 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpedanceDiffusion: Diffusion-Based Global Path Planning for UAV Swarm Navigation with Generative Impedance Control
Mar 10, 2026Safe swarm navigation in cluttered indoor environment requires long-horizon planning, reactive obstacle avoidance, and adaptive compliance. We propose ImpedanceDiffusion, a hierarchical framework that leverages image-conditioned diffusion-based global path planning with Artificial Potential Field (APF) tracking and semantic-aware variable impedance control for aerial drone swarms. The diffusion model generates geometric global trajectories directly from RGB images without explicit map construction. These trajectories are tracked by an APF-based reactive layer, while a VLM-RAG module performs semantic obstacle classification with 90% retrieval accuracy to adapt impedance parameters for mixed obstacle environments during execution. Two diffusion planners are evaluated: (i) a top-view long-horizon planner using single-pass inference and (ii) a first-person-view (FPV) short-horizon planner deployed via a two-stage inference pipeline. Both planners achieve a 100% trajectory generation rate across twenty static and dynamic experimental configurations and are validated via zero-shot sim-to-real deployment on Crazyflie 2.1 drones through the hierarchical APF-impedance control stack. The top-view planner produces smoother trajectories that yield conservative tracking speeds of 1.0-1.2 m/s near hard obstacles and 0.6-1.0 m/s near soft obstacles. In contrast, the FPV planner generates trajectories with greater local clearance and typically higher speeds, reaching 1.4-2.0 m/s near hard obstacles and up to 1.6 m/s near soft obstacles. Across 20 experimental configurations (100 total runs), the framework achieved a 92% success rate while maintaining stable impedance-based formation control with bounded oscillations and no in-flight collisions, demonstrating reliable and adaptive swarm navigation in cluttered indoor environments.
Glove2UAV: A Wearable IMU-Based Glove for Intuitive Control of UAV
Jan 22, 2026This paper presents Glove2UAV, a wearable IMU-glove interface for intuitive UAV control through hand and finger gestures, augmented with vibrotactile warnings for exceeding predefined speed thresholds. To promote safer and more predictable interaction in dynamic flight, Glove2UAV is designed as a lightweight and easily deployable wearable interface intended for real-time operation. Glove2UAV streams inertial measurements in real time and estimates palm and finger orientations using a compact processing pipeline that combines median-based outlier suppression with Madgwick-based orientation estimation. The resulting motion estimations are mapped to a small set of control primitives for directional flight (forward/backward and lateral motion) and, when supported by the platform, to object-interaction commands. Vibrotactile feedback is triggered when flight speed exceeds predefined threshold values, providing an additional alert channel during operation. We validate real-time feasibility by synchronizing glove signals with UAV telemetry in both simulation and real-world flights. The results show fast gesture-based command execution, stable coupling between gesture dynamics and platform motion, correct operation of the core command set in our trials, and timely delivery of vibratile warning cues.
HoverAI: An Embodied Aerial Agent for Natural Human-Drone Interaction
Jan 20, 2026Drones operating in human-occupied spaces suffer from insufficient communication mechanisms that create uncertainty about their intentions. We present HoverAI, an embodied aerial agent that integrates drone mobility, infrastructure-independent visual projection, and real-time conversational AI into a unified platform. Equipped with a MEMS laser projector, onboard semi-rigid screen, and RGB camera, HoverAI perceives users through vision and voice, responding via lip-synced avatars that adapt appearance to user demographics. The system employs a multimodal pipeline combining VAD, ASR (Whisper), LLM-based intent classification, RAG for dialogue, face analysis for personalization, and voice synthesis (XTTS v2). Evaluation demonstrates high accuracy in command recognition (F1: 0.90), demographic estimation (gender F1: 0.89, age MAE: 5.14 years), and speech transcription (WER: 0.181). By uniting aerial robotics with adaptive conversational AI and self-contained visual output, HoverAI introduces a new class of spatially-aware, socially responsive embodied agents for applications in guidance, assistance, and human-centered interaction.
UAV-CodeAgents: Scalable UAV Mission Planning via Multi-Agent ReAct and Vision-Language Reasoning
May 12, 2025



We present UAV-CodeAgents, a scalable multi-agent framework for autonomous UAV mission generation, built on large language and vision-language models (LLMs/VLMs). The system leverages the ReAct (Reason + Act) paradigm to interpret satellite imagery, ground high-level natural language instructions, and collaboratively generate UAV trajectories with minimal human supervision. A core component is a vision-grounded, pixel-pointing mechanism that enables precise localization of semantic targets on aerial maps. To support real-time adaptability, we introduce a reactive thinking loop, allowing agents to iteratively reflect on observations, revise mission goals, and coordinate dynamically in evolving environments. UAV-CodeAgents is evaluated on large-scale mission scenarios involving industrial and environmental fire detection. Our results show that a lower decoding temperature (0.5) yields higher planning reliability and reduced execution time, with an average mission creation time of 96.96 seconds and a success rate of 93%. We further fine-tune Qwen2.5VL-7B on 9,000 annotated satellite images, achieving strong spatial grounding across diverse visual categories. To foster reproducibility and future research, we will release the full codebase and a novel benchmark dataset for vision-language-based UAV planning.
NMPC-Lander: Nonlinear MPC with Barrier Function for UAV Landing on a Mobile Platform
May 06, 2025Quadcopters are versatile aerial robots gaining popularity in numerous critical applications. However, their operational effectiveness is constrained by limited battery life and restricted flight range. To address these challenges, autonomous drone landing on stationary or mobile charging and battery-swapping stations has become an essential capability. In this study, we present NMPC-Lander, a novel control architecture that integrates Nonlinear Model Predictive Control (NMPC) with Control Barrier Functions (CBF) to achieve precise and safe autonomous landing on both static and dynamic platforms. Our approach employs NMPC for accurate trajectory tracking and landing, while simultaneously incorporating CBF to ensure collision avoidance with static obstacles. Experimental evaluations on the real hardware demonstrate high precision in landing scenarios, with an average final position error of 9.0 cm and 11 cm for stationary and mobile platforms, respectively. Notably, NMPC-Lander outperforms the B-spline combined with the A* planning method by nearly threefold in terms of position tracking, underscoring its superior robustness and practical effectiveness.
UAV-VLPA*: A Vision-Language-Path-Action System for Optimal Route Generation on a Large Scales
Mar 04, 2025The UAV-VLPA* (Visual-Language-Planning-and-Action) system represents a cutting-edge advancement in aerial robotics, designed to enhance communication and operational efficiency for unmanned aerial vehicles (UAVs). By integrating advanced planning capabilities, the system addresses the Traveling Salesman Problem (TSP) to optimize flight paths, reducing the total trajectory length by 18.5\% compared to traditional methods. Additionally, the incorporation of the A* algorithm enables robust obstacle avoidance, ensuring safe and efficient navigation in complex environments. The system leverages satellite imagery processing combined with the Visual Language Model (VLM) and GPT's natural language processing capabilities, allowing users to generate detailed flight plans through simple text commands. This seamless fusion of visual and linguistic analysis empowers precise decision-making and mission planning, making UAV-VLPA* a transformative tool for modern aerial operations. With its unmatched operational efficiency, navigational safety, and user-friendly functionality, UAV-VLPA* sets a new standard in autonomous aerial robotics, paving the way for future innovations in the field.
UAV-VLRR: Vision-Language Informed NMPC for Rapid Response in UAV Search and Rescue
Mar 04, 2025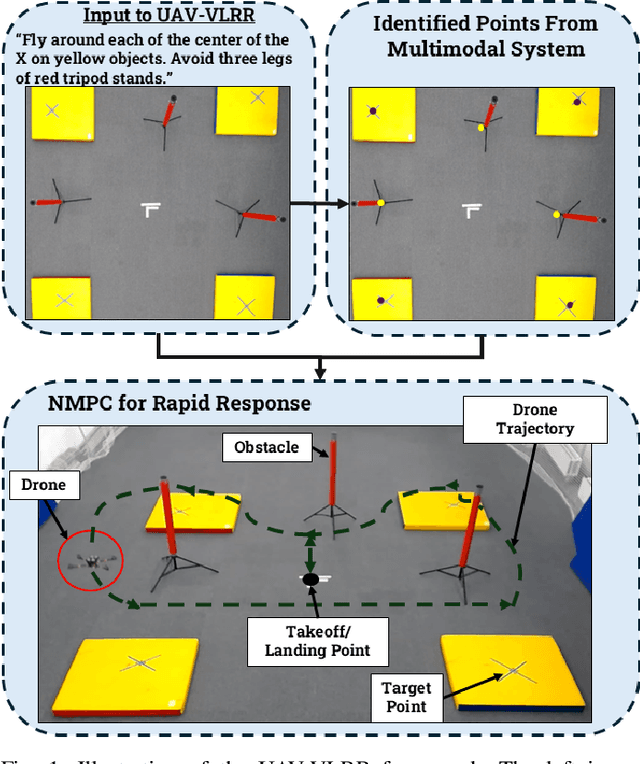
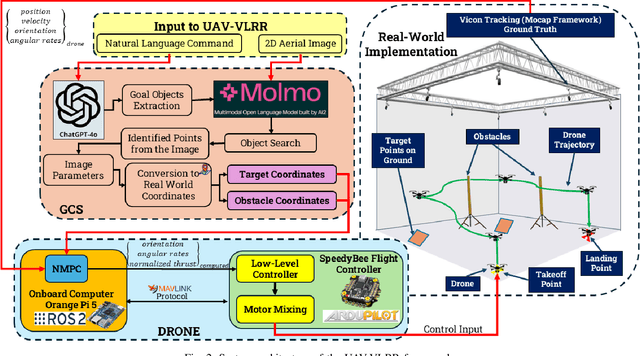
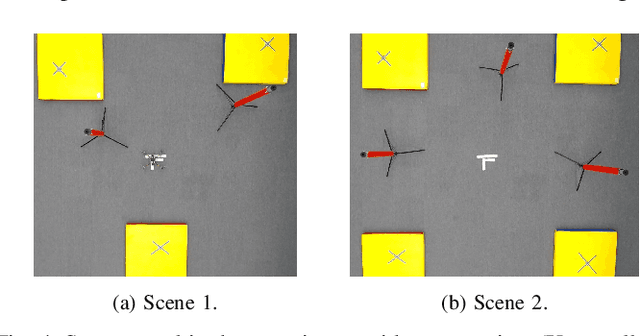
Emergency search and rescue (SAR) operations often require rapid and precise target identification in complex environments where traditional manual drone control is inefficient. In order to address these scenarios, a rapid SAR system, UAV-VLRR (Vision-Language-Rapid-Response), is developed in this research. This system consists of two aspects: 1) A multimodal system which harnesses the power of Visual Language Model (VLM) and the natural language processing capabilities of ChatGPT-4o (LLM) for scene interpretation. 2) A non-linearmodel predictive control (NMPC) with built-in obstacle avoidance for rapid response by a drone to fly according to the output of the multimodal system. This work aims at improving response times in emergency SAR operations by providing a more intuitive and natural approach to the operator to plan the SAR mission while allowing the drone to carry out that mission in a rapid and safe manner. When tested, our approach was faster on an average by 33.75% when compared with an off-the-shelf autopilot and 54.6% when compared with a human pilot. Video of UAV-VLRR: https://youtu.be/KJqQGKKt1xY
UAV-VLA: Vision-Language-Action System for Large Scale Aerial Mission Generation
Jan 09, 2025



The UAV-VLA (Visual-Language-Action) system is a tool designed to facilitate communication with aerial robots. By integrating satellite imagery processing with the Visual Language Model (VLM) and the powerful capabilities of GPT, UAV-VLA enables users to generate general flight paths-and-action plans through simple text requests. This system leverages the rich contextual information provided by satellite images, allowing for enhanced decision-making and mission planning. The combination of visual analysis by VLM and natural language processing by GPT can provide the user with the path-and-action set, making aerial operations more efficient and accessible. The newly developed method showed the difference in the length of the created trajectory in 22% and the mean error in finding the objects of interest on a map in 34.22 m by Euclidean distance in the K-Nearest Neighbors (KNN) approach.
FlightAR: AR Flight Assistance Interface with Multiple Video Streams and Object Detection Aimed at Immersive Drone Control
Oct 22, 2024



The swift advancement of unmanned aerial vehicle (UAV) technologies necessitates new standards for developing human-drone interaction (HDI) interfaces. Most interfaces for HDI, especially first-person view (FPV) goggles, limit the operator's ability to obtain information from the environment. This paper presents a novel interface, FlightAR, that integrates augmented reality (AR) overlays of UAV first-person view (FPV) and bottom camera feeds with head-mounted display (HMD) to enhance the pilot's situational awareness. Using FlightAR, the system provides pilots not only with a video stream from several UAV cameras simultaneously, but also the ability to observe their surroundings in real time. User evaluation with NASA-TLX and UEQ surveys showed low physical demand ($\mu=1.8$, $SD = 0.8$) and good performance ($\mu=3.4$, $SD = 0.8$), proving better user assessments in comparison with baseline FPV goggles. Participants also rated the system highly for stimulation ($\mu=2.35$, $SD = 0.9$), novelty ($\mu=2.1$, $SD = 0.9$) and attractiveness ($\mu=1.97$, $SD = 1$), indicating positive user experiences. These results demonstrate the potential of the system to improve UAV piloting experience through enhanced situational awareness and intuitive control. The code is available here: https://github.com/Sautenich/FlightAR
MorphoMove: Bi-Modal Path Planner with MPC-based Path Follower for Multi-Limb Morphogenetic UAV
Jul 12, 2024



This paper discusses developments for a multi-limb morphogenetic UAV, MorphoGear, that is capable of both aerial flight and ground locomotion. A hybrid path planning algorithm based on A* strategy has been developed enabling seamless transition between air-to-ground navigation modes, thereby enhancing robot's mobility in complex environments. Moreover, precise path following is achieved during ground locomotion with a Model Predictive Control (MPC) architecture for its novel walking behaviour. Experimental validation was conducted in the Unity simulation environment utilizing Python scripts to compute control values. The algorithms' performance is validated by the Root Mean Squared Error (RMSE) of 0.91 cm and a maximum error of 1.85 cm, as demonstrated by the results. These developments highlight the adaptability of MorphoGear in navigation through cluttered environments, establishing it as a usable tool in autonomous exploration, both aerial and ground-based.