 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini 1.5: Unlocking multimodal understanding across millions of tokens of context
Mar 08, 2024In this report, we present the latest model of the Gemini family, Gemini 1.5 Pro, a highly compute-efficient multimodal mixture-of-experts model capable of recalling and reasoning over fine-grained information from millions of tokens of context, including multiple long documents and hours of video and audio. Gemini 1.5 Pro achieves near-perfect recall on long-context retrieval tasks across modalities, improves the state-of-the-art in long-document QA, long-video QA and long-context ASR, and matches or surpasses Gemini 1.0 Ultra's state-of-the-art performance across a broad set of benchmarks. Studying the limits of Gemini 1.5 Pro's long-context ability, we find continued improvement in next-token prediction and near-perfect retrieval (>99%) up to at least 10M tokens, a generational leap over existing models such as Claude 2.1 (200k) and GPT-4 Turbo (128k). Finally, we highlight surprising new capabilities of large language models at the frontier; when given a grammar manual for Kalamang, a language with fewer than 200 speakers worldwide, the model learns to translate English to Kalamang at a similar level to a person who learned from the same content.
Gemini: A Family of Highly Capable Multimodal Models
Dec 19, 2023This report introduces a new family of multimodal models, Gemini, that exhibit remarkable capabilities across image, audio, video, and text understanding. The Gemini family consists of Ultra, Pro, and Nano sizes, suitable for applications ranging from complex reasoning tasks to on-device memory-constrained use-cases. Evaluation on a broad range of benchmarks shows that our most-capable Gemini Ultra model advances the state of the art in 30 of 32 of these benchmarks - notably being the first model to achieve human-expert performance on the well-studied exam benchmark MMLU, and improving the state of the art in every one of the 20 multimodal benchmarks we examined. We believe that the new capabilities of Gemini models in cross-modal reasoning and language understanding will enable a wide variety of use cases and we discuss our approach toward deploying them responsibly to users.
Continuous diffusion for categorical data
Dec 15, 2022



Diffusion models have quickly become the go-to paradigm for generative modelling of perceptual signals (such as images and sound) through iterative refinement. Their success hinges on the fact that the underlying physical phenomena are continuous. For inherently discrete and categorical data such as language, various diffusion-inspired alternatives have been proposed. However, the continuous nature of diffusion models conveys many benefits, and in this work we endeavour to preserve it. We propose CDCD, a framework for modelling categorical data with diffusion models that are continuous both in time and input space. We demonstrate its efficacy on several language modelling tasks.
Inferring a Continuous Distribution of Atom Coordinates from Cryo-EM Images using VAEs
Jun 26, 2021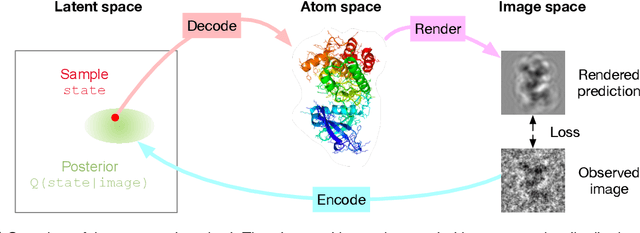
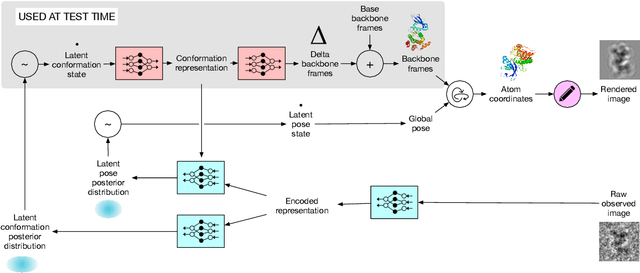
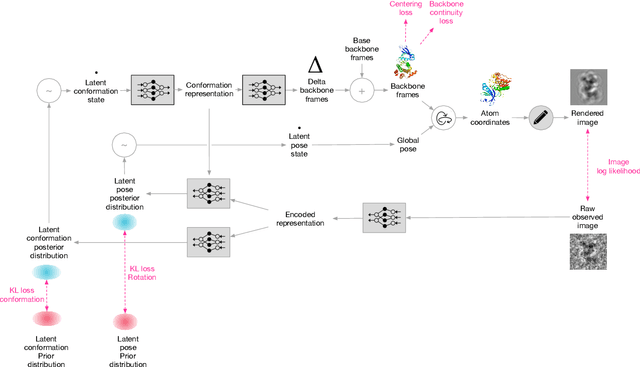
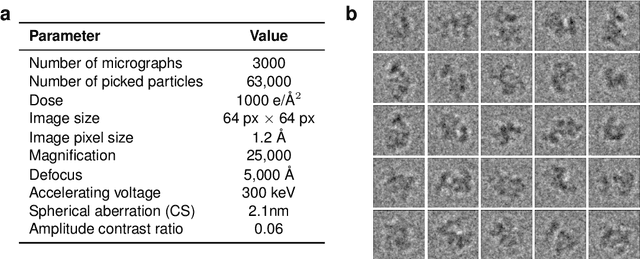
Cryo-electron microscopy (cryo-EM) has revolutionized experimental protein structure determination. Despite advances in high resolution reconstruction, a majority of cryo-EM experiments provide either a single state of the studied macromolecule, or a relatively small number of its conformations. This reduces the effectiveness of the technique for proteins with flexible regions, which are known to play a key role in protein function. Recent methods for capturing conformational heterogeneity in cryo-EM data model it in volume space, making recovery of continuous atomic structures challenging. Here we present a fully deep-learning-based approach using variational auto-encoders (VAEs) to recover a continuous distribution of atomic protein structures and poses directly from picked particle images and demonstrate its efficacy on realistic simulated data. We hope that methods built on this work will allow incorporation of stronger prior information about protein structure and enable better understanding of non-rigid protein structures.
On the unreasonable effectiveness of CNNs
Jul 29, 2020
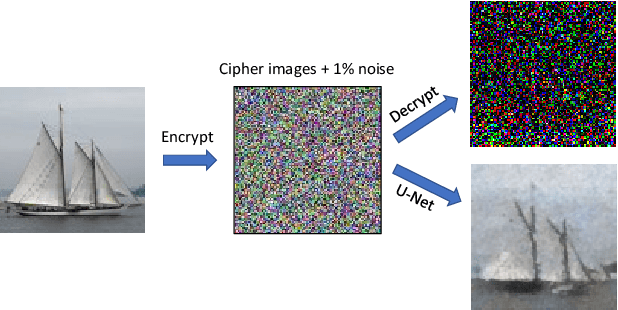

Deep learning methods using convolutional neural networks (CNN) have been successfully applied to virtually all imaging problems, and particularly in image reconstruction tasks with ill-posed and complicated imaging models. In an attempt to put upper bounds on the capability of baseline CNNs for solving image-to-image problems we applied a widely used standard off-the-shelf network architecture (U-Net) to the "inverse problem" of XOR decryption from noisy data and show acceptable results.
Kernel of CycleGAN as a Principle homogeneous space
Jan 24, 2020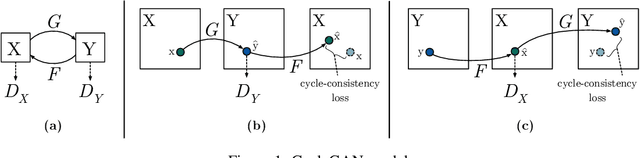


Unpaired image-to-image translation has attracted significant interest due to the invention of CycleGAN, a method which utilizes a combination of adversarial and cycle consistency losses to avoid the need for paired data. It is known that the CycleGAN problem might admit multiple solutions, and our goal in this paper is to analyze the space of exact solutions and to give perturbation bounds for approximate solutions. We show theoretically that the exact solution space is invariant with respect to automorphisms of the underlying probability spaces, and, furthermore, that the group of automorphisms acts freely and transitively on the space of exact solutions. We examine the case of zero `pure' CycleGAN loss first in its generality, and, subsequently, expand our analysis to approximate solutions for `extended' CycleGAN loss where identity loss term is included. In order to demonstrate that these results are applicable, we show that under mild conditions nontrivial smooth automorphisms exist. Furthermore, we provide empirical evidence that neural networks can learn these automorphisms with unexpected and unwanted results. We conclude that finding optimal solutions to the CycleGAN loss does not necessarily lead to the envisioned result in image-to-image translation tasks and that underlying hidden symmetries can render the result utterly useless.
A unified representation network for segmentation with missing modalities
Aug 19, 2019
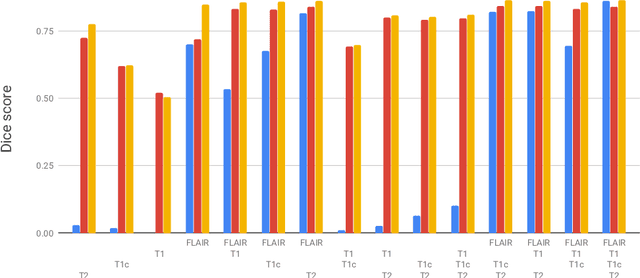
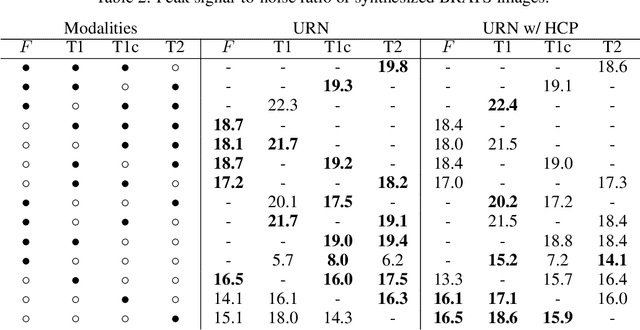
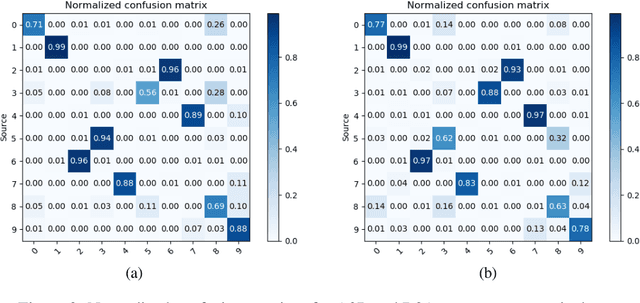
Over the last few years machine learning has demonstrated groundbreaking results in many areas of medical image analysis, including segmentation. A key assumption, however, is that the train- and test distributions match. We study a realistic scenario where this assumption is clearly violated, namely segmentation with missing input modalities. We describe two neural network approaches that can handle a variable number of input modalities. The first is modality dropout: a simple but surprisingly effective modification of the training. The second is the unified representation network: a network architecture that maps a variable number of input modalities into a unified representation that can be used for downstream tasks such as segmentation. We demonstrate that modality dropout makes a standard segmentation network reasonably robust to missing modalities, but that the same network works even better if trained on the unified representation.
Multi-Scale Learned Iterative Reconstruction
Aug 01, 2019



Model-based learned iterative reconstruction methods have recently been shown to outperform classical reconstruction methods. Applicability of these methods to large scale inverse problems is however limited by the available memory for training and extensive training times. As a possible solution to these restrictions we propose a multi-scale learned iterative reconstruction algorithm that computes iterates on discretisations of increasing resolution. This procedure does not only reduce memory requirements, it also considerably speeds up reconstruction and training times, but most importantly is scalable to large scale inverse problems, like those that arise in 3D tomographic imaging. Feasibility of the proposed method to speed up training and computation times in comparison to established learned reconstruction methods in 2D is demonstrated for low dose computed tomography (CT), for which we utilise the data base of abdominal CT scans provided for the 2016 AAPM low-dose CT grand challenge.
Deep Bayesian Inversion
Nov 14, 2018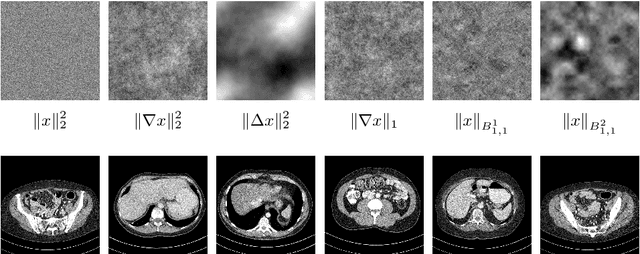


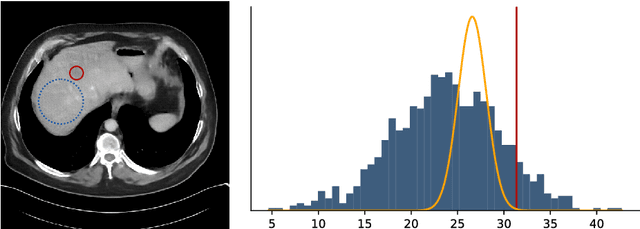
Characterizing statistical properties of solutions of inverse problems is essential for decision making. Bayesian inversion offers a tractable framework for this purpose, but current approaches are computationally unfeasible for most realistic imaging applications in the clinic. We introduce two novel deep learning based methods for solving large-scale inverse problems using Bayesian inversion: a sampling based method using a WGAN with a novel mini-discriminator and a direct approach that trains a neural network using a novel loss function. The performance of both methods is demonstrated on image reconstruction in ultra low dose 3D helical CT. We compute the posterior mean and standard deviation of the 3D images followed by a hypothesis test to assess whether a "dark spot" in the liver of a cancer stricken patient is present. Both methods are computationally efficient and our evaluation shows very promising performance that clearly supports the claim that Bayesian inversion is usable for 3D imaging in time critical applications.
Task adapted reconstruction for inverse problems
Aug 27, 2018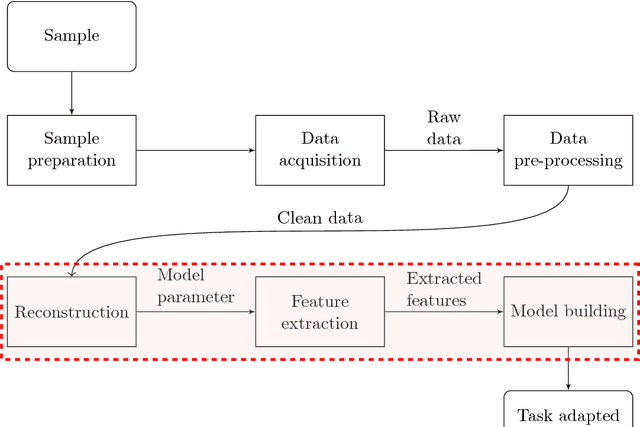
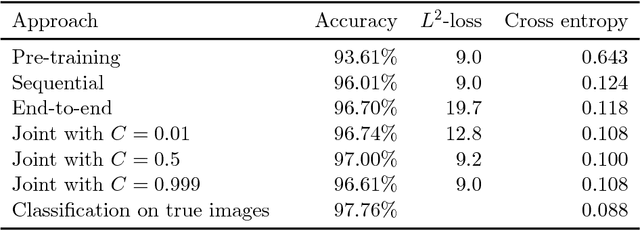
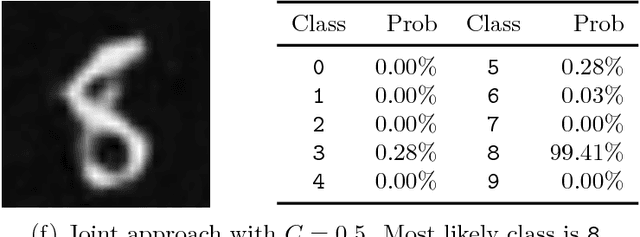
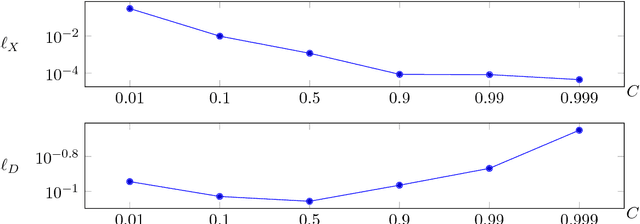
The paper considers the problem of performing a task defined on a model parameter that is only observed indirectly through noisy data in an ill-posed inverse problem. A key aspect is to formalize the steps of reconstruction and task as appropriate estimators (non-randomized decision rules) in statistical estimation problems. The implementation makes use of (deep) neural networks to provide a differentiable parametrization of the family of estimators for both steps. These networks are combined and jointly trained against suitable supervised training data in order to minimize a joint differentiable loss function, resulting in an end-to-end task adapted reconstruction method. The suggested framework is generic, yet adaptable, with a plug-and-play structure for adjusting both the inverse problem and the task at hand. More precisely, the data model (forward operator and statistical model of the noise) associated with the inverse problem is exchangeable, e.g., by using neural network architecture given by a learned iterative method. Furthermore, any task that is encodable as a trainable neural network can be used. The approach is demonstrated on joint tomographic image reconstruction, classification and joint tomographic image reconstruction segmentation.