 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacial Action Unit Detection
Facial action unit detection is the process of identifying and categorizing facial expressions based on facial muscle movements.
Papers and Code
Focal-RegionFace: Generating Fine-Grained Multi-attribute Descriptions for Arbitrarily Selected Face Focal Regions
Jan 01, 2026In this paper, we introduce an underexplored problem in facial analysis: generating and recognizing multi-attribute natural language descriptions, containing facial action units (AUs), emotional states, and age estimation, for arbitrarily selected face regions (termed FaceFocalDesc). We argue that the system's ability to focus on individual facial areas leads to better understanding and control. To achieve this capability, we construct a new multi-attribute description dataset for arbitrarily selected face regions, providing rich region-level annotations and natural language descriptions. Further, we propose a fine-tuned vision-language model based on Qwen2.5-VL, called Focal-RegionFace for facial state analysis, which incrementally refines its focus on localized facial features through multiple progressively fine-tuning stages, resulting in interpretable age estimation, FAU and emotion detection. Experimental results show that Focal-RegionFace achieves the best performance on the new benchmark in terms of traditional and widely used metrics, as well as new proposed metrics. This fully verifies its effectiveness and versatility in fine-grained multi-attribute face region-focal analysis scenarios.
FG 2025 TrustFAA: the First Workshop on Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)
Jun 05, 2025With the increasing prevalence and deployment of Emotion AI-powered facial affect analysis (FAA) tools, concerns about the trustworthiness of these systems have become more prominent. This first workshop on "Towards Trustworthy Facial Affect Analysis: Advancing Insights of Fairness, Explainability, and Safety (TrustFAA)" aims to bring together researchers who are investigating different challenges in relation to trustworthiness-such as interpretability, uncertainty, biases, and privacy-across various facial affect analysis tasks, including macro/ micro-expression recognition, facial action unit detection, other corresponding applications such as pain and depression detection, as well as human-robot interaction and collaboration. In alignment with FG2025's emphasis on ethics, as demonstrated by the inclusion of an Ethical Impact Statement requirement for this year's submissions, this workshop supports FG2025's efforts by encouraging research, discussion and dialogue on trustworthy FAA.
FauForensics: Boosting Audio-Visual Deepfake Detection with Facial Action Units
May 13, 2025The rapid evolution of generative AI has increased the threat of realistic audio-visual deepfakes, demanding robust detection methods. Existing solutions primarily address unimodal (audio or visual) forgeries but struggle with multimodal manipulations due to inadequate handling of heterogeneous modality features and poor generalization across datasets. To this end, we propose a novel framework called FauForensics by introducing biologically invariant facial action units (FAUs), which is a quantitative descriptor of facial muscle activity linked to emotion physiology. It serves as forgery-resistant representations that reduce domain dependency while capturing subtle dynamics often disrupted in synthetic content. Besides, instead of comparing entire video clips as in prior works, our method computes fine-grained frame-wise audiovisual similarities via a dedicated fusion module augmented with learnable cross-modal queries. It dynamically aligns temporal-spatial lip-audio relationships while mitigating multi-modal feature heterogeneity issues. Experiments on FakeAVCeleb and LAV-DF show state-of-the-art (SOTA) performance and superior cross-dataset generalizability with up to an average of 4.83\% than existing methods.
AU-LLM: Micro-Expression Action Unit Detection via Enhanced LLM-Based Feature Fusion
Jul 29, 2025The detection of micro-expression Action Units (AUs) is a formidable challenge in affective computing, pivotal for decoding subtle, involuntary human emotions. While Large Language Models (LLMs) demonstrate profound reasoning abilities, their application to the fine-grained, low-intensity domain of micro-expression AU detection remains unexplored. This paper pioneers this direction by introducing \textbf{AU-LLM}, a novel framework that for the first time uses LLM to detect AUs in micro-expression datasets with subtle intensities and the scarcity of data. We specifically address the critical vision-language semantic gap, the \textbf{Enhanced Fusion Projector (EFP)}. The EFP employs a Multi-Layer Perceptron (MLP) to intelligently fuse mid-level (local texture) and high-level (global semantics) visual features from a specialized 3D-CNN backbone into a single, information-dense token. This compact representation effectively empowers the LLM to perform nuanced reasoning over subtle facial muscle movements.Through extensive evaluations on the benchmark CASME II and SAMM datasets, including stringent Leave-One-Subject-Out (LOSO) and cross-domain protocols, AU-LLM establishes a new state-of-the-art, validating the significant potential and robustness of LLM-based reasoning for micro-expression analysis. The codes are available at https://github.com/ZS-liu-JLU/AU-LLMs.
AU-TTT: Vision Test-Time Training model for Facial Action Unit Detection
Mar 30, 2025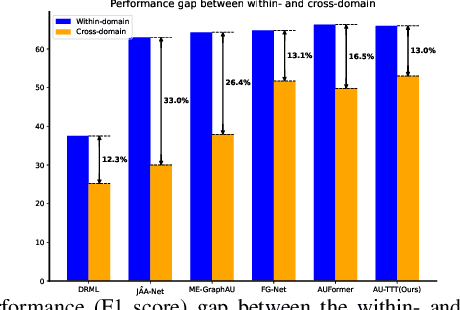
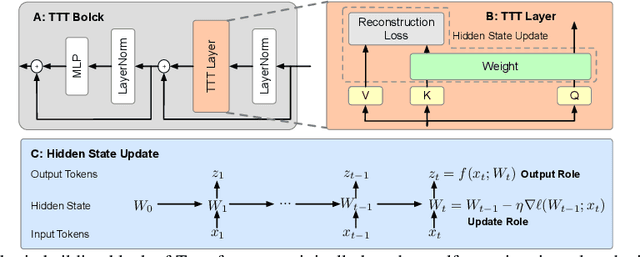
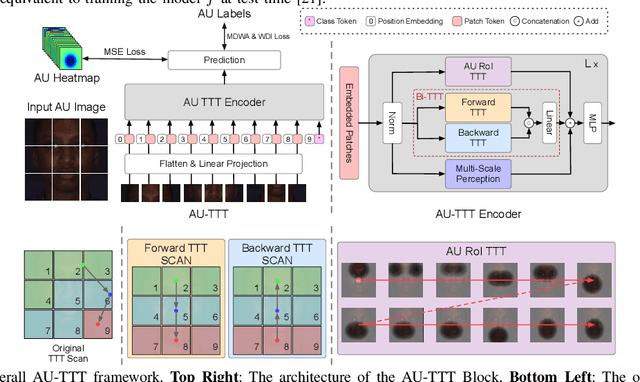
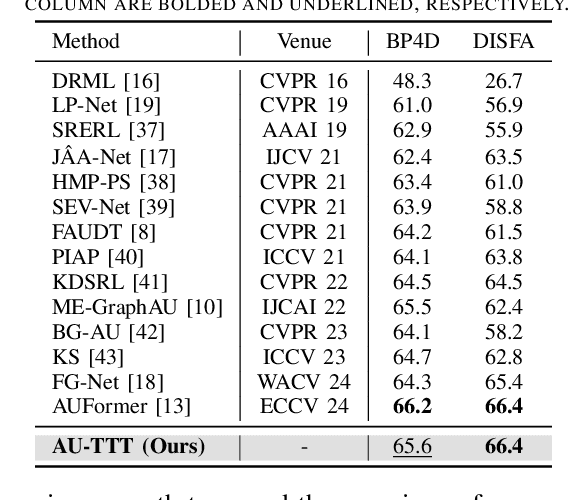
Facial Action Units (AUs) detection is a cornerstone of objective facial expression analysis and a critical focus in affective computing. Despite its importance, AU detection faces significant challenges, such as the high cost of AU annotation and the limited availability of datasets. These constraints often lead to overfitting in existing methods, resulting in substantial performance degradation when applied across diverse datasets. Addressing these issues is essential for improving the reliability and generalizability of AU detection methods. Moreover, many current approaches leverage Transformers for their effectiveness in long-context modeling, but they are hindered by the quadratic complexity of self-attention. Recently, Test-Time Training (TTT) layers have emerged as a promising solution for long-sequence modeling. Additionally, TTT applies self-supervised learning for iterative updates during both training and inference, offering a potential pathway to mitigate the generalization challenges inherent in AU detection tasks. In this paper, we propose a novel vision backbone tailored for AU detection, incorporating bidirectional TTT blocks, named AU-TTT. Our approach introduces TTT Linear to the AU detection task and optimizes image scanning mechanisms for enhanced performance. Additionally, we design an AU-specific Region of Interest (RoI) scanning mechanism to capture fine-grained facial features critical for AU detection. Experimental results demonstrate that our method achieves competitive performance in both within-domain and cross-domain scenarios.
Deception Detection in Dyadic Exchanges Using Multimodal Machine Learning: A Study on a Swedish Cohort
Jun 26, 2025This study investigates the efficacy of using multimodal machine learning techniques to detect deception in dyadic interactions, focusing on the integration of data from both the deceiver and the deceived. We compare early and late fusion approaches, utilizing audio and video data - specifically, Action Units and gaze information - across all possible combinations of modalities and participants. Our dataset, newly collected from Swedish native speakers engaged in truth or lie scenarios on emotionally relevant topics, serves as the basis for our analysis. The results demonstrate that incorporating both speech and facial information yields superior performance compared to single-modality approaches. Moreover, including data from both participants significantly enhances deception detection accuracy, with the best performance (71%) achieved using a late fusion strategy applied to both modalities and participants. These findings align with psychological theories suggesting differential control of facial and vocal expressions during initial interactions. As the first study of its kind on a Scandinavian cohort, this research lays the groundwork for future investigations into dyadic interactions, particularly within psychotherapy settings.
GraphAU-Pain: Graph-based Action Unit Representation for Pain Intensity Estimation
May 26, 2025Understanding pain-related facial behaviors is essential for digital healthcare in terms of effective monitoring, assisted diagnostics, and treatment planning, particularly for patients unable to communicate verbally. Existing data-driven methods of detecting pain from facial expressions are limited due to interpretability and severity quantification. To this end, we propose GraphAU-Pain, leveraging a graph-based framework to model facial Action Units (AUs) and their interrelationships for pain intensity estimation. AUs are represented as graph nodes, with co-occurrence relationships as edges, enabling a more expressive depiction of pain-related facial behaviors. By utilizing a relational graph neural network, our framework offers improved interpretability and significant performance gains. Experiments conducted on the publicly available UNBC dataset demonstrate the effectiveness of the GraphAU-Pain, achieving an F1-score of 66.21% and accuracy of 87.61% in pain intensity estimation.
Face-LLaVA: Facial Expression and Attribute Understanding through Instruction Tuning
Apr 09, 2025
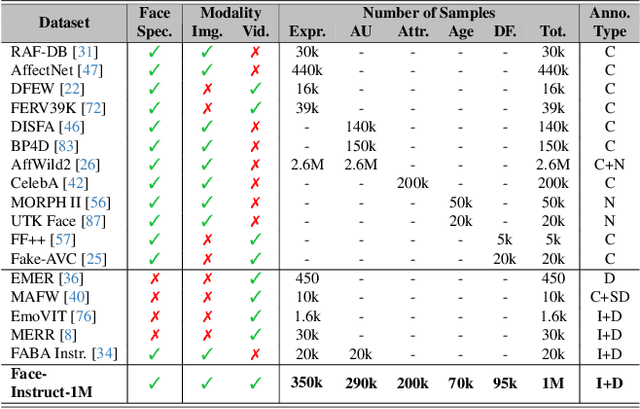

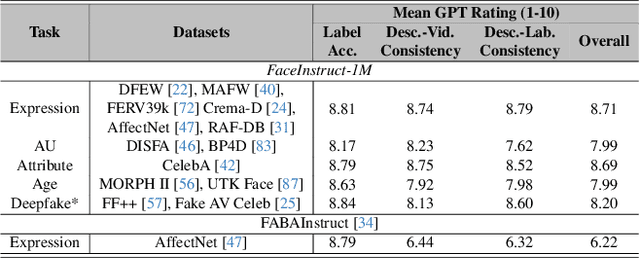
The human face plays a central role in social communication, necessitating the use of performant computer vision tools for human-centered applications. We propose Face-LLaVA, a multimodal large language model for face-centered, in-context learning, including facial expression and attribute recognition. Additionally, Face-LLaVA is able to generate natural language descriptions that can be used for reasoning. Leveraging existing visual databases, we first developed FaceInstruct-1M, a face-centered database for instruction tuning MLLMs for face processing. We then developed a novel face-specific visual encoder powered by Face-Region Guided Cross-Attention that integrates face geometry with local visual features. We evaluated the proposed method across nine different datasets and five different face processing tasks, including facial expression recognition, action unit detection, facial attribute detection, age estimation and deepfake detection. Face-LLaVA achieves superior results compared to existing open-source MLLMs and competitive performance compared to commercial solutions. Our model output also receives a higher reasoning rating by GPT under a zero-shot setting across all the tasks. Both our dataset and model wil be released at https://face-llava.github.io to support future advancements in social AI and foundational vision-language research.
Beyond FACS: Data-driven Facial Expression Dictionaries, with Application to Predicting Autism
May 30, 2025The Facial Action Coding System (FACS) has been used by numerous studies to investigate the links between facial behavior and mental health. The laborious and costly process of FACS coding has motivated the development of machine learning frameworks for Action Unit (AU) detection. Despite intense efforts spanning three decades, the detection accuracy for many AUs is considered to be below the threshold needed for behavioral research. Also, many AUs are excluded altogether, making it impossible to fulfill the ultimate goal of FACS-the representation of any facial expression in its entirety. This paper considers an alternative approach. Instead of creating automated tools that mimic FACS experts, we propose to use a new coding system that mimics the key properties of FACS. Specifically, we construct a data-driven coding system called the Facial Basis, which contains units that correspond to localized and interpretable 3D facial movements, and overcomes three structural limitations of automated FACS coding. First, the proposed method is completely unsupervised, bypassing costly, laborious and variable manual annotation. Second, Facial Basis reconstructs all observable movement, rather than relying on a limited repertoire of recognizable movements (as in automated FACS). Finally, the Facial Basis units are additive, whereas AUs may fail detection when they appear in a non-additive combination. The proposed method outperforms the most frequently used AU detector in predicting autism diagnosis from in-person and remote conversations, highlighting the importance of encoding facial behavior comprehensively. To our knowledge, Facial Basis is the first alternative to FACS for deconstructing facial expressions in videos into localized movements. We provide an open source implementation of the method at github.com/sariyanidi/FacialBasis.
Decoupled Doubly Contrastive Learning for Cross Domain Facial Action Unit Detection
Mar 12, 2025Despite the impressive performance of current vision-based facial action unit (AU) detection approaches, they are heavily susceptible to the variations across different domains and the cross-domain AU detection methods are under-explored. In response to this challenge, we propose a decoupled doubly contrastive adaptation (D$^2$CA) approach to learn a purified AU representation that is semantically aligned for the source and target domains. Specifically, we decompose latent representations into AU-relevant and AU-irrelevant components, with the objective of exclusively facilitating adaptation within the AU-relevant subspace. To achieve the feature decoupling, D$^2$CA is trained to disentangle AU and domain factors by assessing the quality of synthesized faces in cross-domain scenarios when either AU or domain attributes are modified. To further strengthen feature decoupling, particularly in scenarios with limited AU data diversity, D$^2$CA employs a doubly contrastive learning mechanism comprising image and feature-level contrastive learning to ensure the quality of synthesized faces and mitigate feature ambiguities. This new framework leads to an automatically learned, dedicated separation of AU-relevant and domain-relevant factors, and it enables intuitive, scale-specific control of the cross-domain facial image synthesis. Extensive experiments demonstrate the efficacy of D$^2$CA in successfully decoupling AU and domain factors, yielding visually pleasing cross-domain synthesized facial images. Meanwhile, D$^2$CA consistently outperforms state-of-the-art cross-domain AU detection approaches, achieving an average F1 score improvement of 6\%-14\% across various cross-domain scenarios.
* Accepted by IEEE Transactions on Image Processing 2025. A novel and elegant feature decoupling method for cross-domain facial action unit detection