 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMillion Song Dataset
Papers and Code
Towards Effective Negation Modeling in Joint Audio-Text Models for Music
Jan 20, 2026Joint audio-text models are widely used for music retrieval, yet they struggle with semantic phenomena such as negation. Negation is fundamental for distinguishing the absence (or presence) of musical elements (e.g., "with vocals" vs. "without vocals"), but current systems fail to represent this reliably. In this work, we investigate and mitigate this limitation by training CLAP models from scratch on the Million Song Dataset with LP-MusicCaps-MSD captions. We introduce negation through text augmentation and a dissimilarity-based contrastive loss, designed to explicitly separate original and negated captions in the joint embedding space. To evaluate progress, we propose two protocols that frame negation modeling as retrieval and binary classification tasks. Experiments demonstrate that both methods, individually and combined, improve negation handling while largely preserving retrieval performance.
On the Mechanisms of Collaborative Learning in VAE Recommenders
Nov 10, 2025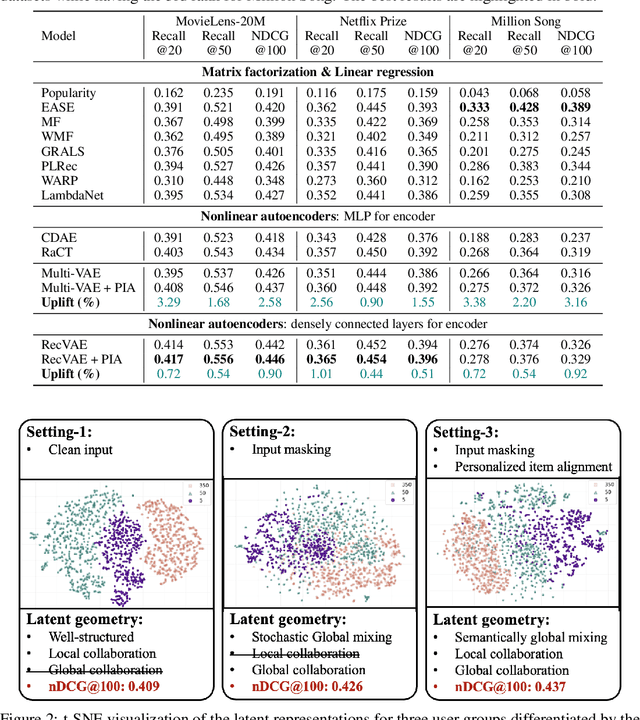
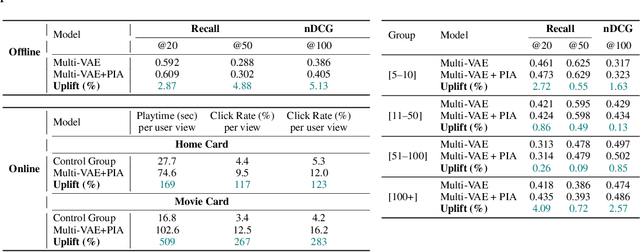

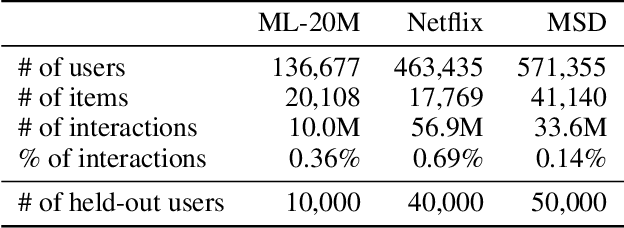
Variational Autoencoders (VAEs) are a powerful alternative to matrix factorization for recommendation. A common technique in VAE-based collaborative filtering (CF) consists in applying binary input masking to user interaction vectors, which improves performance but remains underexplored theoretically. In this work, we analyze how collaboration arises in VAE-based CF and show it is governed by latent proximity: we derive a latent sharing radius that informs when an SGD update on one user strictly reduces the loss on another user, with influence decaying as the latent Wasserstein distance increases. We further study the induced geometry: with clean inputs, VAE-based CF primarily exploits \emph{local} collaboration between input-similar users and under-utilizes global collaboration between far-but-related users. We compare two mechanisms that encourage \emph{global} mixing and characterize their trade-offs: (1) $β$-KL regularization directly tightens the information bottleneck, promoting posterior overlap but risking representational collapse if too large; (2) input masking induces stochastic geometric contractions and expansions, which can bring distant users onto the same latent neighborhood but also introduce neighborhood drift. To preserve user identity while enabling global consistency, we propose an anchor regularizer that aligns user posteriors with item embeddings, stabilizing users under masking and facilitating signal sharing across related items. Our analyses are validated on the Netflix, MovieLens-20M, and Million Song datasets. We also successfully deployed our proposed algorithm on an Amazon streaming platform following a successful online experiment.
Contrastive and Transfer Learning for Effective Audio Fingerprinting through a Real-World Evaluation Protocol
Jul 08, 2025Recent advances in song identification leverage deep neural networks to learn compact audio fingerprints directly from raw waveforms. While these methods perform well under controlled conditions, their accuracy drops significantly in real-world scenarios where the audio is captured via mobile devices in noisy environments. In this paper, we introduce a novel evaluation protocol designed to better reflect such real-world conditions. We generate three recordings of the same audio, each with increasing levels of noise, captured using a mobile device's microphone. Our results reveal a substantial performance drop for two state-of-the-art CNN-based models under this protocol, compared to previously reported benchmarks. Additionally, we highlight the critical role of the augmentation pipeline during training with contrastive loss. By introduction low pass and high pass filters in the augmentation pipeline we significantly increase the performance of both systems in our proposed evaluation. Furthermore, we develop a transformer-based model with a tailored projection module and demonstrate that transferring knowledge from a semantically relevant domain yields a more robust solution. The transformer architecture outperforms CNN-based models across all noise levels, and query durations. In low noise conditions it achieves 47.99% for 1-sec queries, and 97% for 10-sec queries in finding the correct song, surpassing by 14%, and by 18.5% the second-best performing model, respectively, Under heavy noise levels, we achieve a detection rate 56.5% for 15-second query duration. All experiments are conducted on public large-scale dataset of over 100K songs, with queries matched against a database of 56 million vectors.
* International Journal of Music Science, Technology and Art, 15 pages, 7 figures
Music Discovery Dialogue Generation Using Human Intent Analysis and Large Language Models
Nov 11, 2024A conversational music retrieval system can help users discover music that matches their preferences through dialogue. To achieve this, a conversational music retrieval system should seamlessly engage in multi-turn conversation by 1) understanding user queries and 2) responding with natural language and retrieved music. A straightforward solution would be a data-driven approach utilizing such conversation logs. However, few datasets are available for the research and are limited in terms of volume and quality. In this paper, we present a data generation framework for rich music discovery dialogue using a large language model (LLM) and user intents, system actions, and musical attributes. This is done by i) dialogue intent analysis using grounded theory, ii) generating attribute sequences via cascading database filtering, and iii) generating utterances using large language models. By applying this framework to the Million Song dataset, we create LP-MusicDialog, a Large Language Model based Pseudo Music Dialogue dataset, containing over 288k music conversations using more than 319k music items. Our evaluation shows that the synthetic dataset is competitive with an existing, small human dialogue dataset in terms of dialogue consistency, item relevance, and naturalness. Furthermore, using the dataset, we train a conversational music retrieval model and show promising results.
Revisiting BPR: A Replicability Study of a Common Recommender System Baseline
Sep 21, 2024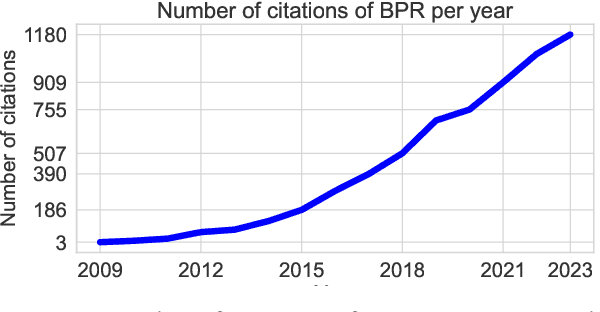
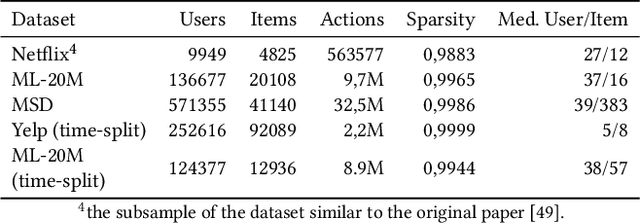
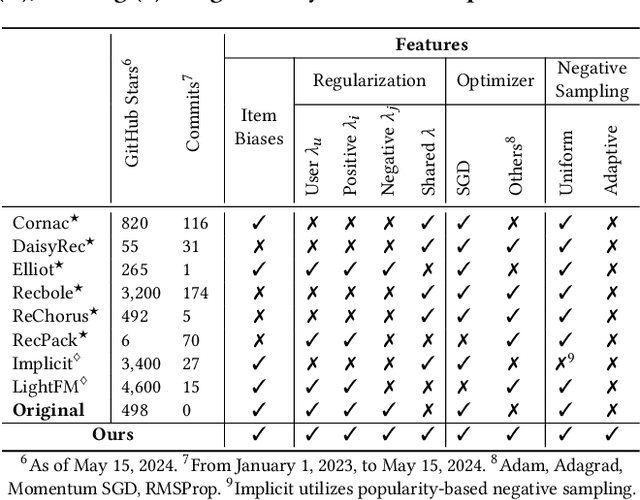
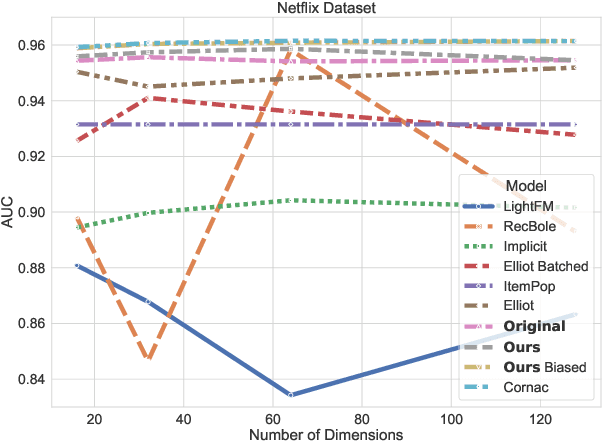
Bayesian Personalized Ranking (BPR), a collaborative filtering approach based on matrix factorization, frequently serves as a benchmark for recommender systems research. However, numerous studies often overlook the nuances of BPR implementation, claiming that it performs worse than newly proposed methods across various tasks. In this paper, we thoroughly examine the features of the BPR model, indicating their impact on its performance, and investigate open-source BPR implementations. Our analysis reveals inconsistencies between these implementations and the original BPR paper, leading to a significant decrease in performance of up to 50% for specific implementations. Furthermore, through extensive experiments on real-world datasets under modern evaluation settings, we demonstrate that with proper tuning of its hyperparameters, the BPR model can achieve performance levels close to state-of-the-art methods on the top-n recommendation tasks and even outperform them on specific datasets. Specifically, on the Million Song Dataset, the BPR model with hyperparameters tuning statistically significantly outperforms Mult-VAE by 10% in NDCG@100 with binary relevance function.
LyCon: Lyrics Reconstruction from the Bag-of-Words Using Large Language Models
Aug 27, 2024This paper addresses the unique challenge of conducting research in lyric studies, where direct use of lyrics is often restricted due to copyright concerns. Unlike typical data, internet-sourced lyrics are frequently protected under copyright law, necessitating alternative approaches. Our study introduces a novel method for generating copyright-free lyrics from publicly available Bag-of-Words (BoW) datasets, which contain the vocabulary of lyrics but not the lyrics themselves. Utilizing metadata associated with BoW datasets and large language models, we successfully reconstructed lyrics. We have compiled and made available a dataset of reconstructed lyrics, LyCon, aligned with metadata from renowned sources including the Million Song Dataset, Deezer Mood Detection Dataset, and AllMusic Genre Dataset, available for public access. We believe that the integration of metadata such as mood annotations or genres enables a variety of academic experiments on lyrics, such as conditional lyric generation.
Music Era Recognition Using Supervised Contrastive Learning and Artist Information
Jul 07, 2024Does popular music from the 60s sound different than that of the 90s? Prior study has shown that there would exist some variations of patterns and regularities related to instrumentation changes and growing loudness across multi-decadal trends. This indicates that perceiving the era of a song from musical features such as audio and artist information is possible. Music era information can be an important feature for playlist generation and recommendation. However, the release year of a song can be inaccessible in many circumstances. This paper addresses a novel task of music era recognition. We formulate the task as a music classification problem and propose solutions based on supervised contrastive learning. An audio-based model is developed to predict the era from audio. For the case where the artist information is available, we extend the audio-based model to take multimodal inputs and develop a framework, called MultiModal Contrastive (MMC) learning, to enhance the training. Experimental result on Million Song Dataset demonstrates that the audio-based model achieves 54% in accuracy with a tolerance of 3-years range; incorporating the artist information with the MMC framework for training leads to 9% improvement further.
Musical Word Embedding for Music Tagging and Retrieval
Apr 23, 2024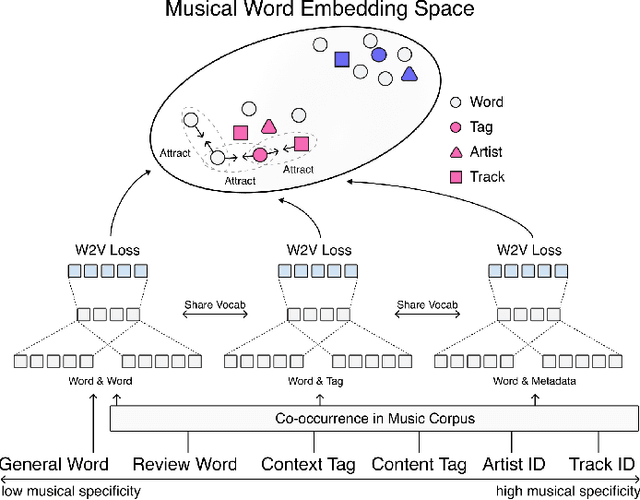
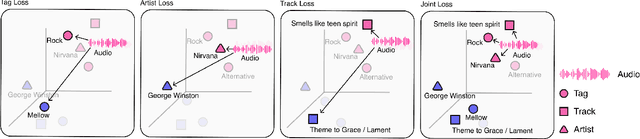
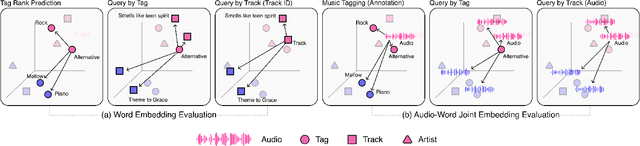
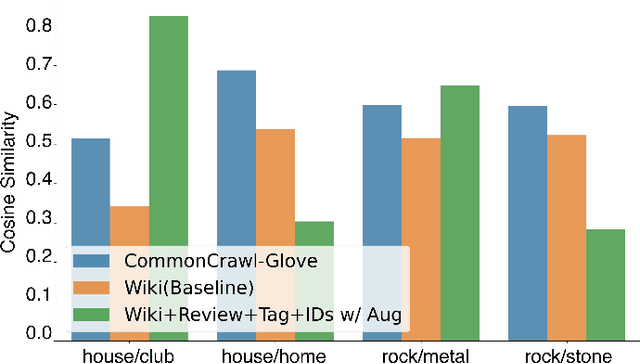
Word embedding has become an essential means for text-based information retrieval. Typically, word embeddings are learned from large quantities of general and unstructured text data. However, in the domain of music, the word embedding may have difficulty understanding musical contexts or recognizing music-related entities like artists and tracks. To address this issue, we propose a new approach called Musical Word Embedding (MWE), which involves learning from various types of texts, including both everyday and music-related vocabulary. We integrate MWE into an audio-word joint representation framework for tagging and retrieving music, using words like tag, artist, and track that have different levels of musical specificity. Our experiments show that using a more specific musical word like track results in better retrieval performance, while using a less specific term like tag leads to better tagging performance. To balance this compromise, we suggest multi-prototype training that uses words with different levels of musical specificity jointly. We evaluate both word embedding and audio-word joint embedding on four tasks (tag rank prediction, music tagging, query-by-tag, and query-by-track) across two datasets (Million Song Dataset and MTG-Jamendo). Our findings show that the suggested MWE is more efficient and robust than the conventional word embedding.
RP1M: A Large-Scale Motion Dataset for Piano Playing with Bi-Manual Dexterous Robot Hands
Aug 20, 2024



It has been a long-standing research goal to endow robot hands with human-level dexterity. Bi-manual robot piano playing constitutes a task that combines challenges from dynamic tasks, such as generating fast while precise motions, with slower but contact-rich manipulation problems. Although reinforcement learning based approaches have shown promising results in single-task performance, these methods struggle in a multi-song setting. Our work aims to close this gap and, thereby, enable imitation learning approaches for robot piano playing at scale. To this end, we introduce the Robot Piano 1 Million (RP1M) dataset, containing bi-manual robot piano playing motion data of more than one million trajectories. We formulate finger placements as an optimal transport problem, thus, enabling automatic annotation of vast amounts of unlabeled songs. Benchmarking existing imitation learning approaches shows that such approaches reach state-of-the-art robot piano playing performance by leveraging RP1M.
The Biased Journey of MSD_AUDIO.ZIP
Sep 02, 2023The equitable distribution of academic data is crucial for ensuring equal research opportunities, and ultimately further progress. Yet, due to the complexity of using the API for audio data that corresponds to the Million Song Dataset along with its misreporting (before 2016) and the discontinuation of this API (after 2016), access to this data has become restricted to those within certain affiliations that are connected peer-to-peer. In this paper, we delve into this issue, drawing insights from the experiences of 22 individuals who either attempted to access the data or played a role in its creation. With this, we hope to initiate more critical dialogue and more thoughtful consideration with regard to access privilege in the MIR community.