 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSurface Normal Estimation
Papers and Code
Splat and Distill: Augmenting Teachers with Feed-Forward 3D Reconstruction For 3D-Aware Distillation
Feb 05, 2026Vision Foundation Models (VFMs) have achieved remarkable success when applied to various downstream 2D tasks. Despite their effectiveness, they often exhibit a critical lack of 3D awareness. To this end, we introduce Splat and Distill, a framework that instills robust 3D awareness into 2D VFMs by augmenting the teacher model with a fast, feed-forward 3D reconstruction pipeline. Given 2D features produced by a teacher model, our method first lifts these features into an explicit 3D Gaussian representation, in a feedforward manner. These 3D features are then ``splatted" onto novel viewpoints, producing a set of novel 2D feature maps used to supervise the student model, ``distilling" geometrically grounded knowledge. By replacing slow per-scene optimization of prior work with our feed-forward lifting approach, our framework avoids feature-averaging artifacts, creating a dynamic learning process where the teacher's consistency improves alongside that of the student. We conduct a comprehensive evaluation on a suite of downstream tasks, including monocular depth estimation, surface normal estimation, multi-view correspondence, and semantic segmentation. Our method significantly outperforms prior works, not only achieving substantial gains in 3D awareness but also enhancing the underlying semantic richness of 2D features. Project page is available at https://davidshavin4.github.io/Splat-and-Distill/
* Accepted to ICLR 2026
TransNormal: Dense Visual Semantics for Diffusion-based Transparent Object Normal Estimation
Jan 31, 2026Monocular normal estimation for transparent objects is critical for laboratory automation, yet it remains challenging due to complex light refraction and reflection. These optical properties often lead to catastrophic failures in conventional depth and normal sensors, hindering the deployment of embodied AI in scientific environments. We propose TransNormal, a novel framework that adapts pre-trained diffusion priors for single-step normal regression. To handle the lack of texture in transparent surfaces, TransNormal integrates dense visual semantics from DINOv3 via a cross-attention mechanism, providing strong geometric cues. Furthermore, we employ a multi-task learning objective and wavelet-based regularization to ensure the preservation of fine-grained structural details. To support this task, we introduce TransNormal-Synthetic, a physics-based dataset with high-fidelity normal maps for transparent labware. Extensive experiments demonstrate that TransNormal significantly outperforms state-of-the-art methods: on the ClearGrasp benchmark, it reduces mean error by 24.4% and improves 11.25° accuracy by 22.8%; on ClearPose, it achieves a 15.2% reduction in mean error. The code and dataset will be made publicly available at https://longxiang-ai.github.io/TransNormal.
SpaRRTa: A Synthetic Benchmark for Evaluating Spatial Intelligence in Visual Foundation Models
Jan 16, 2026Visual Foundation Models (VFMs), such as DINO and CLIP, excel in semantic understanding of images but exhibit limited spatial reasoning capabilities, which limits their applicability to embodied systems. As a result, recent work incorporates some 3D tasks (such as depth estimation) into VFM training. However, VFM performance remains inconsistent across other spatial tasks, raising the question of whether these models truly have spatial awareness or overfit to specific 3D objectives. To address this question, we introduce the Spatial Relation Recognition Task (SpaRRTa) benchmark, which evaluates the ability of VFMs to identify relative positions of objects in the image. Unlike traditional 3D objectives that focus on precise metric prediction (e.g., surface normal estimation), SpaRRTa probes a fundamental capability underpinning more advanced forms of human-like spatial understanding. SpaRRTa generates an arbitrary number of photorealistic images with diverse scenes and fully controllable object arrangements, along with freely accessible spatial annotations. Evaluating a range of state-of-the-art VFMs, we reveal significant disparities between their spatial reasoning abilities. Through our analysis, we provide insights into the mechanisms that support or hinder spatial awareness in modern VFMs. We hope that SpaRRTa will serve as a useful tool for guiding the development of future spatially aware visual models.
Graph Neural Network Reveals the Local Cortical Morphology of Brain Aging in Normal Cognition and Alzheimers Disease
Jan 16, 2026Estimating brain age (BA) from T1-weighted magnetic resonance images (MRIs) provides a useful approach to map the anatomic features of brain senescence. Whereas global BA (GBA) summarizes overall brain health, local BA (LBA) can reveal spatially localized patterns of aging. Although previous studies have examined anatomical contributors to GBA, no framework has been established to compute LBA using cortical morphology. To address this gap, we introduce a novel graph neural network (GNN) that uses morphometric features (cortical thickness, curvature, surface area, gray/white matter intensity ratio and sulcal depth) to estimate LBA across the cortical surface at high spatial resolution (mean inter-vertex distance = 1.37 mm). Trained on cortical surface meshes extracted from the MRIs of cognitively normal adults (N = 14,250), our GNN identifies prefrontal and parietal association cortices as early sites of morphometric aging, in concordance with biological theories of brain aging. Feature comparison using integrated gradients reveals that morphological aging is driven primarily by changes in surface area (gyral crowns and highly folded regions) and cortical thickness (occipital lobes), with additional contributions from gray/white matter intensity ratio (frontal lobes and sulcal troughs) and curvature (sulcal troughs). In Alzheimers disease (AD), as expected, the model identifies widespread, excessive morphological aging in parahippocampal gyri and related temporal structures. Significant associations are found between regional LBA gaps and neuropsychological measures descriptive of AD-related cognitive impairment, suggesting an intimate relationship between morphological cortical aging and cognitive decline. These results highlight the ability of GNN-derived gero-morphometry to provide insights into local brain aging.
GeoSurDepth: Spatial Geometry-Consistent Self-Supervised Depth Estimation for Surround-View Cameras
Jan 09, 2026Accurate surround-view depth estimation provides a competitive alternative to laser-based sensors and is essential for 3D scene understanding in autonomous driving. While prior studies have proposed various approaches that primarily focus on enforcing cross-view constraints at the photometric level, few explicitly exploit the rich geometric structure inherent in both monocular and surround-view setting. In this work, we propose GeoSurDepth, a framework that leverages geometry consistency as the primary cue for surround-view depth estimation. Concretely, we utilize foundation models as a pseudo geometry prior and feature representation enhancement tool to guide the network to maintain surface normal consistency in spatial 3D space and regularize object- and texture-consistent depth estimation in 2D. In addition, we introduce a novel view synthesis pipeline where 2D-3D lifting is achieved with dense depth reconstructed via spatial warping, encouraging additional photometric supervision across temporal, spatial, and spatial-temporal contexts, and compensating for the limitations of single-view image reconstruction. Finally, a newly-proposed adaptive joint motion learning strategy enables the network to adaptively emphasize informative spatial geometry cues for improved motion reasoning. Extensive experiments on DDAD and nuScenes demonstrate that GeoSurDepth achieves state-of-the-art performance, validating the effectiveness of our approach. Our framework highlights the importance of exploiting geometry coherence and consistency for robust self-supervised multi-view depth estimation.
Learned Hemodynamic Coupling Inference in Resting-State Functional MRI
Jan 02, 2026Functional magnetic resonance imaging (fMRI) provides an indirect measurement of neuronal activity via hemodynamic responses that vary across brain regions and individuals. Ignoring this hemodynamic variability can bias downstream connectivity estimates. Furthermore, the hemodynamic parameters themselves may serve as important imaging biomarkers. Estimating spatially varying hemodynamics from resting-state fMRI (rsfMRI) is therefore an important but challenging blind inverse problem, since both the latent neural activity and the hemodynamic coupling are unknown. In this work, we propose a methodology for inferring hemodynamic coupling on the cortical surface from rsfMRI. Our approach avoids the highly unstable joint recovery of neural activity and hemodynamics by marginalizing out the latent neural signal and basing inference on the resulting marginal likelihood. To enable scalable, high-resolution estimation, we employ a deep neural network combined with conditional normalizing flows to accurately approximate this intractable marginal likelihood, while enforcing spatial coherence through priors defined on the cortical surface that admit sparse representations. The proposed approach is extensively validated using synthetic data and real fMRI datasets, demonstrating clear improvements over current methods for hemodynamic estimation and downstream connectivity analysis.
ShinyNeRF: Digitizing Anisotropic Appearance in Neural Radiance Fields
Dec 25, 2025Recent advances in digitization technologies have transformed the preservation and dissemination of cultural heritage. In this vein, Neural Radiance Fields (NeRF) have emerged as a leading technology for 3D digitization, delivering representations with exceptional realism. However, existing methods struggle to accurately model anisotropic specular surfaces, typically observed, for example, on brushed metals. In this work, we introduce ShinyNeRF, a novel framework capable of handling both isotropic and anisotropic reflections. Our method is capable of jointly estimating surface normals, tangents, specular concentration, and anisotropy magnitudes of an Anisotropic Spherical Gaussian (ASG) distribution, by learning an approximation of the outgoing radiance as an encoded mixture of isotropic von Mises-Fisher (vMF) distributions. Experimental results show that ShinyNeRF not only achieves state-of-the-art performance on digitizing anisotropic specular reflections, but also offers plausible physical interpretations and editing of material properties compared to existing methods.
Pix2NPHM: Learning to Regress NPHM Reconstructions From a Single Image
Dec 19, 2025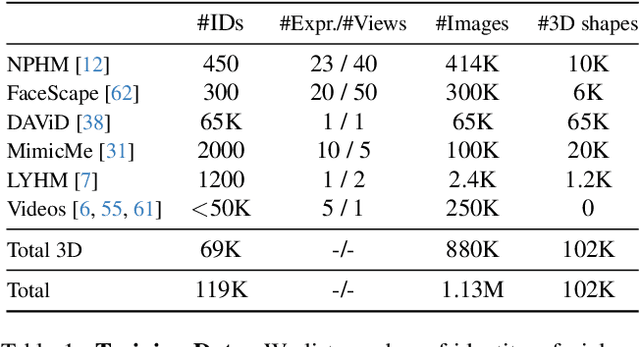

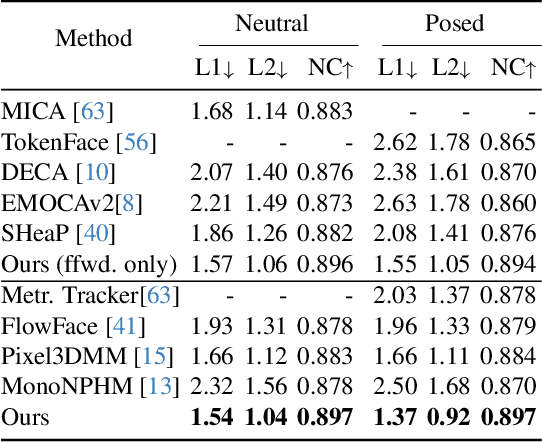
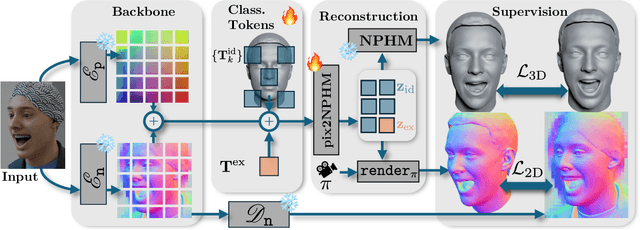
Neural Parametric Head Models (NPHMs) are a recent advancement over mesh-based 3d morphable models (3DMMs) to facilitate high-fidelity geometric detail. However, fitting NPHMs to visual inputs is notoriously challenging due to the expressive nature of their underlying latent space. To this end, we propose Pix2NPHM, a vision transformer (ViT) network that directly regresses NPHM parameters, given a single image as input. Compared to existing approaches, the neural parametric space allows our method to reconstruct more recognizable facial geometry and accurate facial expressions. For broad generalization, we exploit domain-specific ViTs as backbones, which are pretrained on geometric prediction tasks. We train Pix2NPHM on a mixture of 3D data, including a total of over 100K NPHM registrations that enable direct supervision in SDF space, and large-scale 2D video datasets, for which normal estimates serve as pseudo ground truth geometry. Pix2NPHM not only allows for 3D reconstructions at interactive frame rates, it is also possible to improve geometric fidelity by a subsequent inference-time optimization against estimated surface normals and canonical point maps. As a result, we achieve unprecedented face reconstruction quality that can run at scale on in-the-wild data.
Multi-View Foundation Models
Dec 17, 2025



Foundation models are vital tools in various Computer Vision applications. They take as input a single RGB image and output a deep feature representation that is useful for various applications. However, in case we have multiple views of the same 3D scene, they operate on each image independently and do not always produce consistent features for the same 3D point. We propose a way to convert a Foundation Model into a Multi-View Foundation Model. Such a model takes as input a set of images and outputs a feature map for each image such that the features of corresponding points are as consistent as possible. This approach bypasses the need to build a consistent 3D model of the features and allows direct manipulation in the image space. Specifically, we show how to augment Transformers-based foundation models (i.e., DINO, SAM, CLIP) with intermediate 3D-aware attention layers that help match features across different views. As leading examples, we show surface normal estimation and multi-view segmentation tasks. Quantitative experiments show that our method improves feature matching considerably compared to current foundation models.
Diffusion Knows Transparency: Repurposing Video Diffusion for Transparent Object Depth and Normal Estimation
Dec 29, 2025Transparent objects remain notoriously hard for perception systems: refraction, reflection and transmission break the assumptions behind stereo, ToF and purely discriminative monocular depth, causing holes and temporally unstable estimates. Our key observation is that modern video diffusion models already synthesize convincing transparent phenomena, suggesting they have internalized the optical rules. We build TransPhy3D, a synthetic video corpus of transparent/reflective scenes: 11k sequences rendered with Blender/Cycles. Scenes are assembled from a curated bank of category-rich static assets and shape-rich procedural assets paired with glass/plastic/metal materials. We render RGB + depth + normals with physically based ray tracing and OptiX denoising. Starting from a large video diffusion model, we learn a video-to-video translator for depth (and normals) via lightweight LoRA adapters. During training we concatenate RGB and (noisy) depth latents in the DiT backbone and co-train on TransPhy3D and existing frame-wise synthetic datasets, yielding temporally consistent predictions for arbitrary-length input videos. The resulting model, DKT, achieves zero-shot SOTA on real and synthetic video benchmarks involving transparency: ClearPose, DREDS (CatKnown/CatNovel), and TransPhy3D-Test. It improves accuracy and temporal consistency over strong image/video baselines, and a normal variant sets the best video normal estimation results on ClearPose. A compact 1.3B version runs at ~0.17 s/frame. Integrated into a grasping stack, DKT's depth boosts success rates across translucent, reflective and diffuse surfaces, outperforming prior estimators. Together, these results support a broader claim: "Diffusion knows transparency." Generative video priors can be repurposed, efficiently and label-free, into robust, temporally coherent perception for challenging real-world manipulation.