 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Diffusion with Distilled Vision-Language Reliability for Aerial Navigation
Jun 11, 2026Autonomous UAV navigation is conventionally solved by pipelines that separate perception, mapping, and planning into distinct stages, which propagates errors, accumulates latency, and requires environment-specific retuning. End-to-end generative models remove these interfaces by mapping raw observations directly to trajectories, but inherit a subtle failure mode: trained on clean data, they cannot recognise when an observation is unreliable, and treat degraded regions such as glass, mirrors, and overexposed surfaces as valid evidence for planning. We present a reliability-aware diffusion planner for 3D UAV navigation. It conditions trajectory generation on the observation together with a scene-level reliability heatmap that marks where perception cannot be trusted, produced by a lightweight network that distils the open-vocabulary reasoning of a vision-language model within the real-time planning budget. To generalise to unseen environments without retraining, we steer the denoising process with a differentiable two-stage ESDF cost that treats physical obstacles from depth and virtual obstacles from highly unreliable regions on equal footing. In simulation and on a real quadrotor, our planner produces markedly safer trajectories than a state-of-the-art diffusion baseline, reducing the obstacle-violation rate from 40.3% to 9.6% and raising the mean reliability of traversed regions from 0.588 to 0.925. Ablating the reliability term alone drops mean reliability from 0.898 to 0.783, confirming it as the decisive component, while distillation runs the framework up to 2 times faster than the full vision-language model.
AgenticDiffusion: Agentic Diffusion-based Path Planning for Vision-Based UAV Navigation
Jun 02, 2026Indoor UAV navigation requires efficient exploration, scene understanding, and reliable trajectory execution under limited field-of-view observations. Existing vision-based navigation frameworks typically rely on single-view observations, limiting their ability to reason about occlusions, target visibility, and global scene structure. In this work, we propose AgenticDiffusion, a multi-view UAV navigation framework that coordinates language-guided reasoning, open-vocabulary target grounding, vision-based diffusion planning, and NMPC within a unified aerial navigation pipeline. Given a natural language instruction and synchronized first-person-view (FPV) and top-view observations, the framework determines the most informative viewpoint for navigation and generates a mission plan prior to trajectory execution. The targets are localized using an open-vocabulary grounding model, after which viewpoint-specific diffusion planners generate navigation trajectories for UAV execution. Using complementary viewpoints, the proposed framework reduces repeated target exploration and improves navigation efficiency in cluttered indoor environments. The framework was validated in four real-world UAV navigation scenarios involving adaptive viewpoint selection, multi-stage mission execution, long-horizon navigation, and safe landing-site selection. The experimental results demonstrated an overall mission success rate of 80% in 40 real-world trials, while the diffusion planners achieved a trajectory generation success rate of 100%.
DiffusionCinema: Text-to-Aerial Cinematography
Jan 24, 2026We propose a novel Unmanned Aerial Vehicles (UAV) assisted creative capture system that leverages diffusion models to interpret high-level natural language prompts and automatically generate optimal flight trajectories for cinematic video recording. Instead of manually piloting the drone, the user simply describes the desired shot (e.g., "orbit around me slowly from the right and reveal the background waterfall"). Our system encodes the prompt along with an initial visual snapshot from the onboard camera, and a diffusion model samples plausible spatio-temporal motion plans that satisfy both the scene geometry and shot semantics. The generated flight trajectory is then executed autonomously by the UAV to record smooth, repeatable video clips that match the prompt. User evaluation using NASA-TLX showed a significantly lower overall workload with our interface (M = 21.6) compared to a traditional remote controller (M = 58.1), demonstrating a substantial reduction in perceived effort. Mental demand (M = 11.5 vs. 60.5) and frustration (M = 14.0 vs. 54.5) were also markedly lower for our system, confirming clear usability advantages in autonomous text-driven flight control. This project demonstrates a new interaction paradigm: text-to-cinema flight, where diffusion models act as the "creative operator" converting story intentions directly into aerial motion.
HumanDiffusion: A Vision-Based Diffusion Trajectory Planner with Human-Conditioned Goals for Search and Rescue UAV
Jan 21, 2026Reliable human--robot collaboration in emergency scenarios requires autonomous systems that can detect humans, infer navigation goals, and operate safely in dynamic environments. This paper presents HumanDiffusion, a lightweight image-conditioned diffusion planner that generates human-aware navigation trajectories directly from RGB imagery. The system combines YOLO-11--based human detection with diffusion-driven trajectory generation, enabling a quadrotor to approach a target person and deliver medical assistance without relying on prior maps or computationally intensive planning pipelines. Trajectories are predicted in pixel space, ensuring smooth motion and a consistent safety margin around humans. We evaluate HumanDiffusion in simulation and real-world indoor mock-disaster scenarios. On a 300-sample test set, the model achieves a mean squared error of 0.02 in pixel-space trajectory reconstruction. Real-world experiments demonstrate an overall mission success rate of 80% across accident-response and search-and-locate tasks with partial occlusions. These results indicate that human-conditioned diffusion planning offers a practical and robust solution for human-aware UAV navigation in time-critical assistance settings.
FlightDiffusion: Revolutionising Autonomous Drone Training with Diffusion Models Generating FPV Video
Sep 19, 2025We present FlightDiffusion, a diffusion-model-based framework for training autonomous drones from first-person view (FPV) video. Our model generates realistic video sequences from a single frame, enriched with corresponding action spaces to enable reasoning-driven navigation in dynamic environments. Beyond direct policy learning, FlightDiffusion leverages its generative capabilities to synthesize diverse FPV trajectories and state-action pairs, facilitating the creation of large-scale training datasets without the high cost of real-world data collection. Our evaluation demonstrates that the generated trajectories are physically plausible and executable, with a mean position error of 0.25 m (RMSE 0.28 m) and a mean orientation error of 0.19 rad (RMSE 0.24 rad). This approach enables improved policy learning and dataset scalability, leading to superior performance in downstream navigation tasks. Results in simulated environments highlight enhanced robustness, smoother trajectory planning, and adaptability to unseen conditions. An ANOVA revealed no statistically significant difference between performance in simulation and reality (F(1, 16) = 0.394, p = 0.541), with success rates of M = 0.628 (SD = 0.162) and M = 0.617 (SD = 0.177), respectively, indicating strong sim-to-real transfer. The generated datasets provide a valuable resource for future UAV research. This work introduces diffusion-based reasoning as a promising paradigm for unifying navigation, action generation, and data synthesis in aerial robotics.
PhysicalAgent: Towards General Cognitive Robotics with Foundation World Models
Sep 17, 2025



We introduce PhysicalAgent, an agentic framework for robotic manipulation that integrates iterative reasoning, diffusion-based video generation, and closed-loop execution. Given a textual instruction, our method generates short video demonstrations of candidate trajectories, executes them on the robot, and iteratively re-plans in response to failures. This approach enables robust recovery from execution errors. We evaluate PhysicalAgent across multiple perceptual modalities (egocentric, third-person, and simulated) and robotic embodiments (bimanual UR3, Unitree G1 humanoid, simulated GR1), comparing against state-of-the-art task-specific baselines. Experiments demonstrate that our method consistently outperforms prior approaches, achieving up to 83% success on human-familiar tasks. Physical trials reveal that first-attempt success is limited (20-30%), yet iterative correction increases overall success to 80% across platforms. These results highlight the potential of video-based generative reasoning for general-purpose robotic manipulation and underscore the importance of iterative execution for recovering from initial failures. Our framework paves the way for scalable, adaptable, and robust robot control.
AttentionSwarm: Reinforcement Learning with Attention Control Barier Function for Crazyflie Drones in Dynamic Environments
Mar 10, 2025We introduce AttentionSwarm, a novel benchmark designed to evaluate safe and efficient swarm control across three challenging environments: a landing environment with obstacles, a competitive drone game setting, and a dynamic drone racing scenario. Central to our approach is the Attention Model Based Control Barrier Function (CBF) framework, which integrates attention mechanisms with safety-critical control theory to enable real-time collision avoidance and trajectory optimization. This framework dynamically prioritizes critical obstacles and agents in the swarms vicinity using attention weights, while CBFs formally guarantee safety by enforcing collision-free constraints. The safe attention net algorithm was developed and evaluated using a swarm of Crazyflie 2.1 micro quadrotors, which were tested indoors with the Vicon motion capture system to ensure precise localization and control. Experimental results show that our system achieves landing accuracy of 3.02 cm with a mean time of 23 s and collision-free landings in a dynamic landing environment, 100% and collision-free navigation in a drone game environment, and 95% and collision-free navigation for a dynamic multiagent drone racing environment, underscoring its effectiveness and robustness in real-world scenarios. This work offers a promising foundation for applications in dynamic environments where safety and fastness are paramount.
RaceVLA: VLA-based Racing Drone Navigation with Human-like Behaviour
Mar 04, 2025


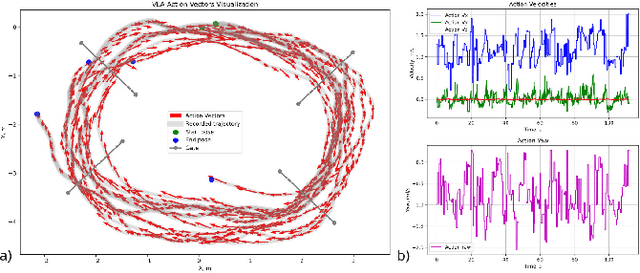
RaceVLA presents an innovative approach for autonomous racing drone navigation by leveraging Visual-Language-Action (VLA) to emulate human-like behavior. This research explores the integration of advanced algorithms that enable drones to adapt their navigation strategies based on real-time environmental feedback, mimicking the decision-making processes of human pilots. The model, fine-tuned on a collected racing drone dataset, demonstrates strong generalization despite the complexity of drone racing environments. RaceVLA outperforms OpenVLA in motion (75.0 vs 60.0) and semantic generalization (45.5 vs 36.3), benefiting from the dynamic camera and simplified motion tasks. However, visual (79.6 vs 87.0) and physical (50.0 vs 76.7) generalization were slightly reduced due to the challenges of maneuvering in dynamic environments with varying object sizes. RaceVLA also outperforms RT-2 across all axes - visual (79.6 vs 52.0), motion (75.0 vs 55.0), physical (50.0 vs 26.7), and semantic (45.5 vs 38.8), demonstrating its robustness for real-time adjustments in complex environments. Experiments revealed an average velocity of 1.04 m/s, with a maximum speed of 2.02 m/s, and consistent maneuverability, demonstrating RaceVLA's ability to handle high-speed scenarios effectively. These findings highlight the potential of RaceVLA for high-performance navigation in competitive racing contexts. The RaceVLA codebase, pretrained weights, and dataset are available at this http URL: https://racevla.github.io/
CognitiveDrone: A VLA Model and Evaluation Benchmark for Real-Time Cognitive Task Solving and Reasoning in UAVs
Mar 03, 2025This paper introduces CognitiveDrone, a novel Vision-Language-Action (VLA) model tailored for complex Unmanned Aerial Vehicles (UAVs) tasks that demand advanced cognitive abilities. Trained on a dataset comprising over 8,000 simulated flight trajectories across three key categories-Human Recognition, Symbol Understanding, and Reasoning-the model generates real-time 4D action commands based on first-person visual inputs and textual instructions. To further enhance performance in intricate scenarios, we propose CognitiveDrone-R1, which integrates an additional Vision-Language Model (VLM) reasoning module to simplify task directives prior to high-frequency control. Experimental evaluations using our open-source benchmark, CognitiveDroneBench, reveal that while a racing-oriented model (RaceVLA) achieves an overall success rate of 31.3%, the base CognitiveDrone model reaches 59.6%, and CognitiveDrone-R1 attains a success rate of 77.2%. These results demonstrate improvements of up to 30% in critical cognitive tasks, underscoring the effectiveness of incorporating advanced reasoning capabilities into UAV control systems. Our contributions include the development of a state-of-the-art VLA model for UAV control and the introduction of the first dedicated benchmark for assessing cognitive tasks in drone operations. The complete repository is available at cognitivedrone.github.io
AgilePilot: DRL-Based Drone Agent for Real-Time Motion Planning in Dynamic Environments by Leveraging Object Detection
Feb 10, 2025Autonomous drone navigation in dynamic environments remains a critical challenge, especially when dealing with unpredictable scenarios including fast-moving objects with rapidly changing goal positions. While traditional planners and classical optimisation methods have been extensively used to address this dynamic problem, they often face real-time, unpredictable changes that ultimately leads to sub-optimal performance in terms of adaptiveness and real-time decision making. In this work, we propose a novel motion planner, AgilePilot, based on Deep Reinforcement Learning (DRL) that is trained in dynamic conditions, coupled with real-time Computer Vision (CV) for object detections during flight. The training-to-deployment framework bridges the Sim2Real gap, leveraging sophisticated reward structures that promotes both safety and agility depending upon environment conditions. The system can rapidly adapt to changing environments, while achieving a maximum speed of 3.0 m/s in real-world scenarios. In comparison, our approach outperforms classical algorithms such as Artificial Potential Field (APF) based motion planner by 3 times, both in performance and tracking accuracy of dynamic targets by using velocity predictions while exhibiting 90% success rate in 75 conducted experiments. This work highlights the effectiveness of DRL in tackling real-time dynamic navigation challenges, offering intelligent safety and agility.