 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassfication
Papers and Code
Directional Gradient Projection for Robust Fine-Tuning of Foundation Models
Feb 21, 2025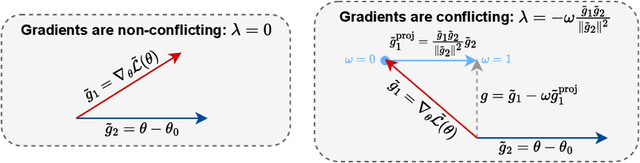
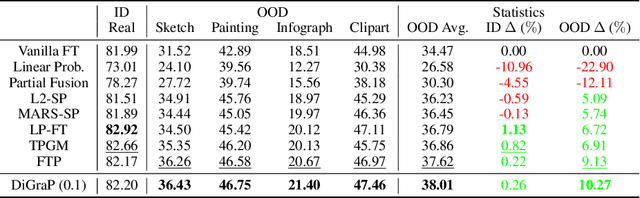

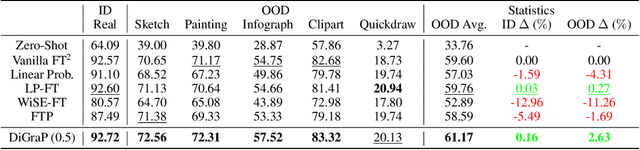
Robust fine-tuning aims to adapt large foundation models to downstream tasks while preserving their robustness to distribution shifts. Existing methods primarily focus on constraining and projecting current model towards the pre-trained initialization based on the magnitudes between fine-tuned and pre-trained weights, which often require extensive hyper-parameter tuning and can sometimes result in underfitting. In this work, we propose Directional Gradient Projection (DiGraP), a novel layer-wise trainable method that incorporates directional information from gradients to bridge regularization and multi-objective optimization. Besides demonstrating our method on image classification, as another contribution we generalize this area to the multi-modal evaluation settings for robust fine-tuning. Specifically, we first bridge the uni-modal and multi-modal gap by performing analysis on Image Classification reformulated Visual Question Answering (VQA) benchmarks and further categorize ten out-of-distribution (OOD) VQA datasets by distribution shift types and degree (i.e. near versus far OOD). Experimental results show that DiGraP consistently outperforms existing baselines across Image Classfication and VQA tasks with discriminative and generative backbones, improving both in-distribution (ID) generalization and OOD robustness.
The Pitfalls of Defining Hallucination
Jan 15, 2024Despite impressive advances in Natural Language Generation (NLG) and Large Language Models (LLMs), researchers are still unclear about important aspects of NLG evaluation. To substantiate this claim, I examine current classifications of hallucination and omission in Data-text NLG, and I propose a logic-based synthesis of these classfications. I conclude by highlighting some remaining limitations of all current thinking about hallucination and by discussing implications for LLMs.
Why semantics matters: A deep study on semantic particle-filtering localization in a LiDAR semantic pole-map
May 23, 2023



In most urban and suburban areas, pole-like structures such as tree trunks or utility poles are ubiquitous. These structural landmarks are very useful for the localization of autonomous vehicles given their geometrical locations in maps and measurements from sensors. In this work, we aim at creating an accurate map for autonomous vehicles or robots with pole-like structures as the dominant localization landmarks, hence called pole-map. In contrast to the previous pole-based mapping or localization methods, we exploit the semantics of pole-like structures. Specifically, semantic segmentation is achieved by a new mask-range transformer network in a mask-classfication paradigm. With the semantics extracted for the pole-like structures in each frame, a multi-layer semantic pole-map is created by aggregating the detected pole-like structures from all frames. Given the semantic pole-map, we propose a semantic particle-filtering localization scheme for vehicle localization. Theoretically, we have analyzed why the semantic information can benefit the particle-filter localization, and empirically it is validated on the public SemanticKITTI dataset that the particle-filtering localization with semantics achieves much better performance than the counterpart without semantics when each particle's odometry prediction and/or the online observation is subject to uncertainties at significant levels.
sMRI-PatchNet: A novel explainable patch-based deep learning network for Alzheimer's disease diagnosis and discriminative atrophy localisation with Structural MRI
Feb 20, 2023



Structural magnetic resonance imaging (sMRI) can identify subtle brain changes due to its high contrast for soft tissues and high spatial resolution. It has been widely used in diagnosing neurological brain diseases, such as Alzheimer disease (AD). However, the size of 3D high-resolution data poses a significant challenge for data analysis and processing. Since only a few areas of the brain show structural changes highly associated with AD, the patch-based methods dividing the whole image data into several small regular patches have shown promising for more efficient sMRI-based image analysis. The major challenges of the patch-based methods on sMRI include identifying the discriminative patches, combining features from the discrete discriminative patches, and designing appropriate classifiers. This work proposes a novel patch-based deep learning network (sMRI-PatchNet) with explainable patch localisation and selection for AD diagnosis using sMRI. Specifically, it consists of two primary components: 1) A fast and efficient explainable patch selection mechanism for determining the most discriminative patches based on computing the SHapley Additive exPlanations (SHAP) contribution to a transfer learning model for AD diagnosis on massive medical data; and 2) A novel patch-based network for extracting deep features and AD classfication from the selected patches with position embeddings to retain position information, capable of capturing the global and local information of inter- and intra-patches. This method has been applied for the AD classification and the prediction of the transitional state moderate cognitive impairment (MCI) conversion with real datasets.
$β$-CapsNet: Learning Disentangled Representation for CapsNet by Information Bottleneck
Sep 12, 2022We present a framework for learning disentangled representation of CapsNet by information bottleneck constraint that distills information into a compact form and motivates to learn an interpretable factorized capsule. In our $\beta$-CapsNet framework, hyperparameter $\beta$ is utilized to trade-off disentanglement and other tasks, variational inference is utilized to convert the information bottleneck term into a KL divergence that is approximated as a constraint on the mean of the capsule. For supervised learning, class independent mask vector is used for understanding the types of variations synthetically irrespective of the image class, we carry out extensive quantitative and qualitative experiments by tuning the parameter $\beta$ to figure out the relationship between disentanglement, reconstruction and classfication performance. Furthermore, the unsupervised $\beta$-CapsNet and the corresponding dynamic routing algorithm is proposed for learning disentangled capsule in an unsupervised manner, extensive empirical evaluations suggest that our $\beta$-CapsNet achieves state-of-the-art disentanglement performance compared to CapsNet and various baselines on several complex datasets both in supervision and unsupervised scenes.
Tracking environmental policy changes in the Brazilian Federal Official Gazette
Feb 11, 2022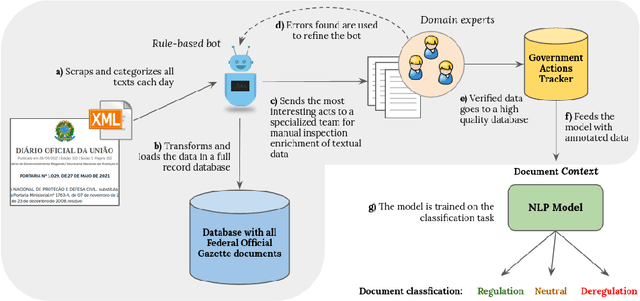
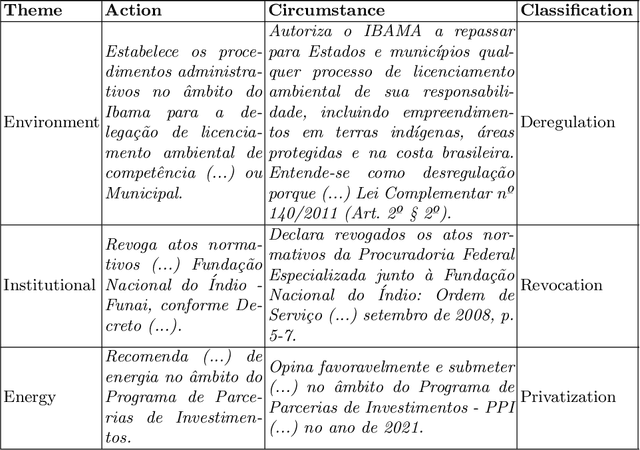
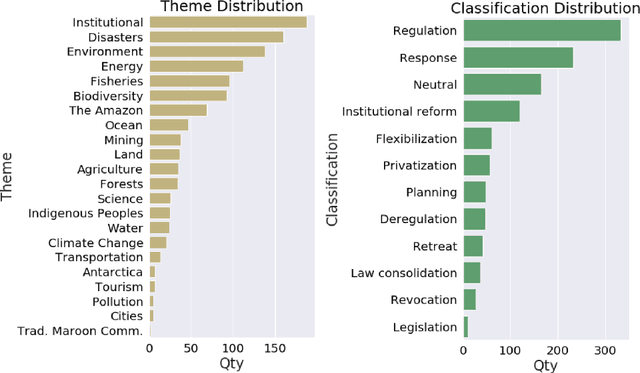
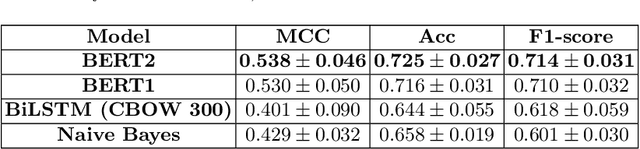
Even though most of its energy generation comes from renewable sources, Brazil is one of the largest emitters of greenhouse gases in the world, due to intense farming and deforestation of biomes such as the Amazon Rainforest, whose preservation is essential for compliance with the Paris Agreement. Still, regardless of lobbies or prevailing political orientation, all government legal actions are published daily in the Brazilian Federal Official Gazette (BFOG, or "Di\'ario Oficial da Uni\~ao" in Portuguese). However, with hundreds of decrees issued every day by the authorities, it is absolutely burdensome to manually analyze all these processes and find out which ones can pose serious environmental hazards. In this paper, we present a strategy to compose automated techniques and domain expert knowledge to process all the data from the BFOG. We also provide the Government Actions Tracker, a highly curated dataset, in Portuguese, annotated by domain experts, on federal government acts about the Brazilian environmental policies. Finally, we build and compared four different NLP models on the classfication task in this dataset. Our best model achieved a F1-score of $0.714 \pm 0.031$. In the future, this system should serve to scale up the high-quality tracking of all oficial documents with a minimum of human supervision and contribute to increasing society's awareness of government actions.
Cognitive Visual Inspection Service for LCD Manufacturing Industry
Jan 11, 2021
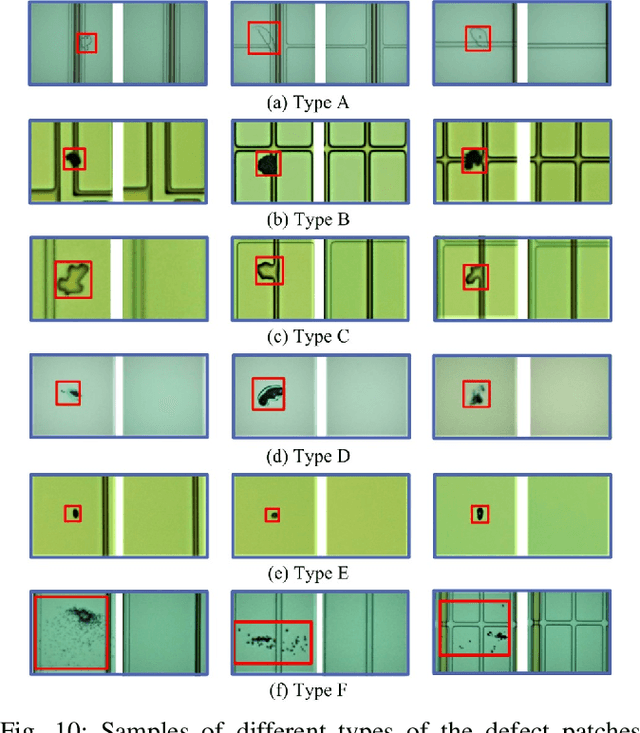
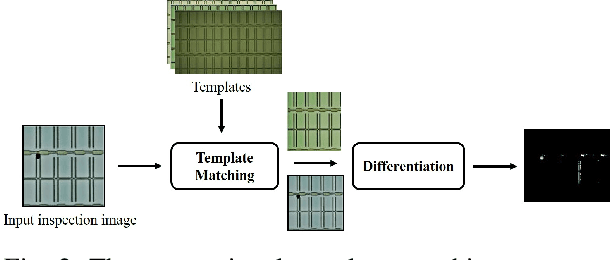
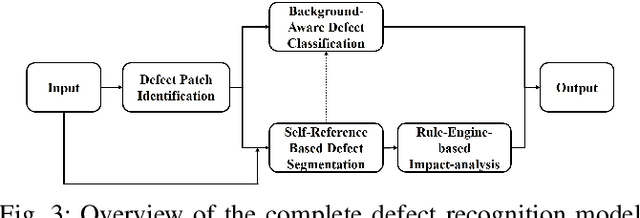
With the rapid growth of display devices, quality inspection via machine vision technology has become increasingly important for flat-panel displays (FPD) industry. This paper discloses a novel visual inspection system for liquid crystal display (LCD), which is currently a dominant type in the FPD industry. The system is based on two cornerstones: robust/high-performance defect recognition model and cognitive visual inspection service architecture. A hybrid application of conventional computer vision technique and the latest deep convolutional neural network (DCNN) leads to an integrated defect detection, classfication and impact evaluation model that can be economically trained with only image-level class annotations to achieve a high inspection accuracy. In addition, the properly trained model is robust to the variation of the image qulity, significantly alleviating the dependency between the model prediction performance and the image aquisition environment. This in turn justifies the decoupling of the defect recognition functions from the front-end device to the back-end serivce, motivating the design and realization of the cognitive visual inspection service architecture. Empirical case study is performed on a large-scale real-world LCD dataset from a manufacturing line with different layers and products, which shows the promising utility of our system, which has been deployed in a real-world LCD manufacturing line from a major player in the world.
Few-shot Learning for Domain-specfic Fine-grained Image Classfication
Jul 23, 2019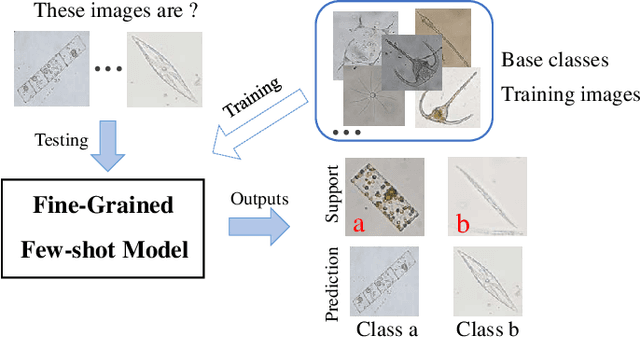
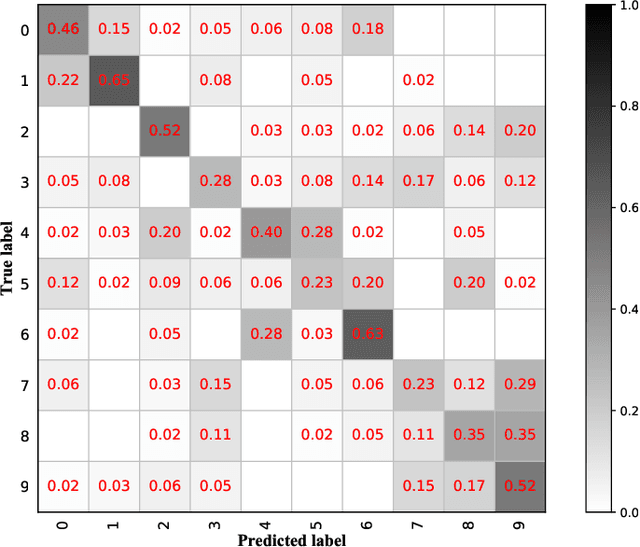
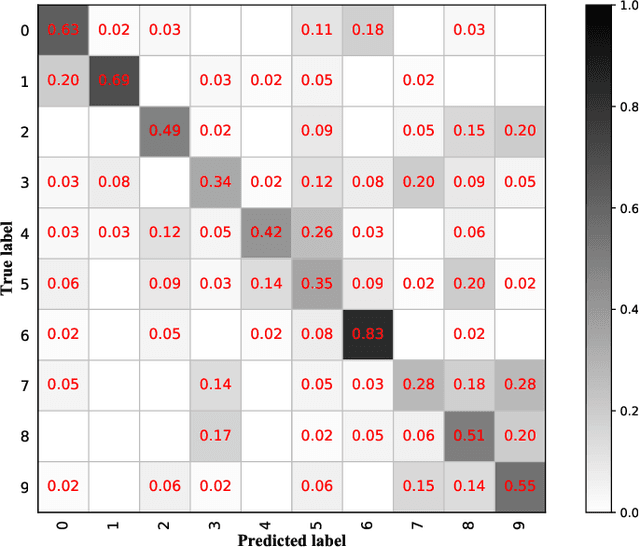
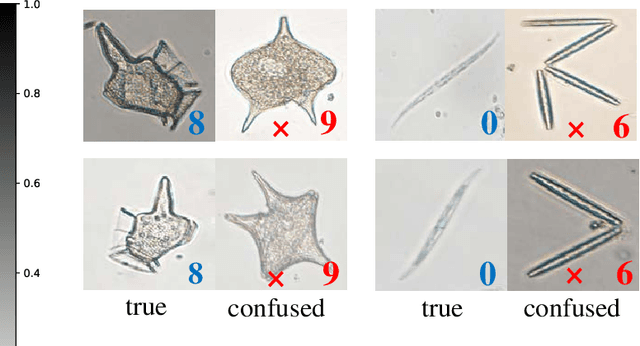
Learning to recognize novel visual categories from a few examples is a challenging task for machines in real-world applications. In contrast, humans have the ability to discriminate even similar objects with little supervision. This paper attempts to address the few-shot fine-grained recognition problem. We propose a feature fusion model to explore the largest discriminative features by focusing on key regions. The model utilizes focus-area location to discover the perceptually similar regions among objects. High-order integration is employed to capture the interaction information among intra-parts. We also design a Center Neighbor Loss to form robust embedding space distribution for generating discriminative features. Furthermore, we build a typical fine-grained and few-shot learning dataset miniPPlankton from the real-world application in the area of marine ecological environment. Extensive experiments are carried out to validate the performance of our model. First, the model is evaluated with two challenging experiments based on the miniDogsNet and Caltech-UCSD public datasets. The results demonstrate that our model achieves competitive performance compared with state-of-the-art models. Then, we implement our model for the real-world phytoplankton recognition task. The experimental results show the superiority of the proposed model compared with others on the miniPPlankton dataset.
Learning to Balance: Bayesian Meta-Learning for Imbalanced and Out-of-distribution Tasks
May 30, 2019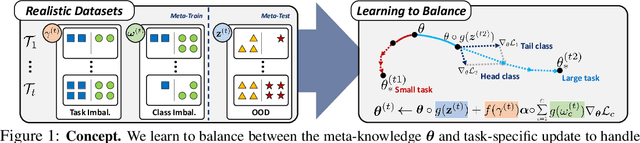
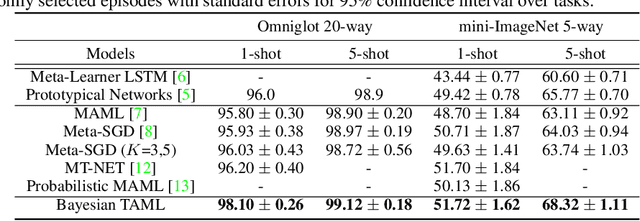
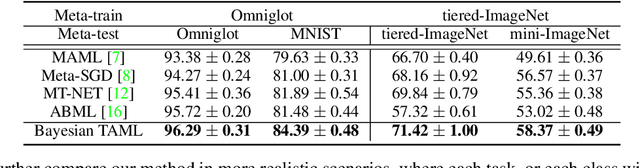
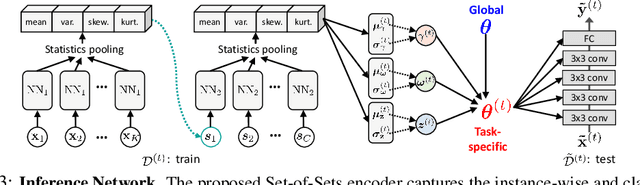
While tasks could come with varying number of instances in realistic settings, the existing meta-learning approaches for few-shot classfication assume even task distributions where the number of instances for each task and class are fixed. Due to such restriction, they learn to equally utilize the meta-knowledge across all the tasks, even when the number of instances per task and class largely varies. Moreover, they do not consider distributional difference in unseen tasks at the meta-test time, on which the meta-knowledge may have varying degree of usefulness depending on the task relatedness. To overcome these limitations, we propose a novel meta-learning model that adaptively balances the effect of the meta-learning and task-specific learning, and also class-specific learning within each task. Through the learning of the balancing variables, we can decide whether to obtain a solution close to the initial parameter or far from it. We formulate this objective into a Bayesian inference framework and solve it using variational inference. Our Bayesian Task-Adaptive Meta-Learning (Bayesian-TAML) significantly outperforms existing meta-learning approaches on benchmark datasets for both few-shot and realistic class- and task-imbalanced datasets, with especially higher gains on the latter.
Road Damage Detection And Classification In Smartphone Captured Images Using Mask R-CNN
Nov 12, 2018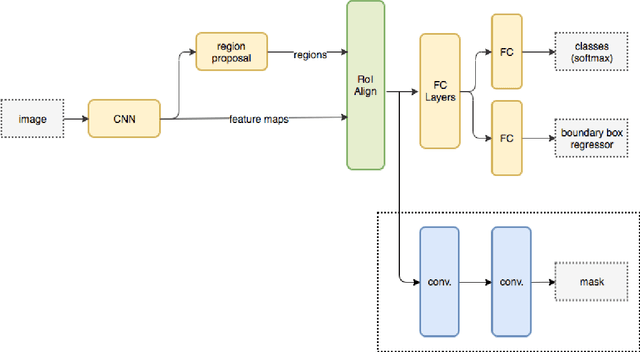
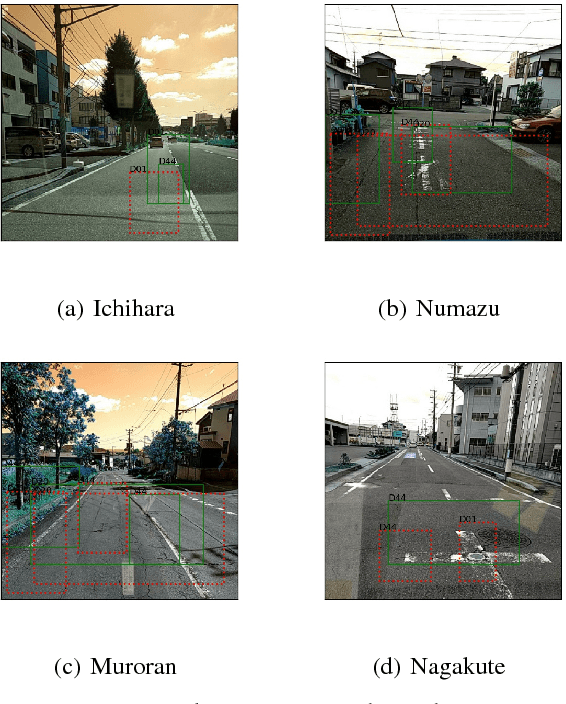


This paper summarizes the design, experiments and results of our solution to the Road Damage Detection and Classification Challenge held as part of the 2018 IEEE International Conference On Big Data Cup. Automatic detection and classification of damage in roads is an essential problem for multiple applications like maintenance and autonomous driving. We demonstrate that convolutional neural net based instance detection and classfication approaches can be used to solve this problem. In particular we show that Mask-RCNN, one of the state-of-the-art algorithms for object detection, localization and instance segmentation of natural images, can be used to perform this task in a fast manner with effective results. We achieve a mean F1 score of 0.528 at an IoU of 50% on the task of detection and classification of different types of damages in real-world road images acquired using a smartphone camera and our average inference time for each image is 0.105 seconds on an NVIDIA GeForce 1080Ti graphic card. The code and saved models for our approach can be found here : https://github.com/sshkhr/BigDataCup18 Submission