 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkeleton Based Action Recognition
Skeleton-based Action Recognition is a computer-vision task that involves recognizing human actions from a sequence of 3D skeletal joint data captured from sensors such as Microsoft Kinect, Intel RealSense, and wearable devices. The goal of skeleton-based action recognition is to develop algorithms that can understand and classify human actions from skeleton data, which can be used in various applications such as human-computer interaction, sports analysis, and surveillance.
Papers and Code
SNN-Driven Multimodal Human Action Recognition via Event Camera and Skeleton Data Fusion
Feb 19, 2025Multimodal human action recognition based on RGB and skeleton data fusion, while effective, is constrained by significant limitations such as high computational complexity, excessive memory consumption, and substantial energy demands, particularly when implemented with Artificial Neural Networks (ANN). These limitations restrict its applicability in resource-constrained scenarios. To address these challenges, we propose a novel Spiking Neural Network (SNN)-driven framework for multimodal human action recognition, utilizing event camera and skeleton data. Our framework is centered on two key innovations: (1) a novel multimodal SNN architecture that employs distinct backbone networks for each modality-an SNN-based Mamba for event camera data and a Spiking Graph Convolutional Network (SGN) for skeleton data-combined with a spiking semantic extraction module to capture deep semantic representations; and (2) a pioneering SNN-based discretized information bottleneck mechanism for modality fusion, which effectively balances the preservation of modality-specific semantics with efficient information compression. To validate our approach, we propose a novel method for constructing a multimodal dataset that integrates event camera and skeleton data, enabling comprehensive evaluation. Extensive experiments demonstrate that our method achieves superior performance in both recognition accuracy and energy efficiency, offering a promising solution for practical applications.
Skeleton-based Action Recognition with Non-linear Dependency Modeling and Hilbert-Schmidt Independence Criterion
Dec 25, 2024



Human skeleton-based action recognition has long been an indispensable aspect of artificial intelligence. Current state-of-the-art methods tend to consider only the dependencies between connected skeletal joints, limiting their ability to capture non-linear dependencies between physically distant joints. Moreover, most existing approaches distinguish action classes by estimating the probability density of motion representations, yet the high-dimensional nature of human motions invokes inherent difficulties in accomplishing such measurements. In this paper, we seek to tackle these challenges from two directions: (1) We propose a novel dependency refinement approach that explicitly models dependencies between any pair of joints, effectively transcending the limitations imposed by joint distance. (2) We further propose a framework that utilizes the Hilbert-Schmidt Independence Criterion to differentiate action classes without being affected by data dimensionality, and mathematically derive learning objectives guaranteeing precise recognition. Empirically, our approach sets the state-of-the-art performance on NTU RGB+D, NTU RGB+D 120, and Northwestern-UCLA datasets.
Synchronized and Fine-Grained Head for Skeleton-Based Ambiguous Action Recognition
Dec 19, 2024



Skeleton-based action recognition using GCNs has achieved remarkable performance, but recognizing ambiguous actions, such as "waving" and "saluting", remains a significant challenge. Existing methods typically rely on a serial combination of GCNs and TCNs, where spatial and temporal features are extracted independently, leading to an unbalanced spatial-temporal information, which hinders accurate action recognition. Moreover, existing methods for ambiguous actions often overemphasize local details, resulting in the loss of crucial global context, which further complicates the task of differentiating ambiguous actions. To address these challenges, we propose a lightweight plug-and-play module called Synchronized and Fine-grained Head (SF-Head), inserted between GCN and TCN layers. SF-Head first conducts Synchronized Spatial-Temporal Extraction (SSTE) with a Feature Redundancy Loss (F-RL), ensuring a balanced interaction between the two types of features. It then performs Adaptive Cross-dimensional Feature Aggregation (AC-FA), with a Feature Consistency Loss (F-CL), which aligns the aggregated feature with their original spatial-temporal feature. This aggregation step effectively combines both global context and local details. Experimental results on NTU RGB+D 60, NTU RGB+D 120, and NW-UCLA datasets demonstrate significant improvements in distinguishing ambiguous actions. Our code will be made available at https://github.com/HaoHuang2003/SFHead.
Revealing Key Details to See Differences: A Novel Prototypical Perspective for Skeleton-based Action Recognition
Nov 28, 2024In skeleton-based action recognition, a key challenge is distinguishing between actions with similar trajectories of joints due to the lack of image-level details in skeletal representations. Recognizing that the differentiation of similar actions relies on subtle motion details in specific body parts, we direct our approach to focus on the fine-grained motion of local skeleton components. To this end, we introduce ProtoGCN, a Graph Convolutional Network (GCN)-based model that breaks down the dynamics of entire skeleton sequences into a combination of learnable prototypes representing core motion patterns of action units. By contrasting the reconstruction of prototypes, ProtoGCN can effectively identify and enhance the discriminative representation of similar actions. Without bells and whistles, ProtoGCN achieves state-of-the-art performance on multiple benchmark datasets, including NTU RGB+D, NTU RGB+D 120, Kinetics-Skeleton, and FineGYM, which demonstrates the effectiveness of the proposed method. The code is available at https://github.com/firework8/ProtoGCN.
FreqMixFormerV2: Lightweight Frequency-aware Mixed Transformer for Human Skeleton Action Recognition
Dec 29, 2024Transformer-based human skeleton action recognition has been developed for years. However, the complexity and high parameter count demands of these models hinder their practical applications, especially in resource-constrained environments. In this work, we propose FreqMixForemrV2, which was built upon the Frequency-aware Mixed Transformer (FreqMixFormer) for identifying subtle and discriminative actions with pioneered frequency-domain analysis. We design a lightweight architecture that maintains robust performance while significantly reducing the model complexity. This is achieved through a redesigned frequency operator that optimizes high-frequency and low-frequency parameter adjustments, and a simplified frequency-aware attention module. These improvements result in a substantial reduction in model parameters, enabling efficient deployment with only a minimal sacrifice in accuracy. Comprehensive evaluations of standard datasets (NTU RGB+D, NTU RGB+D 120, and NW-UCLA datasets) demonstrate that the proposed model achieves a superior balance between efficiency and accuracy, outperforming state-of-the-art methods with only 60% of the parameters.
BlanketGen2-Fit3D: Synthetic Blanket Augmentation Towards Improving Real-World In-Bed Blanket Occluded Human Pose Estimation
Jan 21, 2025



Human Pose Estimation (HPE) from monocular RGB images is crucial for clinical in-bed skeleton-based action recognition, however, it poses unique challenges for HPE models due to the frequent presence of blankets occluding the person, while labeled HPE data in this scenario is scarce. To address this we introduce BlanketGen2-Fit3D (BG2-Fit3D), an augmentation of Fit3D dataset that contains 1,217,312 frames with synthetic photo-realistic blankets. To generate it we used BlanketGen2, our new and improved version of our BlanketGen pipeline that simulates synthetic blankets using ground-truth Skinned Multi-Person Linear model (SMPL) meshes and then renders them as transparent images that can be layered on top of the original frames. This dataset was used in combination with the original Fit3D to finetune the ViTPose-B HPE model, to evaluate synthetic blanket augmentation effectiveness. The trained models were further evaluated on a real-world blanket occluded in-bed HPE dataset (SLP dataset). Comparing architectures trained on only Fit3D with the ones trained with our synthetic blanket augmentation the later improved pose estimation performance on BG2-Fit3D, the synthetic blanket occluded dataset significantly to (0.977 Percentage of Correct Keypoints (PCK), 0.149 Normalized Mean Error (NME)) with an absolute 4.4% PCK increase. Furthermore, the test results on SLP demonstrated the utility of synthetic data augmentation by improving performance by an absolute 2.3% PCK, on real-world images with the poses occluded by real blankets. These results show synthetic blanket augmentation has the potential to improve in-bed blanket occluded HPE from RGB images. The dataset as well as the code will be made available to the public.
Topological Symmetry Enhanced Graph Convolution for Skeleton-Based Action Recognition
Nov 20, 2024
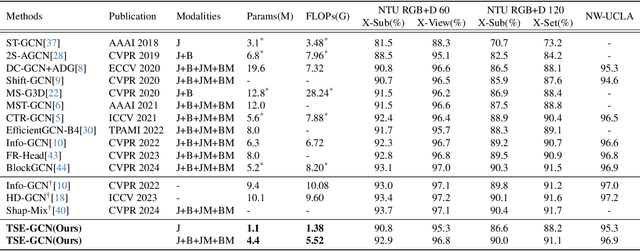

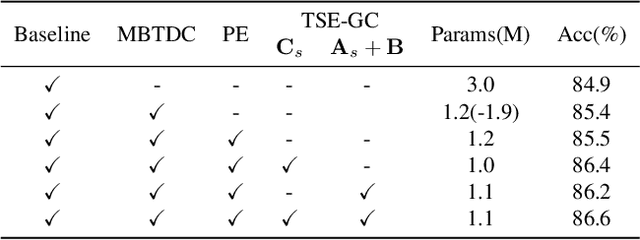
Skeleton-based action recognition has achieved remarkable performance with the development of graph convolutional networks (GCNs). However, most of these methods tend to construct complex topology learning mechanisms while neglecting the inherent symmetry of the human body. Additionally, the use of temporal convolutions with certain fixed receptive fields limits their capacity to effectively capture dependencies in time sequences. To address the issues, we (1) propose a novel Topological Symmetry Enhanced Graph Convolution (TSE-GC) to enable distinct topology learning across different channel partitions while incorporating topological symmetry awareness and (2) construct a Multi-Branch Deformable Temporal Convolution (MBDTC) for skeleton-based action recognition. The proposed TSE-GC emphasizes the inherent symmetry of the human body while enabling efficient learning of dynamic topologies. Meanwhile, the design of MBDTC introduces the concept of deformable modeling, leading to more flexible receptive fields and stronger modeling capacity of temporal dependencies. Combining TSE-GC with MBDTC, our final model, TSE-GCN, achieves competitive performance with fewer parameters compared with state-of-the-art methods on three large datasets, NTU RGB+D, NTU RGB+D 120, and NW-UCLA. On the cross-subject and cross-set evaluations of NTU RGB+D 120, the accuracies of our model reach 90.0\% and 91.1\%, with 1.1M parameters and 1.38 GFLOPS for one stream.
Extended multi-stream temporal-attention module for skeleton-based human action recognition (HAR)
Nov 10, 2024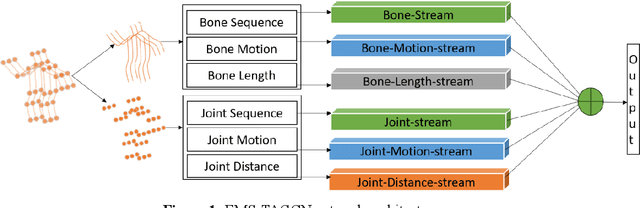
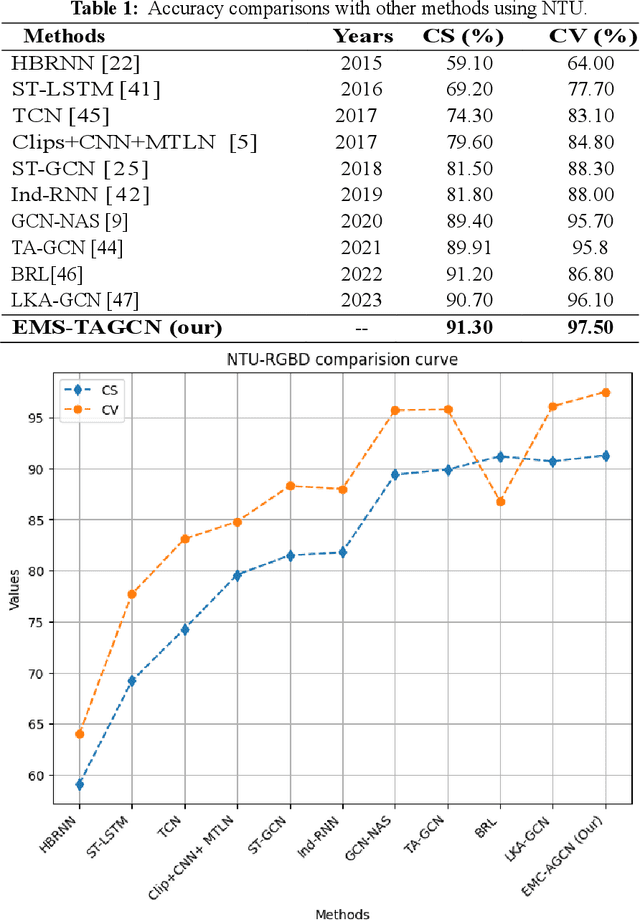
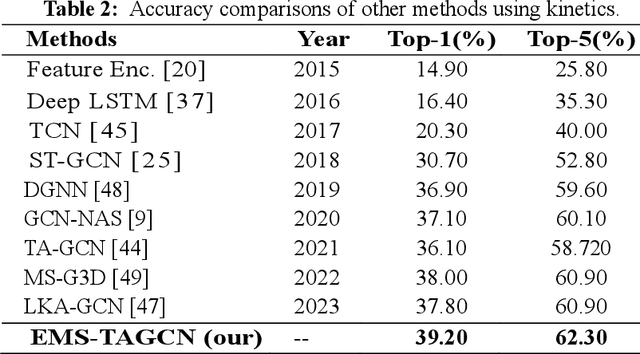
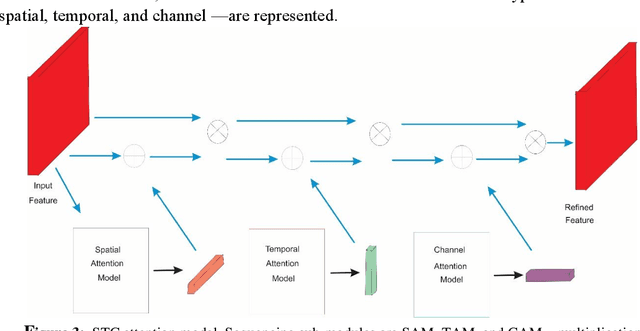
Graph convolutional networks (GCNs) are an effective skeleton-based human action recognition (HAR) technique. GCNs enable the specification of CNNs to a non-Euclidean frame that is more flexible. The previous GCN-based models still have a lot of issues: (I) The graph structure is the same for all model layers and input data.
DSTSA-GCN: Advancing Skeleton-Based Gesture Recognition with Semantic-Aware Spatio-Temporal Topology Modeling
Jan 21, 2025
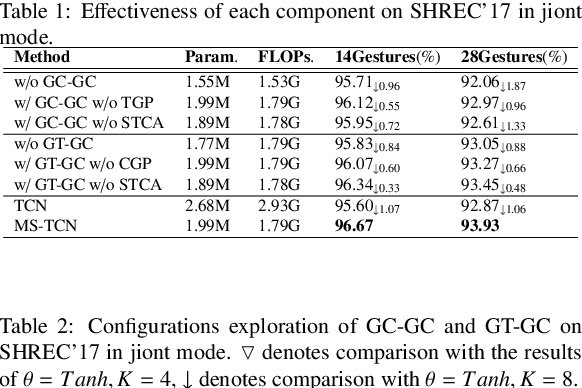


Graph convolutional networks (GCNs) have emerged as a powerful tool for skeleton-based action and gesture recognition, thanks to their ability to model spatial and temporal dependencies in skeleton data. However, existing GCN-based methods face critical limitations: (1) they lack effective spatio-temporal topology modeling that captures dynamic variations in skeletal motion, and (2) they struggle to model multiscale structural relationships beyond local joint connectivity. To address these issues, we propose a novel framework called Dynamic Spatial-Temporal Semantic Awareness Graph Convolutional Network (DSTSA-GCN). DSTSA-GCN introduces three key modules: Group Channel-wise Graph Convolution (GC-GC), Group Temporal-wise Graph Convolution (GT-GC), and Multi-Scale Temporal Convolution (MS-TCN). GC-GC and GT-GC operate in parallel to independently model channel-specific and frame-specific correlations, enabling robust topology learning that accounts for temporal variations. Additionally, both modules employ a grouping strategy to adaptively capture multiscale structural relationships. Complementing this, MS-TCN enhances temporal modeling through group-wise temporal convolutions with diverse receptive fields. Extensive experiments demonstrate that DSTSA-GCN significantly improves the topology modeling capabilities of GCNs, achieving state-of-the-art performance on benchmark datasets for gesture and action recognition, including SHREC17 Track, DHG-14\/28, NTU-RGB+D, and NTU-RGB+D-120.
TDSM: Triplet Diffusion for Skeleton-Text Matching in Zero-Shot Action Recognition
Nov 22, 2024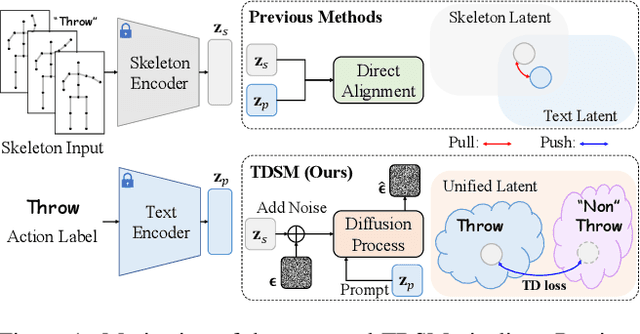
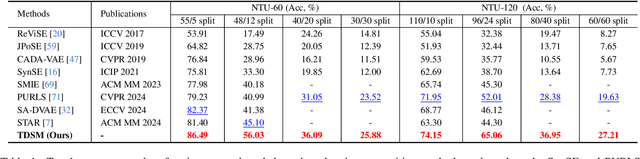
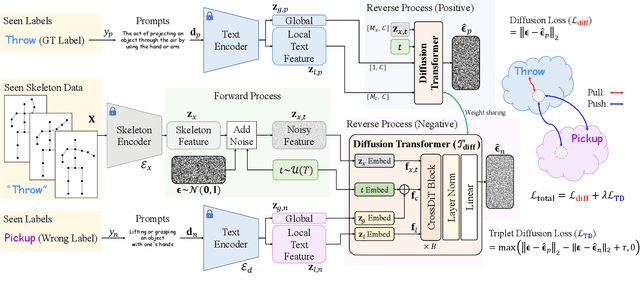
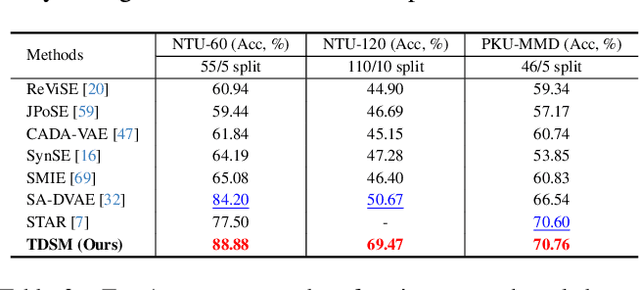
We firstly present a diffusion-based action recognition with zero-shot learning for skeleton inputs. In zero-shot skeleton-based action recognition, aligning skeleton features with the text features of action labels is essential for accurately predicting unseen actions. Previous methods focus on direct alignment between skeleton and text latent spaces, but the modality gaps between these spaces hinder robust generalization learning. Motivated from the remarkable performance of text-to-image diffusion models, we leverage their alignment capabilities between different modalities mostly by focusing on the training process during reverse diffusion rather than using their generative power. Based on this, our framework is designed as a Triplet Diffusion for Skeleton-Text Matching (TDSM) method which aligns skeleton features with text prompts through reverse diffusion, embedding the prompts into the unified skeleton-text latent space to achieve robust matching. To enhance discriminative power, we introduce a novel triplet diffusion (TD) loss that encourages our TDSM to correct skeleton-text matches while pushing apart incorrect ones. Our TDSM significantly outperforms the very recent state-of-the-art methods with large margins of 2.36%-point to 13.05%-point, demonstrating superior accuracy and scalability in zero-shot settings through effective skeleton-text matching.