 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBird S Eye View Semantic Segmentation
Papers and Code
KD360-VoxelBEV: LiDAR and 360-degree Camera Cross Modality Knowledge Distillation for Bird's-Eye-View Segmentation
Dec 17, 2025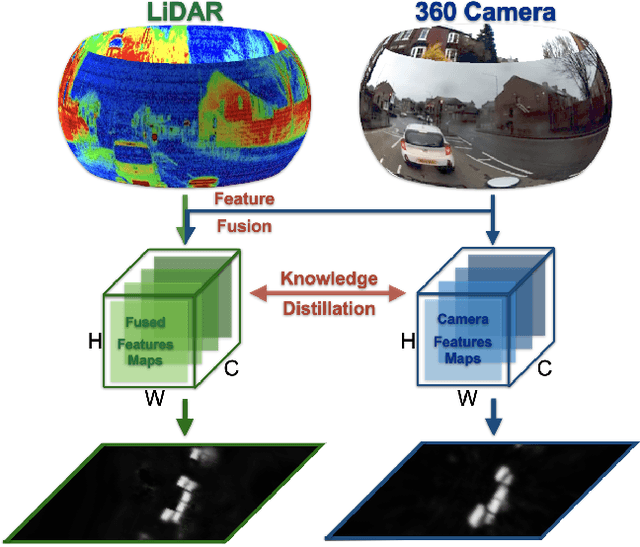
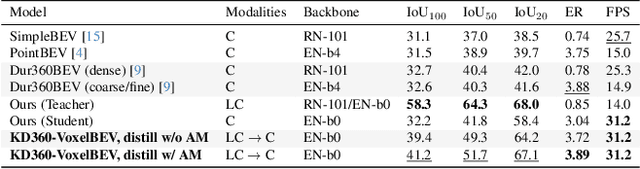


We present the first cross-modality distillation framework specifically tailored for single-panoramic-camera Bird's-Eye-View (BEV) segmentation. Our approach leverages a novel LiDAR image representation fused from range, intensity and ambient channels, together with a voxel-aligned view transformer that preserves spatial fidelity while enabling efficient BEV processing. During training, a high-capacity LiDAR and camera fusion Teacher network extracts both rich spatial and semantic features for cross-modality knowledge distillation into a lightweight Student network that relies solely on a single 360-degree panoramic camera image. Extensive experiments on the Dur360BEV dataset demonstrate that our teacher model significantly outperforms existing camera-based BEV segmentation methods, achieving a 25.6\% IoU improvement. Meanwhile, the distilled Student network attains competitive performance with an 8.5\% IoU gain and state-of-the-art inference speed of 31.2 FPS. Moreover, evaluations on KITTI-360 (two fisheye cameras) confirm that our distillation framework generalises to diverse camera setups, underscoring its feasibility and robustness. This approach reduces sensor complexity and deployment costs while providing a practical solution for efficient, low-cost BEV segmentation in real-world autonomous driving.
HENet++: Hybrid Encoding and Multi-task Learning for 3D Perception and End-to-end Autonomous Driving
Nov 10, 2025Three-dimensional feature extraction is a critical component of autonomous driving systems, where perception tasks such as 3D object detection, bird's-eye-view (BEV) semantic segmentation, and occupancy prediction serve as important constraints on 3D features. While large image encoders, high-resolution images, and long-term temporal inputs can significantly enhance feature quality and deliver remarkable performance gains, these techniques are often incompatible in both training and inference due to computational resource constraints. Moreover, different tasks favor distinct feature representations, making it difficult for a single model to perform end-to-end inference across multiple tasks while maintaining accuracy comparable to that of single-task models. To alleviate these issues, we present the HENet and HENet++ framework for multi-task 3D perception and end-to-end autonomous driving. Specifically, we propose a hybrid image encoding network that uses a large image encoder for short-term frames and a small one for long-term frames. Furthermore, our framework simultaneously extracts both dense and sparse features, providing more suitable representations for different tasks, reducing cumulative errors, and delivering more comprehensive information to the planning module. The proposed architecture maintains compatibility with various existing 3D feature extraction methods and supports multimodal inputs. HENet++ achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, while also attaining the lowest collision rate on the nuScenes end-to-end autonomous driving benchmark.
ME$^3$-BEV: Mamba-Enhanced Deep Reinforcement Learning for End-to-End Autonomous Driving with BEV-Perception
Aug 08, 2025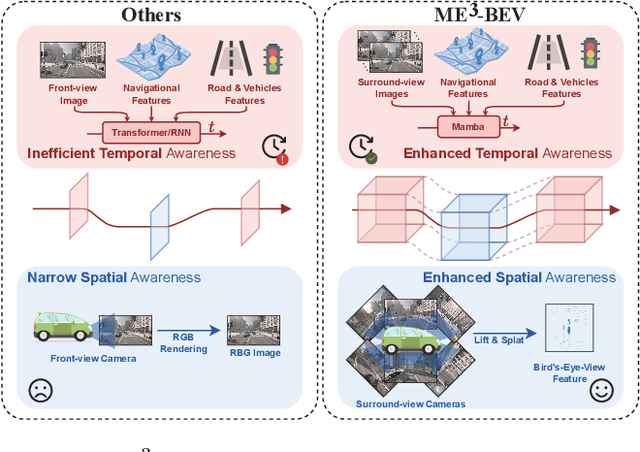
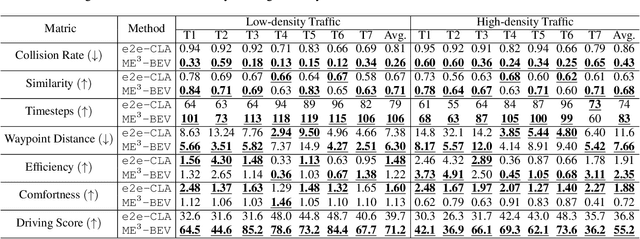
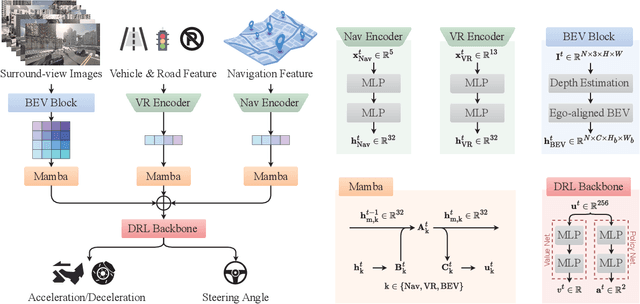

Autonomous driving systems face significant challenges in perceiving complex environments and making real-time decisions. Traditional modular approaches, while offering interpretability, suffer from error propagation and coordination issues, whereas end-to-end learning systems can simplify the design but face computational bottlenecks. This paper presents a novel approach to autonomous driving using deep reinforcement learning (DRL) that integrates bird's-eye view (BEV) perception for enhanced real-time decision-making. We introduce the \texttt{Mamba-BEV} model, an efficient spatio-temporal feature extraction network that combines BEV-based perception with the Mamba framework for temporal feature modeling. This integration allows the system to encode vehicle surroundings and road features in a unified coordinate system and accurately model long-range dependencies. Building on this, we propose the \texttt{ME$^3$-BEV} framework, which utilizes the \texttt{Mamba-BEV} model as a feature input for end-to-end DRL, achieving superior performance in dynamic urban driving scenarios. We further enhance the interpretability of the model by visualizing high-dimensional features through semantic segmentation, providing insight into the learned representations. Extensive experiments on the CARLA simulator demonstrate that \texttt{ME$^3$-BEV} outperforms existing models across multiple metrics, including collision rate and trajectory accuracy, offering a promising solution for real-time autonomous driving.
RESAR-BEV: An Explainable Progressive Residual Autoregressive Approach for Camera-Radar Fusion in BEV Segmentation
May 10, 2025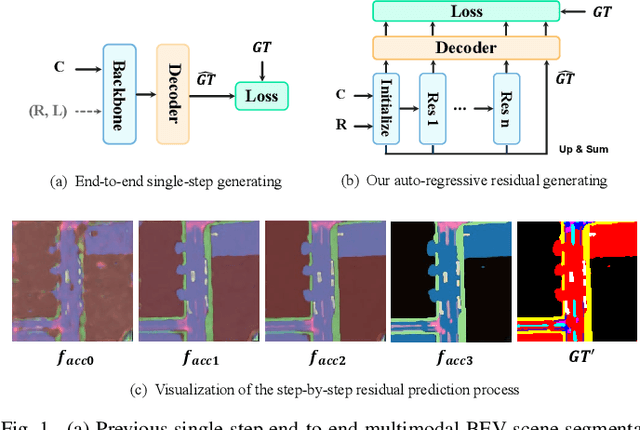
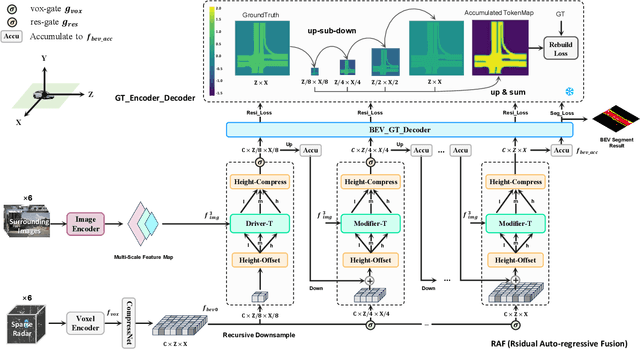
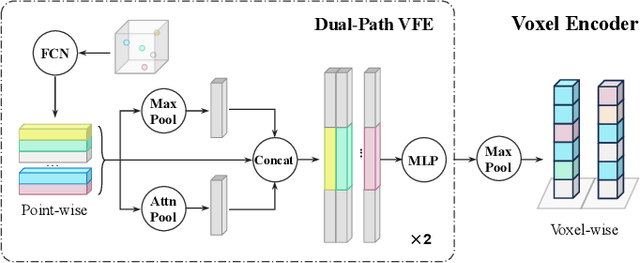
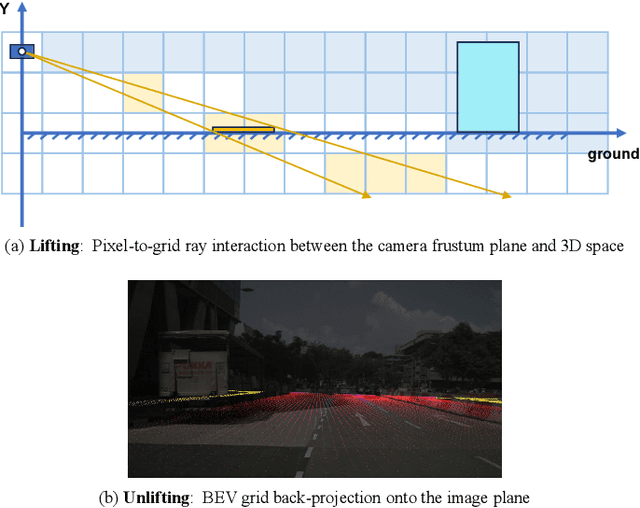
Bird's-Eye-View (BEV) semantic segmentation provides comprehensive environmental perception for autonomous driving but suffers multi-modal misalignment and sensor noise. We propose RESAR-BEV, a progressive refinement framework that advances beyond single-step end-to-end approaches: (1) progressive refinement through residual autoregressive learning that decomposes BEV segmentation into interpretable coarse-to-fine stages via our Drive-Transformer and Modifier-Transformer residual prediction cascaded architecture, (2) robust BEV representation combining ground-proximity voxels with adaptive height offsets and dual-path voxel feature encoding (max+attention pooling) for efficient feature extraction, and (3) decoupled supervision with offline Ground Truth decomposition and online joint optimization to prevent overfitting while ensuring structural coherence. Experiments on nuScenes demonstrate RESAR-BEV achieves state-of-the-art performance with 54.0% mIoU across 7 essential driving-scene categories while maintaining real-time capability at 14.6 FPS. The framework exhibits robustness in challenging scenarios of long-range perception and adverse weather conditions.
MapFM: Foundation Model-Driven HD Mapping with Multi-Task Contextual Learning
Jun 18, 2025In autonomous driving, high-definition (HD) maps and semantic maps in bird's-eye view (BEV) are essential for accurate localization, planning, and decision-making. This paper introduces an enhanced End-to-End model named MapFM for online vectorized HD map generation. We show significantly boost feature representation quality by incorporating powerful foundation model for encoding camera images. To further enrich the model's understanding of the environment and improve prediction quality, we integrate auxiliary prediction heads for semantic segmentation in the BEV representation. This multi-task learning approach provides richer contextual supervision, leading to a more comprehensive scene representation and ultimately resulting in higher accuracy and improved quality of the predicted vectorized HD maps. The source code is available at https://github.com/LIvanoff/MapFM.
InterLoc: LiDAR-based Intersection Localization using Road Segmentation with Automated Evaluation Method
May 01, 2025Intersections are geometric and functional key points in every road network. They offer strong landmarks to correct GNSS dropouts and anchor new sensor data in up-to-date maps. Despite that importance, intersection detectors either ignore the rich semantic information already computed onboard or depend on scarce, hand-labeled intersection datasets. To close that gap, this paper presents a LiDAR-based method for intersection detection that (i) fuses semantic road segmentation with vehicle localization to detect intersection candidates in a bird's eye view (BEV) representation and (ii) refines those candidates by analyzing branch topology with a least squares formulation. To evaluate our method, we introduce an automated benchmarking pipeline that pairs detections with OpenStreetMap (OSM) intersection nodes using precise GNSS/INS ground-truth poses. Tested on eight SemanticKITTI sequences, the approach achieves a mean localization error of 1.9 m, 89% precision, and 77% recall at a 5 m tolerance, outperforming the latest learning-based baseline. Moreover, the method is robust to segmentation errors higher than those of the benchmark model, demonstrating its applicability in the real world.
RendBEV: Semantic Novel View Synthesis for Self-Supervised Bird's Eye View Segmentation
Feb 20, 2025Bird's Eye View (BEV) semantic maps have recently garnered a lot of attention as a useful representation of the environment to tackle assisted and autonomous driving tasks. However, most of the existing work focuses on the fully supervised setting, training networks on large annotated datasets. In this work, we present RendBEV, a new method for the self-supervised training of BEV semantic segmentation networks, leveraging differentiable volumetric rendering to receive supervision from semantic perspective views computed by a 2D semantic segmentation model. Our method enables zero-shot BEV semantic segmentation, and already delivers competitive results in this challenging setting. When used as pretraining to then fine-tune on labeled BEV ground-truth, our method significantly boosts performance in low-annotation regimes, and sets a new state of the art when fine-tuning on all available labels.
SparseMeXT Unlocking the Potential of Sparse Representations for HD Map Construction
May 12, 2025Recent advancements in high-definition \emph{HD} map construction have demonstrated the effectiveness of dense representations, which heavily rely on computationally intensive bird's-eye view \emph{BEV} features. While sparse representations offer a more efficient alternative by avoiding dense BEV processing, existing methods often lag behind due to the lack of tailored designs. These limitations have hindered the competitiveness of sparse representations in online HD map construction. In this work, we systematically revisit and enhance sparse representation techniques, identifying key architectural and algorithmic improvements that bridge the gap with--and ultimately surpass--dense approaches. We introduce a dedicated network architecture optimized for sparse map feature extraction, a sparse-dense segmentation auxiliary task to better leverage geometric and semantic cues, and a denoising module guided by physical priors to refine predictions. Through these enhancements, our method achieves state-of-the-art performance on the nuScenes dataset, significantly advancing HD map construction and centerline detection. Specifically, SparseMeXt-Tiny reaches a mean average precision \emph{mAP} of 55.5% at 32 frames per second \emph{fps}, while SparseMeXt-Base attains 65.2% mAP. Scaling the backbone and decoder further, SparseMeXt-Large achieves an mAP of 68.9% at over 20 fps, establishing a new benchmark for sparse representations in HD map construction. These results underscore the untapped potential of sparse methods, challenging the conventional reliance on dense representations and redefining efficiency-performance trade-offs in the field.
SegLocNet: Multimodal Localization Network for Autonomous Driving via Bird's-Eye-View Segmentation
Feb 28, 2025Robust and accurate localization is critical for autonomous driving. Traditional GNSS-based localization methods suffer from signal occlusion and multipath effects in urban environments. Meanwhile, methods relying on high-definition (HD) maps are constrained by the high costs associated with the construction and maintenance of HD maps. Standard-definition (SD) maps-based methods, on the other hand, often exhibit unsatisfactory performance or poor generalization ability due to overfitting. To address these challenges, we propose SegLocNet, a multimodal GNSS-free localization network that achieves precise localization using bird's-eye-view (BEV) semantic segmentation. SegLocNet employs a BEV segmentation network to generate semantic maps from multiple sensor inputs, followed by an exhaustive matching process to estimate the vehicle's ego pose. This approach avoids the limitations of regression-based pose estimation and maintains high interpretability and generalization. By introducing a unified map representation, our method can be applied to both HD and SD maps without any modifications to the network architecture, thereby balancing localization accuracy and area coverage. Extensive experiments on the nuScenes and Argoverse datasets demonstrate that our method outperforms the current state-of-the-art methods, and that our method can accurately estimate the ego pose in urban environments without relying on GNSS, while maintaining strong generalization ability. Our code and pre-trained model will be released publicly.
Epipolar Attention Field Transformers for Bird's Eye View Semantic Segmentation
Dec 02, 2024



Spatial understanding of the semantics of the surroundings is a key capability needed by autonomous cars to enable safe driving decisions. Recently, purely vision-based solutions have gained increasing research interest. In particular, approaches extracting a bird's eye view (BEV) from multiple cameras have demonstrated great performance for spatial understanding. This paper addresses the dependency on learned positional encodings to correlate image and BEV feature map elements for transformer-based methods. We propose leveraging epipolar geometric constraints to model the relationship between cameras and the BEV by Epipolar Attention Fields. They are incorporated into the attention mechanism as a novel attribution term, serving as an alternative to learned positional encodings. Experiments show that our method EAFormer outperforms previous BEV approaches by 2% mIoU for map semantic segmentation and exhibits superior generalization capabilities compared to implicitly learning the camera configuration.