 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAV-CodeAgents: Scalable UAV Mission Planning via Multi-Agent ReAct and Vision-Language Reasoning
May 12, 2025



We present UAV-CodeAgents, a scalable multi-agent framework for autonomous UAV mission generation, built on large language and vision-language models (LLMs/VLMs). The system leverages the ReAct (Reason + Act) paradigm to interpret satellite imagery, ground high-level natural language instructions, and collaboratively generate UAV trajectories with minimal human supervision. A core component is a vision-grounded, pixel-pointing mechanism that enables precise localization of semantic targets on aerial maps. To support real-time adaptability, we introduce a reactive thinking loop, allowing agents to iteratively reflect on observations, revise mission goals, and coordinate dynamically in evolving environments. UAV-CodeAgents is evaluated on large-scale mission scenarios involving industrial and environmental fire detection. Our results show that a lower decoding temperature (0.5) yields higher planning reliability and reduced execution time, with an average mission creation time of 96.96 seconds and a success rate of 93%. We further fine-tune Qwen2.5VL-7B on 9,000 annotated satellite images, achieving strong spatial grounding across diverse visual categories. To foster reproducibility and future research, we will release the full codebase and a novel benchmark dataset for vision-language-based UAV planning.
MorphoNavi: Aerial-Ground Robot Navigation with Object Oriented Mapping in Digital Twin
Apr 23, 2025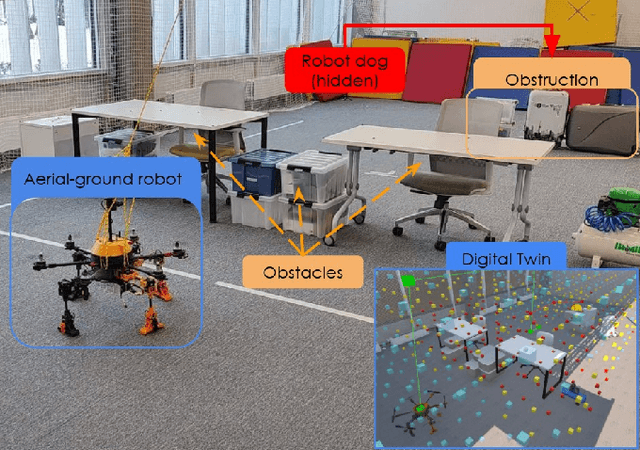


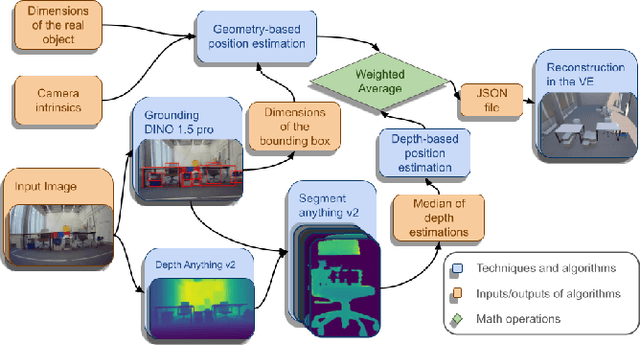
This paper presents a novel mapping approach for a universal aerial-ground robotic system utilizing a single monocular camera. The proposed system is capable of detecting a diverse range of objects and estimating their positions without requiring fine-tuning for specific environments. The system's performance was evaluated through a simulated search-and-rescue scenario, where the MorphoGear robot successfully located a robotic dog while an operator monitored the process. This work contributes to the development of intelligent, multimodal robotic systems capable of operating in unstructured environments.
RaceVLA: VLA-based Racing Drone Navigation with Human-like Behaviour
Mar 04, 2025


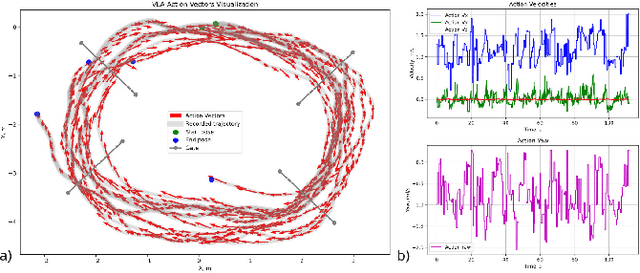
RaceVLA presents an innovative approach for autonomous racing drone navigation by leveraging Visual-Language-Action (VLA) to emulate human-like behavior. This research explores the integration of advanced algorithms that enable drones to adapt their navigation strategies based on real-time environmental feedback, mimicking the decision-making processes of human pilots. The model, fine-tuned on a collected racing drone dataset, demonstrates strong generalization despite the complexity of drone racing environments. RaceVLA outperforms OpenVLA in motion (75.0 vs 60.0) and semantic generalization (45.5 vs 36.3), benefiting from the dynamic camera and simplified motion tasks. However, visual (79.6 vs 87.0) and physical (50.0 vs 76.7) generalization were slightly reduced due to the challenges of maneuvering in dynamic environments with varying object sizes. RaceVLA also outperforms RT-2 across all axes - visual (79.6 vs 52.0), motion (75.0 vs 55.0), physical (50.0 vs 26.7), and semantic (45.5 vs 38.8), demonstrating its robustness for real-time adjustments in complex environments. Experiments revealed an average velocity of 1.04 m/s, with a maximum speed of 2.02 m/s, and consistent maneuverability, demonstrating RaceVLA's ability to handle high-speed scenarios effectively. These findings highlight the potential of RaceVLA for high-performance navigation in competitive racing contexts. The RaceVLA codebase, pretrained weights, and dataset are available at this http URL: https://racevla.github.io/
UAV-VLRR: Vision-Language Informed NMPC for Rapid Response in UAV Search and Rescue
Mar 04, 2025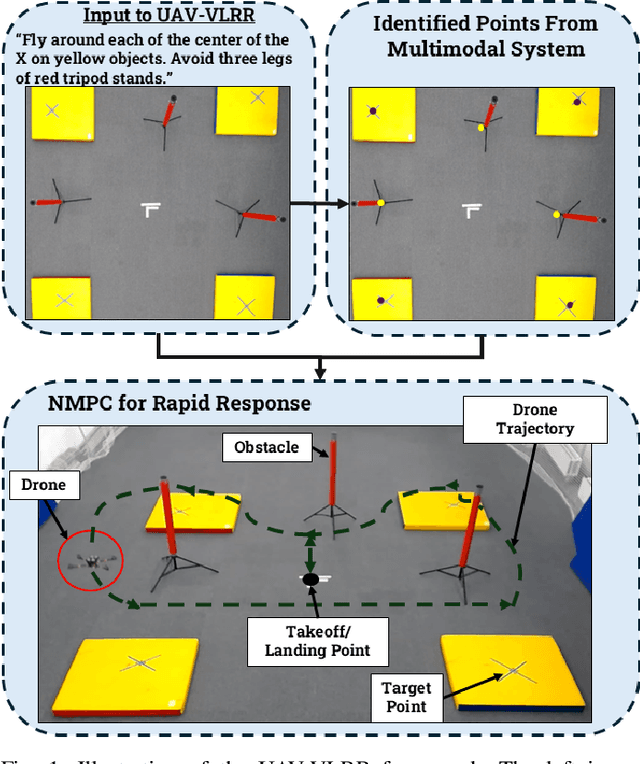
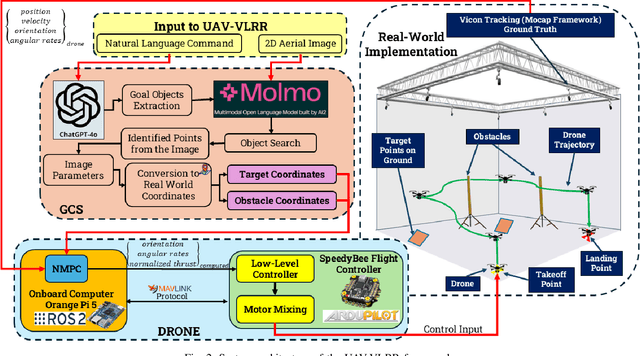
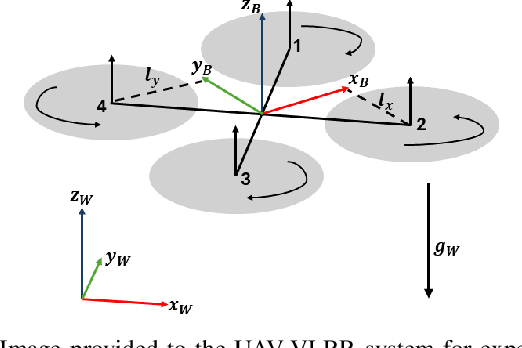
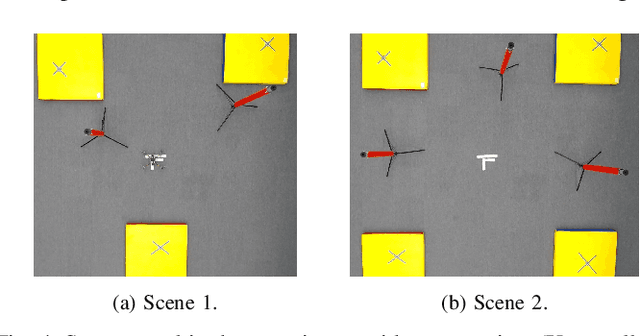
Emergency search and rescue (SAR) operations often require rapid and precise target identification in complex environments where traditional manual drone control is inefficient. In order to address these scenarios, a rapid SAR system, UAV-VLRR (Vision-Language-Rapid-Response), is developed in this research. This system consists of two aspects: 1) A multimodal system which harnesses the power of Visual Language Model (VLM) and the natural language processing capabilities of ChatGPT-4o (LLM) for scene interpretation. 2) A non-linearmodel predictive control (NMPC) with built-in obstacle avoidance for rapid response by a drone to fly according to the output of the multimodal system. This work aims at improving response times in emergency SAR operations by providing a more intuitive and natural approach to the operator to plan the SAR mission while allowing the drone to carry out that mission in a rapid and safe manner. When tested, our approach was faster on an average by 33.75% when compared with an off-the-shelf autopilot and 54.6% when compared with a human pilot. Video of UAV-VLRR: https://youtu.be/KJqQGKKt1xY
UAV-VLPA*: A Vision-Language-Path-Action System for Optimal Route Generation on a Large Scales
Mar 04, 2025The UAV-VLPA* (Visual-Language-Planning-and-Action) system represents a cutting-edge advancement in aerial robotics, designed to enhance communication and operational efficiency for unmanned aerial vehicles (UAVs). By integrating advanced planning capabilities, the system addresses the Traveling Salesman Problem (TSP) to optimize flight paths, reducing the total trajectory length by 18.5\% compared to traditional methods. Additionally, the incorporation of the A* algorithm enables robust obstacle avoidance, ensuring safe and efficient navigation in complex environments. The system leverages satellite imagery processing combined with the Visual Language Model (VLM) and GPT's natural language processing capabilities, allowing users to generate detailed flight plans through simple text commands. This seamless fusion of visual and linguistic analysis empowers precise decision-making and mission planning, making UAV-VLPA* a transformative tool for modern aerial operations. With its unmatched operational efficiency, navigational safety, and user-friendly functionality, UAV-VLPA* sets a new standard in autonomous aerial robotics, paving the way for future innovations in the field.
CognitiveDrone: A VLA Model and Evaluation Benchmark for Real-Time Cognitive Task Solving and Reasoning in UAVs
Mar 03, 2025This paper introduces CognitiveDrone, a novel Vision-Language-Action (VLA) model tailored for complex Unmanned Aerial Vehicles (UAVs) tasks that demand advanced cognitive abilities. Trained on a dataset comprising over 8,000 simulated flight trajectories across three key categories-Human Recognition, Symbol Understanding, and Reasoning-the model generates real-time 4D action commands based on first-person visual inputs and textual instructions. To further enhance performance in intricate scenarios, we propose CognitiveDrone-R1, which integrates an additional Vision-Language Model (VLM) reasoning module to simplify task directives prior to high-frequency control. Experimental evaluations using our open-source benchmark, CognitiveDroneBench, reveal that while a racing-oriented model (RaceVLA) achieves an overall success rate of 31.3%, the base CognitiveDrone model reaches 59.6%, and CognitiveDrone-R1 attains a success rate of 77.2%. These results demonstrate improvements of up to 30% in critical cognitive tasks, underscoring the effectiveness of incorporating advanced reasoning capabilities into UAV control systems. Our contributions include the development of a state-of-the-art VLA model for UAV control and the introduction of the first dedicated benchmark for assessing cognitive tasks in drone operations. The complete repository is available at cognitivedrone.github.io
SafeSwarm: Decentralized Safe RL for the Swarm of Drones Landing in Dense Crowds
Jan 13, 2025


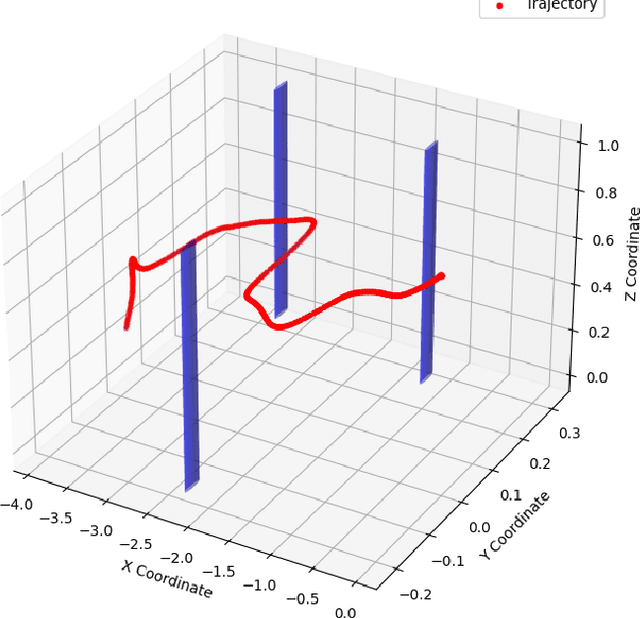
This paper introduces a safe swarm of drones capable of performing landings in crowded environments robustly by relying on Reinforcement Learning techniques combined with Safe Learning. The developed system allows us to teach the swarm of drones with different dynamics to land on moving landing pads in an environment while avoiding collisions with obstacles and between agents. The safe barrier net algorithm was developed and evaluated using a swarm of Crazyflie 2.1 micro quadrotors, which were tested indoors with the Vicon motion capture system to ensure precise localization and control. Experimental results show that our system achieves landing accuracy of 2.25 cm with a mean time of 17 s and collision-free landings, underscoring its effectiveness and robustness in real-world scenarios. This work offers a promising foundation for applications in environments where safety and precision are paramount.
UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation
Jan 09, 2025



The UAV-VLA (Visual-Language-Action) system is a tool designed to facilitate communication with aerial robots. By integrating satellite imagery processing with the Visual Language Model (VLM) and the powerful capabilities of GPT, UAV-VLA enables users to generate general flight paths-and-action plans through simple text requests. This system leverages the rich contextual information provided by satellite images, allowing for enhanced decision-making and mission planning. The combination of visual analysis by VLM and natural language processing by GPT can provide the user with the path-and-action set, making aerial operations more efficient and accessible. The newly developed method showed the difference in the length of the created trajectory in 22% and the mean error in finding the objects of interest on a map in 34.22 m by Euclidean distance in the K-Nearest Neighbors (KNN) approach.
FlightAR: AR Flight Assistance Interface with Multiple Video Streams and Object Detection Aimed at Immersive Drone Control
Oct 22, 2024



The swift advancement of unmanned aerial vehicle (UAV) technologies necessitates new standards for developing human-drone interaction (HDI) interfaces. Most interfaces for HDI, especially first-person view (FPV) goggles, limit the operator's ability to obtain information from the environment. This paper presents a novel interface, FlightAR, that integrates augmented reality (AR) overlays of UAV first-person view (FPV) and bottom camera feeds with head-mounted display (HMD) to enhance the pilot's situational awareness. Using FlightAR, the system provides pilots not only with a video stream from several UAV cameras simultaneously, but also the ability to observe their surroundings in real time. User evaluation with NASA-TLX and UEQ surveys showed low physical demand ($\mu=1.8$, $SD = 0.8$) and good performance ($\mu=3.4$, $SD = 0.8$), proving better user assessments in comparison with baseline FPV goggles. Participants also rated the system highly for stimulation ($\mu=2.35$, $SD = 0.9$), novelty ($\mu=2.1$, $SD = 0.9$) and attractiveness ($\mu=1.97$, $SD = 1$), indicating positive user experiences. These results demonstrate the potential of the system to improve UAV piloting experience through enhanced situational awareness and intuitive control. The code is available here: https://github.com/Sautenich/FlightAR
TiltXter: CNN-based Electro-tactile Rendering of Tilt Angle for Telemanipulation of Pasteur Pipettes
Sep 24, 2024The shape of deformable objects can change drastically during grasping by robotic grippers, causing an ambiguous perception of their alignment and hence resulting in errors in robot positioning and telemanipulation. Rendering clear tactile patterns is fundamental to increasing users' precision and dexterity through tactile haptic feedback during telemanipulation. Therefore, different methods have to be studied to decode the sensors' data into haptic stimuli. This work presents a telemanipulation system for plastic pipettes that consists of a Force Dimension Omega.7 haptic interface endowed with two electro-stimulation arrays and two tactile sensor arrays embedded in the 2-finger Robotiq gripper. We propose a novel approach based on convolutional neural networks (CNN) to detect the tilt of deformable objects. The CNN generates a tactile pattern based on recognized tilt data to render further electro-tactile stimuli provided to the user during the telemanipulation. The study has shown that using the CNN algorithm, tilt recognition by users increased from 23.13\% with the downsized data to 57.9%, and the success rate during teleoperation increased from 53.12% using the downsized data to 92.18% using the tactile patterns generated by the CNN.