 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysicalAgent: Towards General Cognitive Robotics with Foundation World Models
Sep 17, 2025



We introduce PhysicalAgent, an agentic framework for robotic manipulation that integrates iterative reasoning, diffusion-based video generation, and closed-loop execution. Given a textual instruction, our method generates short video demonstrations of candidate trajectories, executes them on the robot, and iteratively re-plans in response to failures. This approach enables robust recovery from execution errors. We evaluate PhysicalAgent across multiple perceptual modalities (egocentric, third-person, and simulated) and robotic embodiments (bimanual UR3, Unitree G1 humanoid, simulated GR1), comparing against state-of-the-art task-specific baselines. Experiments demonstrate that our method consistently outperforms prior approaches, achieving up to 83% success on human-familiar tasks. Physical trials reveal that first-attempt success is limited (20-30%), yet iterative correction increases overall success to 80% across platforms. These results highlight the potential of video-based generative reasoning for general-purpose robotic manipulation and underscore the importance of iterative execution for recovering from initial failures. Our framework paves the way for scalable, adaptable, and robust robot control.
Industry 6.0: New Generation of Industry driven by Generative AI and Swarm of Heterogeneous Robots
Sep 16, 2024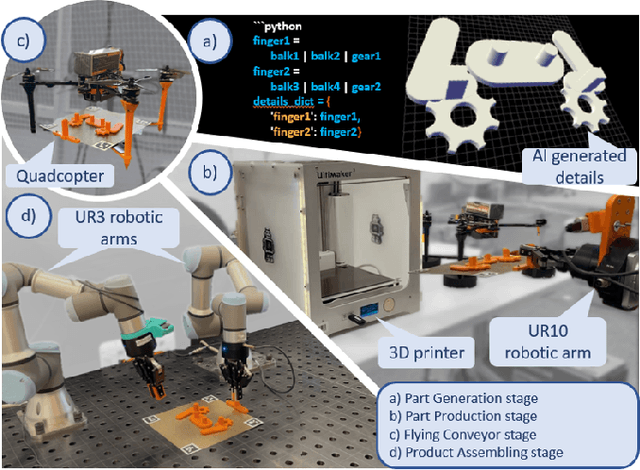
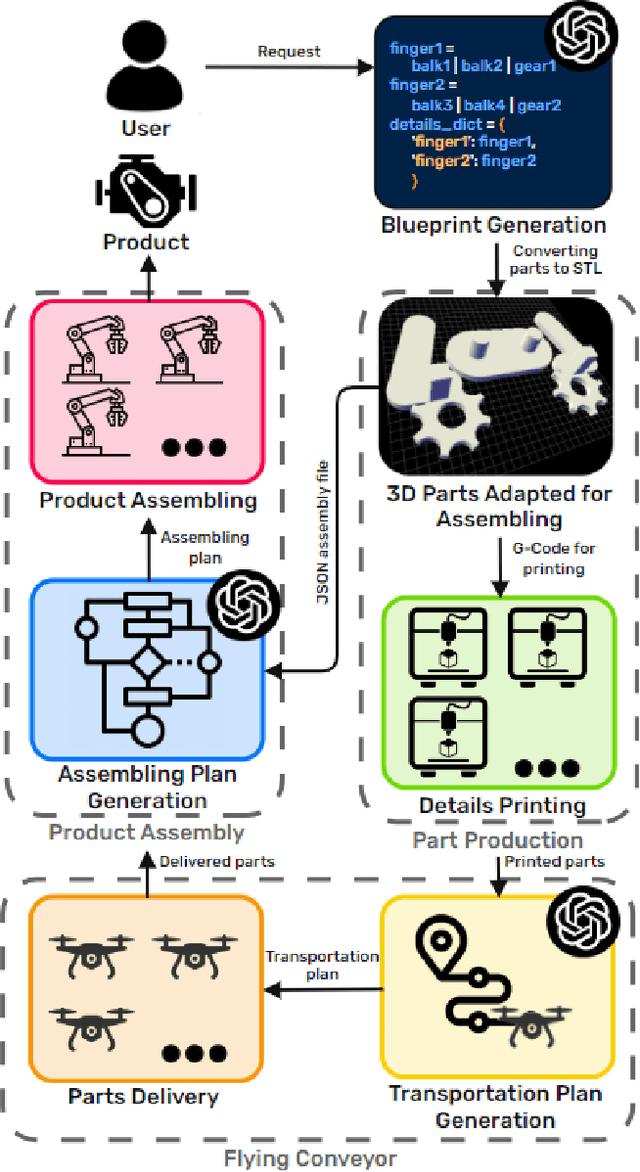


This paper presents the concept of Industry 6.0, introducing the world's first fully automated production system that autonomously handles the entire product design and manufacturing process based on user-provided natural language descriptions. By leveraging generative AI, the system automates critical aspects of production, including product blueprint design, component manufacturing, logistics, and assembly. A heterogeneous swarm of robots, each equipped with individual AI through integration with Large Language Models (LLMs), orchestrates the production process. The robotic system includes manipulator arms, delivery drones, and 3D printers capable of generating assembly blueprints. The system was evaluated using commercial and open-source LLMs, functioning through APIs and local deployment. A user study demonstrated that the system reduces the average production time to 119.10 minutes, significantly outperforming a team of expert human developers, who averaged 528.64 minutes (an improvement factor of 4.4). Furthermore, in the product blueprinting stage, the system surpassed human CAD operators by an unprecedented factor of 47, completing the task in 0.5 minutes compared to 23.5 minutes. This breakthrough represents a major leap towards fully autonomous manufacturing.
VR-GPT: Visual Language Model for Intelligent Virtual Reality Applications
May 19, 2024The advent of immersive Virtual Reality applications has transformed various domains, yet their integration with advanced artificial intelligence technologies like Visual Language Models remains underexplored. This study introduces a pioneering approach utilizing VLMs within VR environments to enhance user interaction and task efficiency. Leveraging the Unity engine and a custom-developed VLM, our system facilitates real-time, intuitive user interactions through natural language processing, without relying on visual text instructions. The incorporation of speech-to-text and text-to-speech technologies allows for seamless communication between the user and the VLM, enabling the system to guide users through complex tasks effectively. Preliminary experimental results indicate that utilizing VLMs not only reduces task completion times but also improves user comfort and task engagement compared to traditional VR interaction methods.
FlockGPT: Guiding UAV Flocking with Linguistic Orchestration
May 09, 2024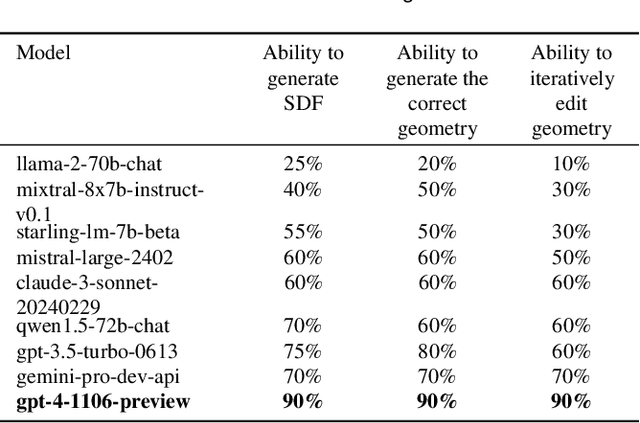
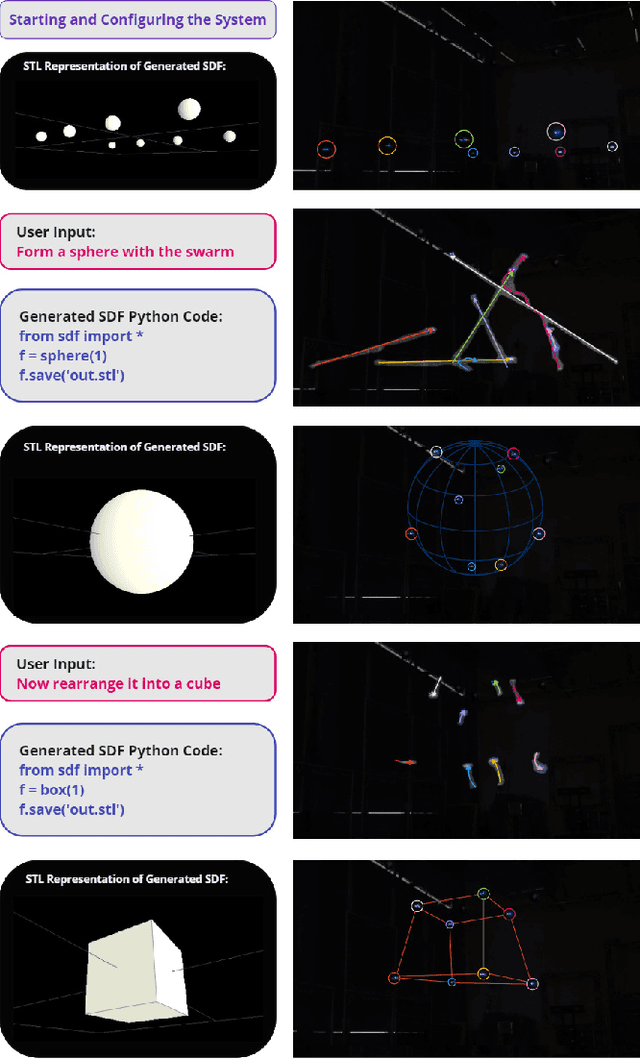
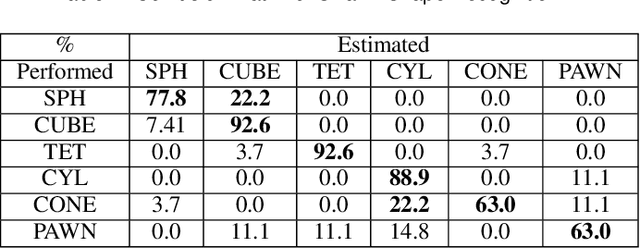
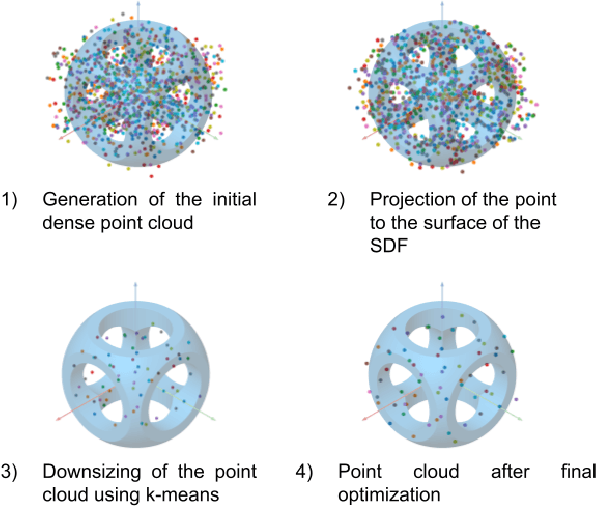
This article presents the world's first rapid drone flocking control using natural language through generative AI. The described approach enables the intuitive orchestration of a flock of any size to achieve the desired geometry. The key feature of the method is the development of a new interface based on Large Language Models to communicate with the user and to generate the target geometry descriptions. Users can interactively modify or provide comments during the construction of the flock geometry model. By combining flocking technology and defining the target surface using a signed distance function, smooth and adaptive movement of the drone swarm between target states is achieved. Our user study on FlockGPT confirmed a high level of intuitive control over drone flocking by users. Subjects who had never previously controlled a swarm of drones were able to construct complex figures in just a few iterations and were able to accurately distinguish the formed swarm drone figures. The results revealed a high recognition rate for six different geometric patterns generated through the LLM-based interface and performed by a simulated drone flock (mean of 80% with a maximum of 93\% for cube and tetrahedron patterns). Users commented on low temporal demand (19.2 score in NASA-TLX), high performance (26 score in NASA-TLX), attractiveness (1.94 UEQ score), and hedonic quality (1.81 UEQ score) of the developed system. The FlockGPT demo code repository can be found at: coming soon
Co-driver: VLM-based Autonomous Driving Assistant with Human-like Behavior and Understanding for Complex Road Scenes
May 09, 2024



Recent research about Large Language Model based autonomous driving solutions shows a promising picture in planning and control fields. However, heavy computational resources and hallucinations of Large Language Models continue to hinder the tasks of predicting precise trajectories and instructing control signals. To address this problem, we propose Co-driver, a novel autonomous driving assistant system to empower autonomous vehicles with adjustable driving behaviors based on the understanding of road scenes. A pipeline involving the CARLA simulator and Robot Operating System 2 (ROS2) verifying the effectiveness of our system is presented, utilizing a single Nvidia 4090 24G GPU while exploiting the capacity of textual output of the Visual Language Model. Besides, we also contribute a dataset containing an image set and a corresponding prompt set for fine-tuning the Visual Language Model module of our system. In the real-world driving dataset, our system achieved 96.16% success rate in night scenes and 89.7% in gloomy scenes regarding reasonable predictions. Our Co-driver dataset will be released at https://github.com/ZionGo6/Co-driver.
HawkDrive: A Transformer-driven Visual Perception System for Autonomous Driving in Night Scene
Apr 06, 2024



Many established vision perception systems for autonomous driving scenarios ignore the influence of light conditions, one of the key elements for driving safety. To address this problem, we present HawkDrive, a novel perception system with hardware and software solutions. Hardware that utilizes stereo vision perception, which has been demonstrated to be a more reliable way of estimating depth information than monocular vision, is partnered with the edge computing device Nvidia Jetson Xavier AGX. Our software for low light enhancement, depth estimation, and semantic segmentation tasks, is a transformer-based neural network. Our software stack, which enables fast inference and noise reduction, is packaged into system modules in Robot Operating System 2 (ROS2). Our experimental results have shown that the proposed end-to-end system is effective in improving the depth estimation and semantic segmentation performance. Our dataset and codes will be released at https://github.com/ZionGo6/HawkDrive.
CognitiveOS: Large Multimodal Model based System to Endow Any Type of Robot with Generative AI
Jan 29, 2024



This paper introduces CognitiveOS, a disruptive system based on multiple transformer-based models, endowing robots of various types with cognitive abilities not only for communication with humans but also for task resolution through physical interaction with the environment. The system operates smoothly on different robotic platforms without extra tuning. It autonomously makes decisions for task execution by analyzing the environment and using information from its long-term memory. The system underwent testing on various platforms, including quadruped robots and manipulator robots, showcasing its capability to formulate behavioral plans even for robots whose behavioral examples were absent in the training dataset. Experimental results revealed the system's high performance in advanced task comprehension and adaptability, emphasizing its potential for real-world applications. The chapters of this paper describe the key components of the system and the dataset structure. The dataset for fine-tuning step generation model is provided at the following link: link coming soon
CognitiveDog: Large Multimodal Model Based System to Translate Vision and Language into Action of Quadruped Robot
Jan 17, 2024



This paper introduces CognitiveDog, a pioneering development of quadruped robot with Large Multi-modal Model (LMM) that is capable of not only communicating with humans verbally but also physically interacting with the environment through object manipulation. The system was realized on Unitree Go1 robot-dog equipped with a custom gripper and demonstrated autonomous decision-making capabilities, independently determining the most appropriate actions and interactions with various objects to fulfill user-defined tasks. These tasks do not necessarily include direct instructions, challenging the robot to comprehend and execute them based on natural language input and environmental cues. The paper delves into the intricacies of this system, dataset characteristics, and the software architecture. Key to this development is the robot's proficiency in navigating space using Visual-SLAM, effectively manipulating and transporting objects, and providing insightful natural language commentary during task execution. Experimental results highlight the robot's advanced task comprehension and adaptability, underscoring its potential in real-world applications. The dataset used to fine-tune the robot-dog behavior generation model is provided at the following link: huggingface.co/datasets/ArtemLykov/CognitiveDog_dataset
AirTouch: Towards Safe Human-Robot Interaction Using Air Pressure Feedback and IR Mocap System
Jul 31, 2023



The growing use of robots in urban environments has raised concerns about potential safety hazards, especially in public spaces where humans and robots may interact. In this paper, we present a system for safe human-robot interaction that combines an infrared (IR) camera with a wearable marker and airflow potential field. IR cameras enable real-time detection and tracking of humans in challenging environments, while controlled airflow creates a physical barrier that guides humans away from dangerous proximity to robots without the need for wearable devices. A preliminary experiment was conducted to measure the accuracy of the perception of safety barriers rendered by controlled air pressure. In a second experiment, we evaluated our approach in an imitation scenario of an interaction between an inattentive person and an autonomous robotic system. Experimental results show that the proposed system significantly improves a participant's ability to maintain a safe distance from the operating robot compared to trials without the system.