (SOTA) or near SOTA on all three datasets. Additionally, we achieved SOTA for Protocol III on H36M for both GT and CPN detection inputs. Finally, we obtained SOTA on all three metrics for the MPI-INF-3DHP dataset and for all three subjects on HumanEva under Protocol II.
Can We Use Diffusion Probabilistic Models for 3D Motion Prediction?
Feb 28, 2023After many researchers observed fruitfulness from the recent diffusion probabilistic model, its effectiveness in image generation is actively studied these days. In this paper, our objective is to evaluate the potential of diffusion probabilistic models for 3D human motion-related tasks. To this end, this paper presents a study of employing diffusion probabilistic models to predict future 3D human motion(s) from the previously observed motion. Based on the Human 3.6M and HumanEva-I datasets, our results show that diffusion probabilistic models are competitive for both single (deterministic) and multiple (stochastic) 3D motion prediction tasks, after finishing a single training process. In addition, we find out that diffusion probabilistic models can offer an attractive compromise, since they can strike the right balance between the likelihood and diversity of the predicted future motions. Our code is publicly available on the project website: https://sites.google.com/view/diffusion-motion-prediction.
HSTFormer: Hierarchical Spatial-Temporal Transformers for 3D Human Pose Estimation
Jan 18, 2023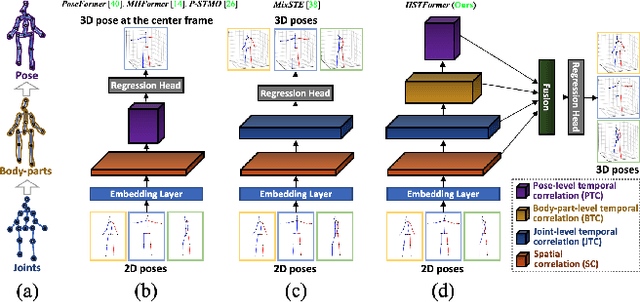
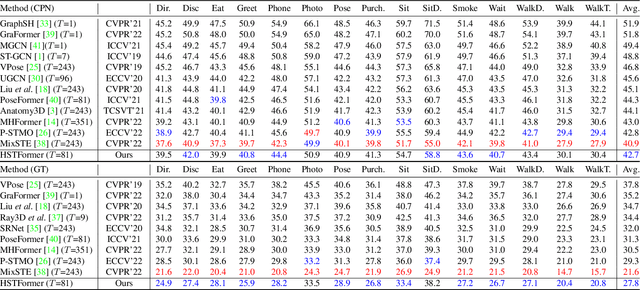
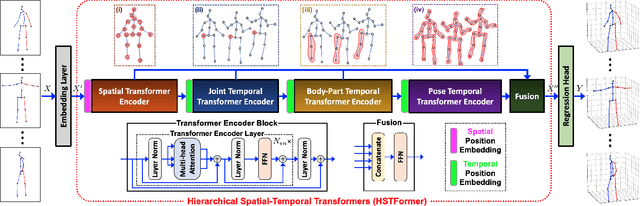
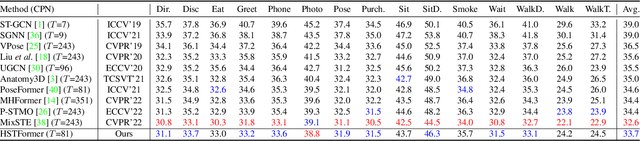
Transformer-based approaches have been successfully proposed for 3D human pose estimation (HPE) from 2D pose sequence and achieved state-of-the-art (SOTA) performance. However, current SOTAs have difficulties in modeling spatial-temporal correlations of joints at different levels simultaneously. This is due to the poses' spatial-temporal complexity. Poses move at various speeds temporarily with various joints and body-parts movement spatially. Hence, a cookie-cutter transformer is non-adaptable and can hardly meet the "in-the-wild" requirement. To mitigate this issue, we propose Hierarchical Spatial-Temporal transFormers (HSTFormer) to capture multi-level joints' spatial-temporal correlations from local to global gradually for accurate 3D HPE. HSTFormer consists of four transformer encoders (TEs) and a fusion module. To the best of our knowledge, HSTFormer is the first to study hierarchical TEs with multi-level fusion. Extensive experiments on three datasets (i.e., Human3.6M, MPI-INF-3DHP, and HumanEva) demonstrate that HSTFormer achieves competitive and consistent performance on benchmarks with various scales and difficulties. Specifically, it surpasses recent SOTAs on the challenging MPI-INF-3DHP dataset and small-scale HumanEva dataset, with a highly generalized systematic approach. The code is available at: https://github.com/qianxiaoye825/HSTFormer.
DiffuPose: Monocular 3D Human Pose Estimation via Denoising Diffusion Probabilistic Model
Dec 09, 2022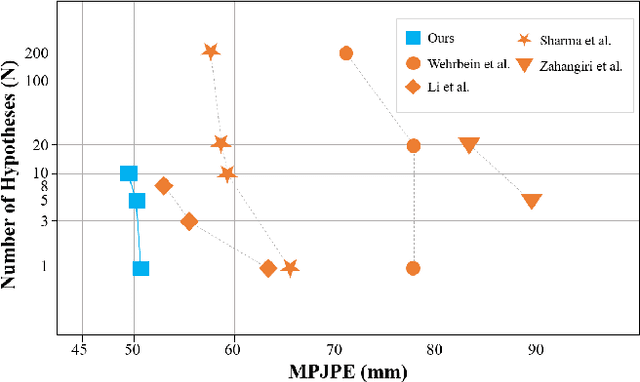
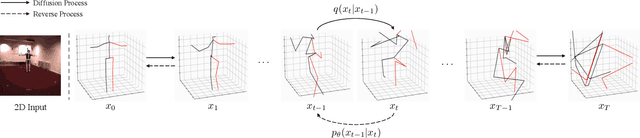
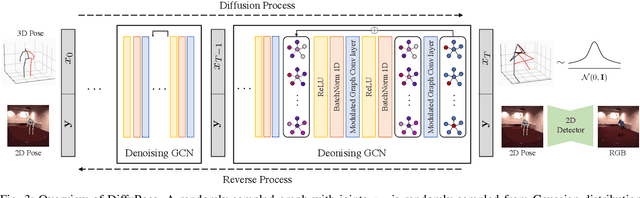
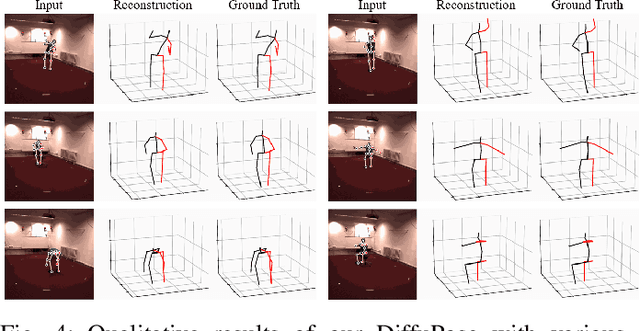
Thanks to the development of 2D keypoint detectors, monocular 3D human pose estimation (HPE) via 2D-to-3D uplifting approaches have achieved remarkable improvements. Still, monocular 3D HPE is a challenging problem due to the inherent depth ambiguities and occlusions. To handle this problem, many previous works exploit temporal information to mitigate such difficulties. However, there are many real-world applications where frame sequences are not accessible. This paper focuses on reconstructing a 3D pose from a single 2D keypoint detection. Rather than exploiting temporal information, we alleviate the depth ambiguity by generating multiple 3D pose candidates which can be mapped to an identical 2D keypoint. We build a novel diffusion-based framework to effectively sample diverse 3D poses from an off-the-shelf 2D detector. By considering the correlation between human joints by replacing the conventional denoising U-Net with graph convolutional network, our approach accomplishes further performance improvements. We evaluate our method on the widely adopted Human3.6M and HumanEva-I datasets. Comprehensive experiments are conducted to prove the efficacy of the proposed method, and they confirm that our model outperforms state-of-the-art multi-hypothesis 3D HPE methods.